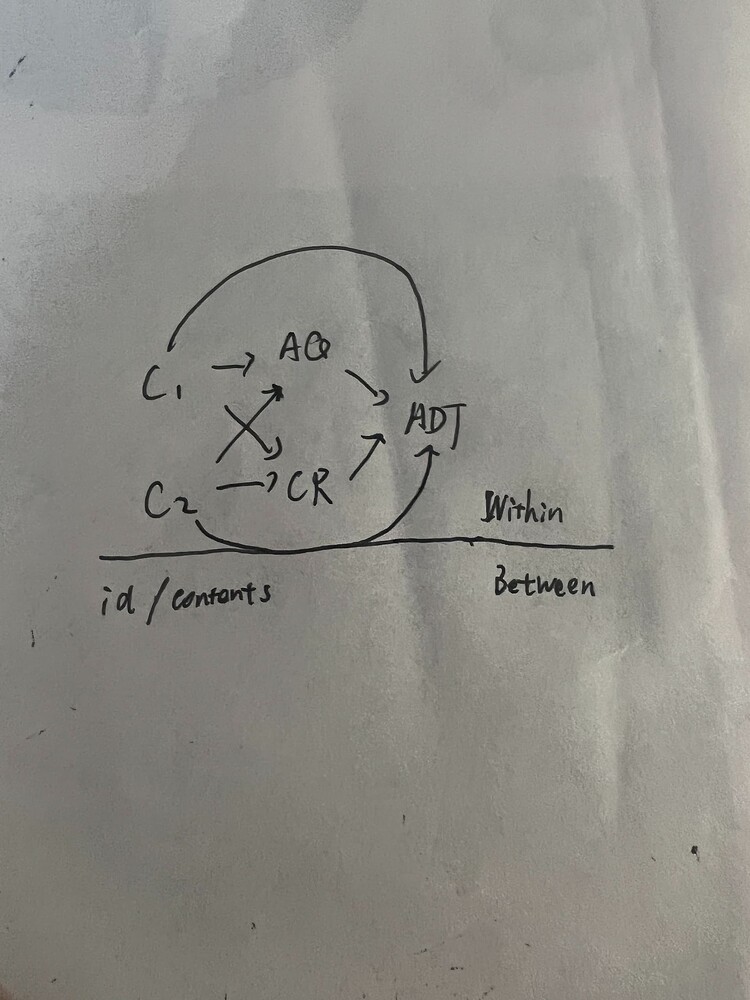
Hello everyone! I’m trying to build a double random factor mediation model using rstan. Initially, I used code with central parameterization from Bayesian Multilevel Mediation | Model Estimation by Example. However, the model fit was poor with low Effective Sample Size (ESS) and issues with Bayesian Fraction of Missing Information (BFMI).
Following expert advice**@andre.pfeuffer**, I switched to non-central parameterization version. With this approach, the model fit well. However, when I added random slopes to this model, all fixed effects became non-significant, which is highly unusual. I’m curious to understand why this is happening!
