Dear brms users,
I feel my questions are more general modeling related than specifically to brms, but since I used brms to fit the model, I thought I should post it here, perhaps also to reflect that I am a beginner with bayesian stats and modeling, and relatively bad at using R, and completely illiterate with stan.
That being said, I was wondering if I could get some opinions on setting up a hierarchical model, or keywords I should use for searching to further inform me. I feel like this post has become quite long and apologise for this. Should you frown on the novel I have written below and have suggestions for a different strategy to get help / progress on my own, before embarking on reading it, they are most welcome!
I want to model correlations, which are the result of many performance evaluations of a “machine-learning” (ml) model I built independently from this brms model. It predicts time series, performances ranging between (pearson correlation) .1 and .4.
I guess that ideally, I would implement this initial ml model already in a bayesian framework, however, I feel that a good hierarchical model for model performances of any generic model would be a nice thing to have and a good way for me to step into hierarchical modeling.
I use a nested-cross-validation approach where I train the ml model on a part of the data, validate it on another and test it on a third, and the associations of data portions to train, validate and test sets are circularly permuted, so that I end up with 6 “outer fold” performances (correlations) for each unit and subunit.
So I have performance evaluations for 24 units, each of them having 2 subunits, all of which I am predicting from various “feature spaces”, i.e. sets of predictors. Ultimately, I am interested to what extent these feature spaces differ in terms of the predictive performance achievable with them, which I want to do with a dummy-coded categorical variable indicating the slope from a baseline feature space to a feature space of interest (i.e. I want to compare the “fixed effects” of feature spaces against each other, for which I am basically relying on the brms hypothesis function, yielding evidence ratios in favour of tested hypotheses of interest like “beta_a > beta_b”).
Additionally, I am including random intercepts for the units, random slopes for the feature spaces for each unit and random slopes for all outer folds (an additional categorical predictor), and interactions between subunits and the feature spaces.
I have various questions:
- how bad is it to use family=“gaussian”? Must I Fisher-Z transform my correlations before entering them into the model? Is there a link function that does this? I constrained the betas with lower and upper boundaries of -2 and +2, reflecting the minimal and maximal values they could take for correlations, however, this is not possible for the intercept (i.e. restricting it between -1 and +1), since " currently, boundaries are only allowed for population level and autocorr parameters", which makes me think the whole idea of setting boundaries is a bad one - do you share this view?
- I read in Gelman’s book that in a bayesian model, I don’t have to use a baseline category for my dummy variables but can instead include variables for all feature spaces instead without running into problems of non-identifiability (p.245 and p.393 from book version of 9. August 2006) – did I misunderstand something here? Or is that really the case?
- when I run this model and do posterior predictive checks, I observe that the yreps have values that are higher than the data:

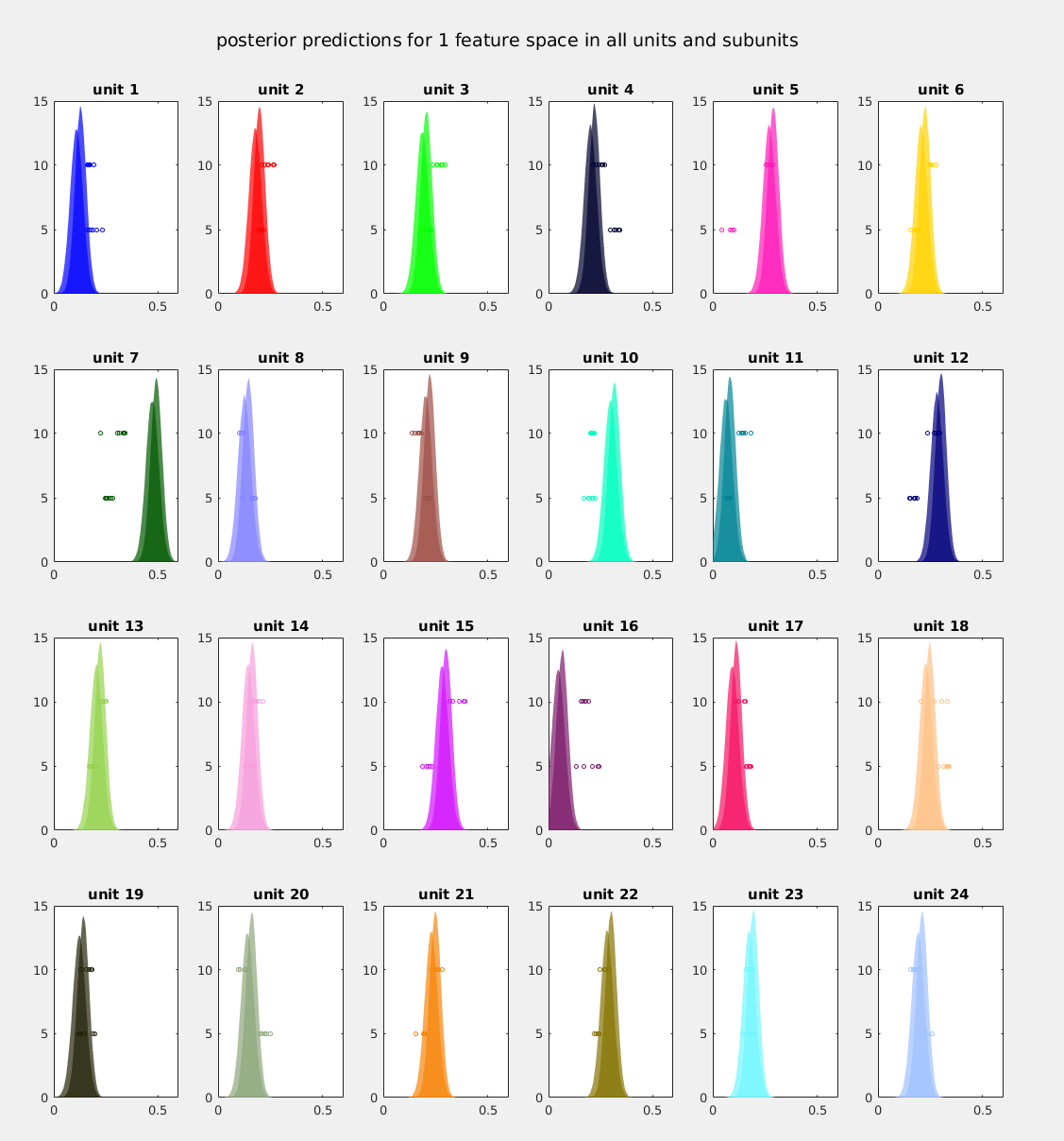
Specifically, I am referring to the bump we can see at ~.5. I extracted some samples from the yreps and looked at the single units, basically finding that the predictions for one single unit are strongly higher than the observed values:
In this plot, each actual data point is plotted as a scatter, the y-value being different for the 2 subunits, and the posterior predictive distributions are plotted as ksdensities, one for each subunit in the same plot. It is easy to see that i) many subunits are off from the observed data and ii) unit 7 is highly overestimated, which happens for all feature spaces and consistently across samples from the posterior predictive.
