Please see if you know the answers to four questions concerning the problems described below.
I followed @bgoodri’s suggestion in this post to turn centered parametrization to non-centered parametrization of correlated parameters. This significantly improve the accuracy of the parameter estimates but some problems remain as shown in the pairs plots attached further below.
Both plots show a subset of the parameters, after non-centered reparametrization, of a model incorporating several sigmoid function components (such as inv_logit()) into a basic state-space model of a latent AR(1) process. For example,
- the intercept and slope of the AR(1) process after reparametrization are, respectively, the mean parameters
ab_mu[1]andab_mu[2]shown in the pairs plots below. - Moreover, the
p_mu[1:2]shown in the plots are the mean parameters of the original parametersp[1:2]appearing in the following line that specifies a sigmoid function:
Real = log1p_exp(Z*p) - log1p_exp(Z*p - 1);
where
- the sigmoid function is a relatively smooth version of the soft-clipping function
-
Zis known data of a covariance matrix -
Realis a component forming the discrepancy between the observed and the latent AR(1) process
First pairs plot:

Second pairs plot:
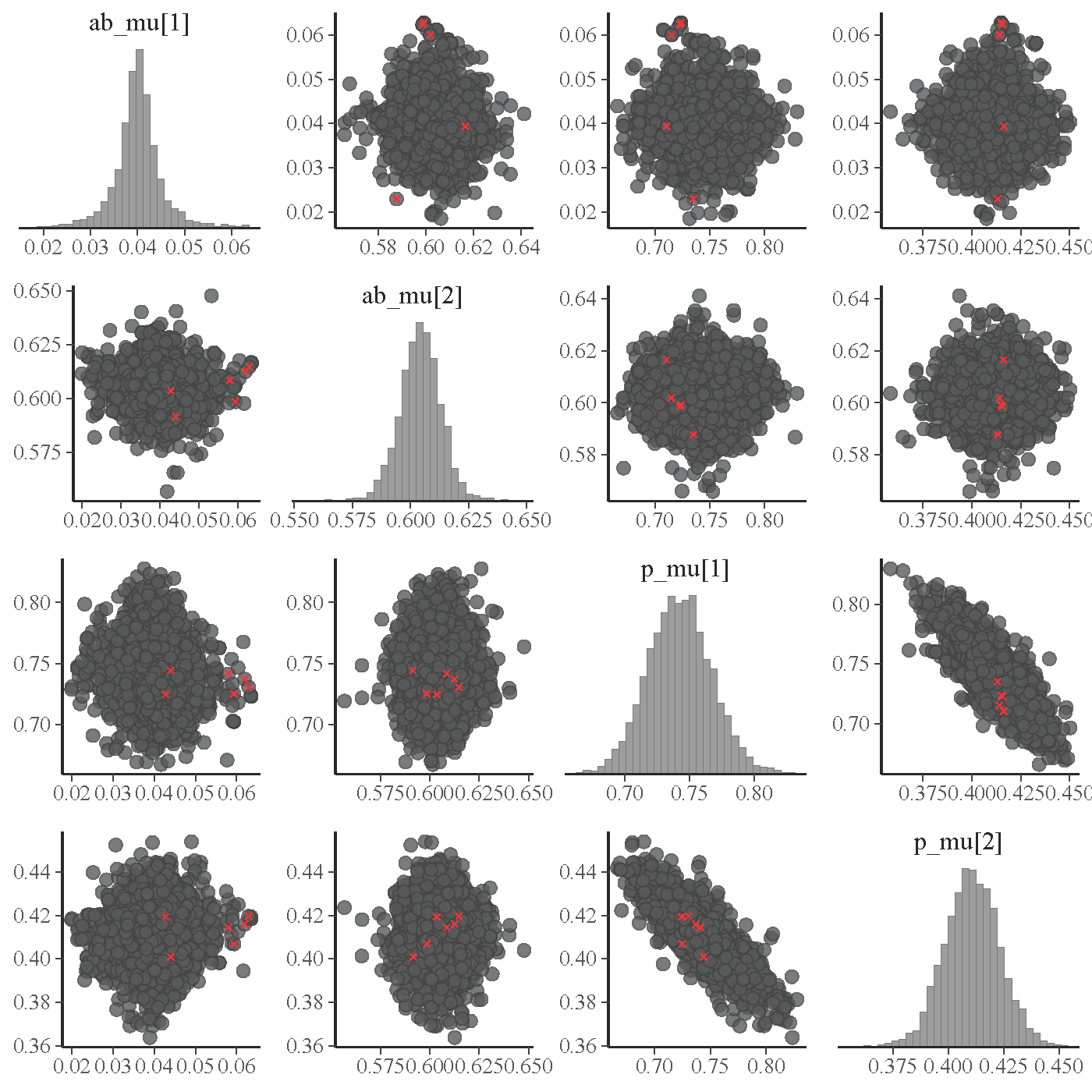
The first pairs plot above, based on 5,000 simulated observation points, shows that even after reparametrization, p_mu[1:2] are still rather highly correlated (although the p_err[1:2] are not and have nice pairs plots with other parameters in the model).