central parameterization version:
random="data{
int<lower=1> N;
vector[N] c1;
vector[N] c2;
vector[N] aq;
vector[N] cr;
vector[N] adt;
int<lower=1> J;
int<lower=1, upper=J> Group[N];
int<lower=1> G;
int<lower=1, upper=G> Group2[N];
}
parameters{
real alphaaq;
real beta1aq;
real beta2aq;
real<lower=0> sigma_alphaaq;
real<lower=0> sigma_beta1aq;
real<lower=0> sigma_beta2aq;
real<lower=0> sigmaaq;
real alphacr;
real beta1cr;
real beta2cr;
real<lower=0> sigma_alphacr;
real<lower=0> sigma_beta1cr;
real<lower=0> sigma_beta2cr;
real<lower=0> sigmacr;
real alphaadt;
real beta1adt;
real beta2adt;
real beta3adt;
real beta4adt;
real<lower=0> sigma_alphaadt;
real<lower=0> sigma_beta1adt;
real<lower=0> sigma_beta2adt;
real<lower=0> sigma_beta3adt;
real<lower=0> sigma_beta4adt;
real<lower=0> sigma_adt;
cholesky_factor_corr[11] Omega_chol1;
cholesky_factor_corr[11] Omega_chol2;
vector<lower=0>[11] sigma_ranef1;
vector<lower=0>[11] sigma_ranef2;
matrix[J,11] gamma1; # random effects for id
matrix[G,11] gamma2; # random effects for topic
}
transformed parameters{
vector[J] gamma1alphaaq;
vector[J] gamma1beta1aq;
vector[J] gamma1beta2aq;
vector[J] gamma1alphacr;
vector[J] gamma1beta1cr;
vector[J] gamma1beta2cr;
vector[J] gamma1alpha;
vector[J] gamma1beta1;
vector[J] gamma1beta2;
vector[J] gamma1beta3;
vector[J] gamma1beta4;
for (j in 1:J){
gamma1alphaaq[j] = gamma1[j,1];
gamma1beta1aq[j] = gamma1[j,2];
gamma1beta2aq[j] = gamma1[j,3];
gamma1alphacr[j] = gamma1[j,4];
gamma1beta1cr[j] = gamma1[j,5];
gamma1beta2cr[j] = gamma1[j,6];
gamma1alpha[j]= gamma1[j,7];
gamma1beta1[j] = gamma1[j,8];
gamma1beta2[j] = gamma1[j,9];
gamma1beta3[j] = gamma1[j,10];
gamma1beta4[j] = gamma1[j,11];}
vector[G] gamma2alphaaq;
vector[G] gamma2beta1aq;
vector[G] gamma2beta2aq;
vector[G] gamma2alphacr;
vector[G] gamma2beta1cr;
vector[G] gamma2beta2cr;
vector[G] gamma2alpha;
vector[G] gamma2beta1;
vector[G] gamma2beta2;
vector[G] gamma2beta3;
vector[G] gamma2beta4;
for (g in 1:G){
gamma2alphaaq[g] = gamma2[g,1];
gamma2beta1aq[g] = gamma2[g,2];
gamma2beta2aq[g] = gamma2[g,3];
gamma2alphacr[g] = gamma2[g,4];
gamma2beta1cr[g] = gamma2[g,5];
gamma2beta2cr[g] = gamma2[g,6];
gamma2alpha[g]= gamma2[g,7];
gamma2beta1[g] = gamma2[g,8];
gamma2beta2[g] = gamma2[g,9];
gamma2beta3[g] = gamma2[g,10];
gamma2beta4[g] = gamma2[g,11];}
}
model{
vector[N] mu_adt;
vector[N] mu_aq;
vector[N] mu_cr;
matrix[11,11] D1;
matrix[11,11] D2;
matrix[11, 11] DC1;
matrix[11, 11] DC2;
sigma_alphaaq ~ cauchy(0, 1);
sigma_beta1aq ~ cauchy(0, 1);
sigma_beta2aq ~ cauchy(0, 1);
alphaaq ~ normal(0, sigma_alphaaq);
beta1aq ~ normal(0, sigma_beta1aq);
beta2aq ~ normal(0, sigma_beta2aq);
sigmaaq ~ cauchy(0, 1);
sigma_alphacr ~ cauchy(0, 1);
sigma_beta1cr ~ cauchy(0, 1);