Is this a degree of disagreement of y and yrep that is unacceptable and points to mistakes in setting up the model? Or is this what people mean when they write “we don’t want to perfectly retrodict the sample”? - The trained eye will see that this was not done in R, but in matlab instead where I am a lot faster in doing data wrangling like this – I believe there must be a simple way to extract posterior predictive samples corresponding to a given unit / subunit / …? If someone could tell me the keyword I should be looking for in bayesplot, I would be very thankful!
- in terms of the model design, before I read into hierarchical modeling, I had the intuition that I should model the units and subunits as different levels; however, I was discouraged from this by prominent helpers, who said that the 2 subunits are not enough to estimate a variance as necessary for “random effects”; then again, I read in the Gelman book (2006) that he thinks it should be fine, or actually in this case not make much of a difference - I would be interested in any further opinions on this!
- finally, of course also I am unsure about the priors – the model ran well with uniform priors (-2 – +2 for the intercept, -1 – +1 for the betas), but this seems to be discouraged; additionally, I could imagine that the default sd priors for the random effects might be a bit too broad? Is it a problem to stick to the default LKJ priors for the correlations?
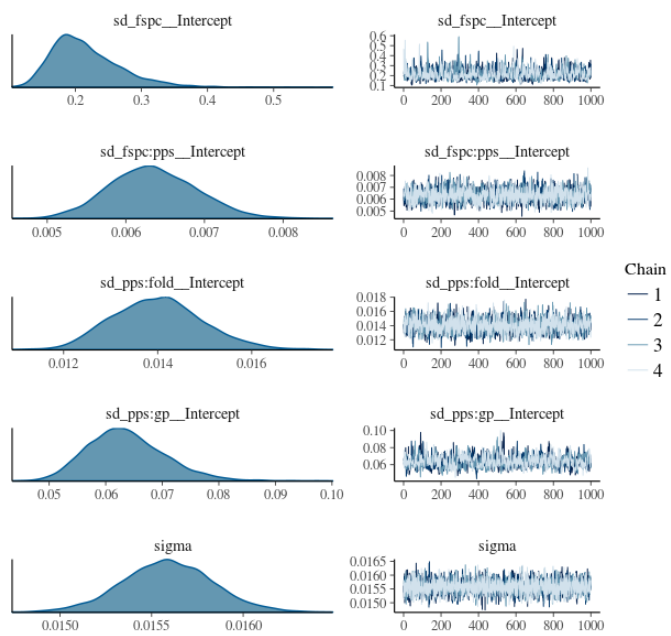
- Operating System: Ubuntu 16.04 LTS
- brms Version: 2.2.0
- model code:
pps: units
gp: subunits
idx_1 – idx_8: dummy variables for feature spaces
f2 – f6: dummy variables of outer folds
brmsModel <- brm(r ~ (1|pps) + # random intercept for all levels
(idx_1-1|pps) + # uncorrelated random slopes for all feature spaces
(idx_2-1|pps) +
(idx_3-1|pps) +
(idx_4-1|pps) +
(idx_5-1|pps) +
(idx_6-1|pps) +
(idx_7-1|pps) +
(idx_8-1|pps) +
(f2-1|pps) + # uncorrelated random slopes for folds
(f3-1|pps) + #
(f4-1|pps) + #
(f5-1|pps) + #
(f6-1|pps) + #
(gp-1|pps) + # uncorrelated random slope for subunit
gp*(idx_1 + idx_2 + idx_3 + idx_4 + idx_5 + idx_6 + idx_7 + idx_8 + f2 + f3 + f4 + f5 + f6), # fixed effects
data = cv8fspc, family = gaussian(),
cores = 4, iter = 5000, chains = 4, warmup = 1000,
prior = c(set_prior(“normal(0.1,10)”, class = “Intercept”),
set_prior(“normal(0.1,10)”, lb = -2, ub = 2, class = “b”)), # ub and lb to reflect boundaries of correlation;
control = list(adapt_delta = .95, max_treedepth = 15))
Any help would be much appreciated!