This is my second post for Stan ecosystem usage, the first Stan ecosystem metrics which has Scopus.com articles broken down by category over time. This post covers:
Downloads of Stan ecosystem and related packages on the RStudio mirror of CRAN. This only is available for R packages.
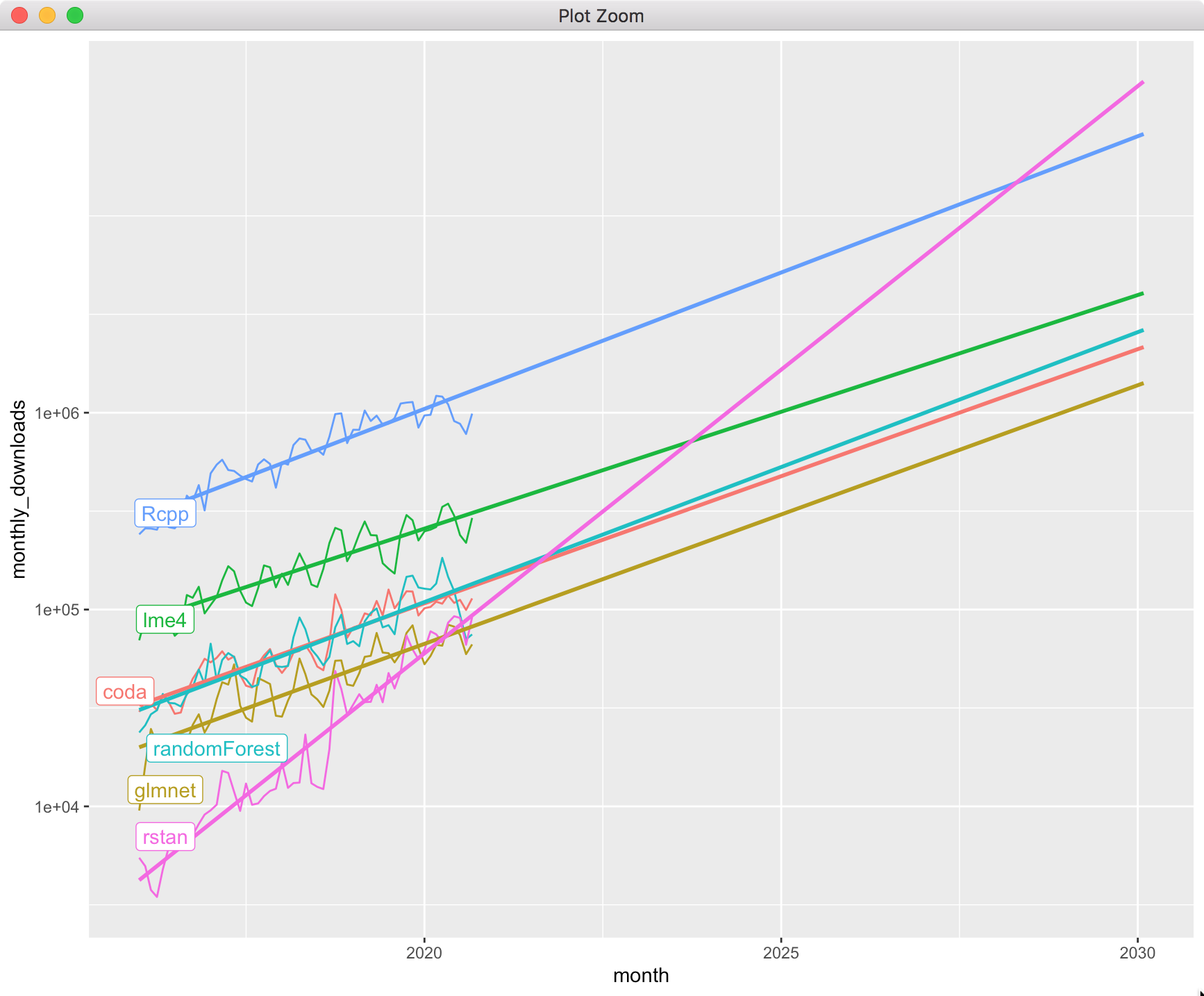
Monthly package downloads from RStudio CRAN mirror on log scale. Packages ggplot2 and Rccp provided as baseline usage rates of R packages. BART, lme4 and tensorflow are not a part of the Stan ecosystem, included for context.
which a pagerank that is 14.55 times the average package
pr["rstan"] / mean(pr) # 14.54949
Most of the packages that are more important than rstan on this metric are utilities, rather than statistics. MASS, survival, mgcv, cluster, nnet, and rpart statistical packages that come with the default installation of R, which means they are broadly useful but have a leg up on all the non-recommended packages. The other packages of note I think are
coda (31st): Has been around a long time but the posterior package should be better
glmnet (36th): A supervised learning package that emphasizes elastic net penalization
lme4 (44th): A package for estimating Frequentist hierarchical models
randomForest (77th): The canonical implementation (in R) of the most popular supervised learning approach these days
I think it is amazing that (R)Stan is essentially as fundamental to Bayesian modeling as randomForest is to supervised learning, but Bayesian modeling has been overtaken (by a lot) by supervised learning approaches during the decade since Stan has been developed.
Gives placements 80, 282, 456, 509, 510, 793, 6526 out of 16119, so other packages are doing quite well, too (projpred being the most specialized of all these packages)
Here the above packages “rstan”,“rstantools”,“bayesplot”,“rstanarm”,“loo”,“shinystan”,“projpred” are in time series. I am happy to share code but it is a bit of a train set–let me know. Loo is running a close second.
Now, I would remove the lines and restrict the time interval to the past. Downloads is a pretty crude metric. I think a pagerank style approach has the advantage of indicating that other developers (most of whom are not at Columbia) choose to build off of RStan.
pagerank is about dependencies, and the number of downloads during last 12 months is quite different (e.g. posterior might be downloaded a lot due to CmdStanR which is not in CRAN)