sigma_beta2cr ~ cauchy(0, 1);
alphacr ~ normal(0, sigma_alphacr);
beta1cr ~ normal(0, sigma_beta1cr);
beta2cr ~ normal(0, sigma_beta2cr);
sigmacr ~ cauchy(0, 1);
sigma_alphaadt ~ cauchy(0, 1);
sigma_beta1adt ~ cauchy(0, 1);
sigma_beta2adt ~ cauchy(0, 1);
sigma_beta3adt ~ cauchy(0, 1);
sigma_beta4adt ~ cauchy(0, 1);
alphaadt ~ normal(0, sigma_alphaadt);
beta1adt ~ normal(0, sigma_beta1adt);
beta2adt ~ normal(0, sigma_beta2adt);
beta3adt ~ normal(0, sigma_beta3adt);
beta4adt ~ normal(0, sigma_beta4adt);
sigma_adt ~ cauchy(0, 1);
sigma_ranef1 ~ cauchy(0, 1);
sigma_ranef2 ~ cauchy(0, 1);
Omega_chol1 ~ lkj_corr_cholesky(2.0);
Omega_chol2 ~ lkj_corr_cholesky(2.0);
D1 = diag_matrix(sigma_ranef1);
D2 = diag_matrix(sigma_ranef2);
DC1 = D1 * Omega_chol1;
DC2 = D2 * Omega_chol2;
for (j in 1:J) { # loop for Group random effects id
gamma1[j] ~ multi_normal_cholesky(rep_vector(0, 11), DC1);}
for (g in 1:G){ # loop for Group random effects topic
gamma2[g] ~ multi_normal_cholesky(rep_vector(0, 11), DC2);}
for (n in 1:N){
mu_aq[n] = alphaaq + gamma1alphaaq[Group[n]] + gamma2alphaaq[Group2[n]]+
(beta1aq + gamma1beta1aq[Group[n]] + gamma2beta1aq[Group2[n]]) * c1[n] +
(beta2aq + gamma1beta2aq[Group[n]] + gamma2beta2aq[Group2[n]]) * c2[n];
mu_cr[n] = alphacr + gamma1alphacr[Group[n]] + gamma2alphacr[Group2[n]]+
(beta1cr + gamma1beta1cr[Group[n]] + gamma2beta1cr[Group2[n]]) * c1[n] +
(beta2cr + gamma1beta2cr[Group[n]] + gamma2beta2cr[Group2[n]]) * c2[n];
mu_adt[n] = alphaadt + gamma1alpha[Group[n]] + gamma2alpha[Group2[n]]+
(beta1adt + gamma1beta1[Group[n]] + gamma2beta1[Group2[n]]) * c1[n] +
(beta2adt + gamma1beta2[Group[n]] + gamma2beta2[Group2[n]]) * c2[n] +
(beta3adt + gamma1beta3[Group[n]] + gamma2beta3[Group2[n]]) * aq[n] +
(beta4adt + gamma1beta4[Group[n]] + gamma2beta4[Group2[n]]) * cr[n];}
aq ~ normal(mu_aq, sigmaaq);
cr ~ normal(mu_cr, sigmacr);
adt ~ normal(mu_adt, sigma_adt);
}
generated quantities{
real naiveIndEffect1;
real avgIndEffect1_1;
real avgIndEffect1_2;
real naiveIndEffect2;
real avgIndEffect2_1;
real avgIndEffect2_2;
real naiveIndEffect3;
real avgIndEffect3_1;
real avgIndEffect3_2;
real naiveIndEffect4;
real avgIndEffect4_1;
real avgIndEffect4_2;
real totalEffect1_1;
real totalEffect1_2;
matrix[11,11] covMatRE1;
matrix[11,11] covMatRE2;
covMatRE1 = diag_matrix(sigma_ranef1) * tcrossprod(Omega_chol1) * diag_matrix(sigma_ranef1);
covMatRE2 = diag_matrix(sigma_ranef2) * tcrossprod(Omega_chol2) * diag_matrix(sigma_ranef2);
naiveIndEffect1=beta1aq * beta3adt;
avgIndEffect1_1=beta1aq * beta3adt+covMatRE1[2,10];
avgIndEffect1_2=beta1aq * beta3adt+covMatRE2[2,10];
naiveIndEffect2=beta1cr * beta4adt;
avgIndEffect2_1=beta1cr * beta4adt+covMatRE1[5,11];