Q1: Is the high correlation between p_mu[1:2] problematic? If yes, what else can be done since they are already from the non-centered reparametrization of the original p[1:2]?
The first pairs plot also shows a distribution of ab_mu[1] with long and very thin tails. A divergent transition also happened in a tail. I guess these thin tails could be the cause of some unreliable estimates despite that the number of simulated observation points in that case was very large (14,000).
I tried some alternatives like specifying a tight prior but couldn’t easily get rid of the thin tails that seem to a cause of the not so accurate estimates. I also tried imposing an explicit constraint in declaring ab_mu[1]. This did not remove the suspected distortion but only resulted in a weird concentration of densities around the explicitly imposed boundaries.
Q2: Is there an effective way to get rid of the distorting thin tails (which actaully look like many extremely small local modes) if I have an intuitive reason to believe that the true parameters cannot be in those thin-tail regions?
The second pairs plot shows that even when the number of simulated observation points increases to 12,000 from 5,000, those issues remained and actually there were more divergent transitions (4 in this case and up to 12 in another occasion).
Q3: I ran 6 chains, 2000 iterations each, 1000 for warmup, so totally 6,000 draws for sampling. Given this, are 12 divergent transitions acceptable or even one is too many? Also, is there a way to obtain the estimates without the influence of the divergent transitions?
Below also shows true parameter values and the table of estimates based on 14,000 simulated observation points. While most of the estimates are rather close to the true values, w[1:2] seem to be still quite far off (underestimated by about 10% of the true values and also outside the 10-90 range). w together with g are already the transformed parameters of a joint non-centered reparametrization of them (so having a single covariance matrix).
Q4: Like p, w is the coefficient vector of a known covariate matrix G, where G*w is the input of an inv_logit() function. Is there anything that can be done to make the estimates of w highly accurate given such a model setup?
Would appreciate very much any advice. Many thanks.
#====================================================
# sd_y = 0.08, mu_u1 = 0.1;
# mu_alpha = 0.04; beta = 0.6; theta = 0.15;
# sd_season = 0.1, mu_season = c(-0.12, -0.06, 0.15);
# p = c(0.72, 0.42)
# g = c(0.85, 0.35)
# w = c(0.72, 0.15, 0.62)
# d = c(0.05, 0.7, 0.25)
#====================================================
observation points of simulated data: 140x100
6 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=6000.
mean se_mean sd 10% 50% 90% n_eff Rhat
sd_y 0.080 0.000 0.000 0.079 0.080 0.080 9126 1.000
mu_u1 0.096 0.000 0.008 0.086 0.096 0.105 9032 1.000
mu_alpha 0.041 0.000 0.001 0.039 0.041 0.042 5983 1.000
beta 0.594 0.000 0.007 0.585 0.594 0.602 4472 1.000
theta 0.146 0.000 0.005 0.140 0.146 0.152 6033 1.000
sd_season 0.097 0.000 0.003 0.093 0.097 0.102 9910 1.000
mu_season[1] -0.112 0.000 0.008 -0.122 -0.112 -0.102 8775 1.000
mu_season[2] -0.060 0.000 0.008 -0.071 -0.060 -0.050 10503 0.999
mu_season[3] 0.148 0.000 0.009 0.137 0.148 0.159 7612 1.000
p[1] 0.697 0.000 0.021 0.671 0.697 0.724 6652 1.000
p[2] 0.434 0.000 0.010 0.421 0.435 0.447 6156 1.000
g[1] 0.870 0.000 0.037 0.823 0.870 0.918 7100 1.000
g[2] 0.367 0.000 0.017 0.346 0.367 0.389 6608 1.000
w[1] 0.801 0.001 0.050 0.737 0.801 0.865 5909 1.001
w[2] 0.135 0.000 0.010 0.123 0.135 0.148 7461 1.001
w[3] 0.623 0.000 0.017 0.601 0.623 0.645 7538 1.000
d[1] 0.061 0.000 0.009 0.049 0.061 0.072 7564 1.000
d[2] 0.688 0.000 0.008 0.678 0.688 0.698 7861 1.000
d[3] 0.251 0.000 0.009 0.239 0.251 0.263 7831 1.000