avgIndEffect2_2=beta1aq * beta4adt+covMatRE2[5,11];
naiveIndEffect3=beta2aq * beta3adt;
avgIndEffect3_1=beta2aq * beta3adt+covMatRE1[3,10];
avgIndEffect3_2=beta2aq * beta3adt+covMatRE2[3,10];
naiveIndEffect4=beta2cr * beta4adt;
avgIndEffect4_1=beta2cr * beta4adt+covMatRE1[6,11];
avgIndEffect4_2=beta2cr * beta4adt+covMatRE2[6,11];
totalEffect1_1 = avgIndEffect1_1+avgIndEffect2_1+
avgIndEffect3_1+avgIndEffect4_1+beta1adt+beta2adt;
totalEffect1_2 =avgIndEffect1_2+avgIndEffect2_2+avgIndEffect3_2+avgIndEffect4_2+
beta1adt+beta2adt;
}
"
non-central parameterization version:
random2="data{
int<lower=1> N;
vector[N] c1;
vector[N] c2;
vector[N] aq;
vector[N] cr;
vector[N] adt;
int<lower=1> J;
int<lower=1, upper=J> Group[N];
int<lower=1> G;
int<lower=1, upper=G> Group2[N];
}
parameters{
real alphaaq;
real beta1aq;
real beta2aq;
real<lower=0> sigma_alphaaq;
real<lower=0> sigma_beta1aq;
real<lower=0> sigma_beta2aq;
real<lower=0> sigmaaq;
real alphacr;
real beta1cr;
real beta2cr;
real<lower=0> sigma_alphacr;
real<lower=0> sigma_beta1cr;
real<lower=0> sigma_beta2cr;
real<lower=0> sigmacr;
real alphaadt;
real beta1adt;
real beta2adt;
real beta3adt;
real beta4adt;
real<lower=0> sigma_alphaadt;
real<lower=0> sigma_beta1adt;
real<lower=0> sigma_beta2adt;
real<lower=0> sigma_beta3adt;
real<lower=0> sigma_beta4adt;
real<lower=0> sigma_adt;
cholesky_factor_corr[11] Omega_chol1;
cholesky_factor_corr[11] Omega_chol2;
vector<lower=0>[11] sigma_ranef1;
vector<lower=0>[11] sigma_ranef2;
matrix[J,11] gamma1_raw;
matrix[G,11] gamma2_raw;
vector[11] mu1;
vector[11] mu2;
}
transformed parameters{
vector[J] gamma1alphaaq;
vector[J] gamma1alphacr;
vector[J] gamma1alpha;
vector[J] gamma1beta1aq;
vector[J] gamma1beta2aq;
vector[J] gamma1beta1cr;
vector[J] gamma1beta2cr;
vector[J] gamma1beta1adt;
vector[J] gamma1beta2adt;
vector[J] gamma1beta3adt;
vector[J] gamma1beta4adt;
vector[G] gamma2alphaaq;
vector[G] gamma2alphacr;
vector[G] gamma2alpha;
vector[G] gamma2beta1aq;
vector[G] gamma2beta2aq;
vector[G] gamma2beta1cr;
vector[G] gamma2beta2cr;
vector[G] gamma2beta1adt;
vector[G] gamma2beta2adt;
vector[G] gamma2beta3adt;
vector[G] gamma2beta4adt;
vector[N] mu_adt;
vector[N] mu_aq;
vector[N] mu_cr;
matrix[J,11] gamma1 = rep_matrix(mu1’, J) + gamma1_raw * diag_pre_multiply(sigma_ranef1, Omega_chol1)‘;
matrix[G,11] gamma2 = rep_matrix(mu2’, G) + gamma2_raw * diag_pre_multiply(sigma_ranef2, Omega_chol2)';
for (j in 1:J){
gamma1alphaaq[j] = gamma1[j,1];
gamma1alphacr[j] = gamma1[j,2];
gamma1alpha[j]= gamma1[j,3];
gamma1beta1aq[j]= gamma1[j,4];
gamma1beta1cr[j]= gamma1[j,5];
gamma1beta1adt[j]= gamma1[j,6];
gamma1beta2aq[j]= gamma1[j,7];
gamma1beta2cr[j]= gamma1[j,8];
gamma1beta2adt[j]= gamma1[j,9];
gamma1beta3adt[j]= gamma1[j,10];
gamma1beta4adt[j]= gamma1[j,11];
}
for (g in 1:G) {
gamma2alphaaq[g] = gamma2[g,1];
gamma2alphacr[g] = gamma2[g,2];
gamma2alpha[g]= gamma2[g,3];
gamma2beta1aq[g]= gamma2[g,4];
gamma2beta1cr[g]= gamma2[g,5];
gamma2beta1adt[g]= gamma2[g,6];
gamma2beta2aq[g]= gamma2[g,7];
gamma2beta2cr[g]= gamma2[g,8];
gamma2beta2adt[g]= gamma2[g,9];
gamma2beta3adt[g]= gamma2[g,10];
gamma2beta4adt[g]= gamma2[g,11];
}
for (n in 1:N) {
mu_aq[n] = alphaaq + gamma1alphaaq[Group[n]] + gamma2alphaaq[Group2[n]]+
(beta1aq+gamma1beta1aq[Group[n]]+gamma2beta1aq[Group2[n]]) * c1[n] +
(beta2aq+gamma1beta2aq[Group[n]]+gamma2beta2aq[Group2[n]]) * c2[n];
mu_cr[n] = alphacr + gamma1alphacr[Group[n]] + gamma2alphacr[Group2[n]]+
(beta1cr+gamma1beta1cr[Group[n]]+gamma2beta1cr[Group2[n]]) * c1[n] +
(beta2cr+gamma1beta2cr[Group[n]]+gamma2beta2cr[Group2[n]]) * c2[n];
mu_adt[n] = alphaadt + gamma1alpha[Group[n]] + gamma2alpha[Group2[n]]+
(beta1adt+gamma1beta1adt[Group[n]]+gamma2beta1adt[Group2[n]]) * c1[n] +
(beta2adt+gamma1beta2adt[Group[n]]+gamma2beta2adt[Group2[n]]) * c2[n] +
(beta3adt+gamma1beta3adt[Group[n]]+gamma2beta4adt[Group2[n]]) * aq[n] +
(beta4adt+gamma1beta4adt[Group[n]]+gamma2beta4adt[Group2[n]]) * cr[n];
}
}
model{
sigma_alphaaq ~ student_t(5, 0, 2);
sigma_beta1aq ~ student_t(5, 0, 2);
sigma_beta2aq ~ student_t(5, 0, 2);
alphaaq ~ normal(0, sigma_alphaaq);
beta1aq ~ normal(0, sigma_beta1aq);
beta2aq ~ normal(0, sigma_beta2aq);
sigmaaq ~ student_t(5, 0, 2);
sigma_alphacr ~ student_t(5, 0, 2);
sigma_beta1cr ~ student_t(5, 0, 2);
sigma_beta2cr ~ student_t(5, 0, 2);
alphacr ~ normal(0, sigma_alphacr);
beta1cr ~ normal(0, sigma_beta1cr);
beta2cr ~ normal(0, sigma_beta2cr);
to_vector(gamma1_raw) ~ normal(0, 1);
to_vector(gamma2_raw) ~ normal(0, 1);
sigmacr ~ student_t(5, 0, 2);
sigma_alphaadt ~ student_t(5, 0, 2);
sigma_beta1adt ~ student_t(5, 0, 2);
sigma_beta2adt ~ student_t(5, 0, 2);
sigma_beta3adt ~ student_t(5, 0, 2);
sigma_beta4adt ~ student_t(5, 0, 2);
alphaadt ~ normal(0, sigma_alphaadt);
beta1adt ~ normal(0, sigma_beta1adt);
beta2adt ~ normal(0, sigma_beta2adt);
beta3adt ~ normal(0, sigma_beta3adt);
beta4adt ~ normal(0, sigma_beta4adt);
sigma_adt ~ student_t(5, 0, 2);
sigma_ranef1 ~ student_t(5, 0, 2);
sigma_ranef2 ~ student_t(5, 0, 2);
Omega_chol1 ~ lkj_corr_cholesky(2.0);
Omega_chol2 ~ lkj_corr_cholesky(2.0);
aq ~ normal(mu_aq, sigmaaq);
cr ~ normal(mu_cr, sigmacr);
adt ~ normal(mu_adt, sigma_adt);
mu1 ~ normal(0, 2);
mu2 ~ normal(0, 2);
}
generated quantities{
real naiveIndEffect1;
real naiveIndEffect2;
real naiveIndEffect3;
real naiveIndEffect4;
naiveIndEffect1=beta1aq * beta3adt;
naiveIndEffect2=beta1cr * beta4adt;
naiveIndEffect3=beta2aq * beta3adt;
naiveIndEffect4=beta2cr * beta4adt;
}
"