I have a few questions about the brms parameterisation, and about how one might go about reparameterising a model with brms.
I’m working on trying to improve performance of a model that I’m working with to avoid funnel geometry of my posterior. I’ve been working through Michael Betancourt’s case study on hierarchical models to understand this better, and learning how, depending on whether the likelihood is minimally or maximally informative, a non-centred or centred parameterisation is optimal (NCP and CP). I’m just having some difficulty understanding the brms parameterisation.
Here I’ve used a toy example model based on another example that I found elsewhere in the forums, where the data is a built-in dataset. But it replicates the behaviour that I’m struggling with in my main model, which is more complicated.
data("Orange")
dat1 <- data.frame(t = Orange$age,
y = Orange$circumference,
group = Orange$Tree)
So, from this post (Disable non-centered parameterization in brms - #7 by paul.buerkner) (and from the brms documentation), I understand that brms, by default, makes use of NCP for nonlinear parameters, and did not previously allow a CP. However, from this more recent post (Non-centered population-level intercept - #5 by paul.buerkner), I understand that brms now supports making use of a centered parameterisation using the lf() command.
So here is the brms code for NCP
# Non-centred
prior1 <- prior(normal(500, 500), nlpar = "beta1")
prior2 <- prior(normal(85, 20), nlpar = "beta2")
prior3 <- prior(normal(170, 5), nlpar = "beta3")
prior4 <- prior(student_t(3, 10, 100), nlpar = "beta1", class="sd")
prior5 <- prior(student_t(3, 15, 100), nlpar = "beta2", class="sd")
prior6 <- prior(student_t(3, 20, 100), nlpar = "beta3", class="sd")
bform <- bf(
y ~ beta1 * inv(1 + exp(-(t - beta2) / beta3)),
beta1 + beta2 + beta3 ~ 1 + (1|group),
nl = TRUE
)
fit1 <- brm(bform, data = dat1, prior = c(prior1, prior2, prior3,
prior4, prior5, prior6),
cores=4)
and here is the brms code for CP
# Centred
prior1 <- prior(normal(500, 500), nlpar = "beta1", class="Intercept")
prior2 <- prior(normal(85, 20), nlpar = "beta2", class="Intercept")
prior3 <- prior(normal(170, 5), nlpar = "beta3", class="Intercept")
prior4 <- prior(student_t(3, 10, 100), nlpar = "beta1", class="sd")
prior5 <- prior(student_t(3, 15, 100), nlpar = "beta2", class="sd")
prior6 <- prior(student_t(3, 20, 100), nlpar = "beta3", class="sd")
bform <- bf(
y ~ beta1 * inv(1 + exp(-(t - beta2) / beta3)),
lf(beta1 + beta2 + beta3 ~ 1 + (1|group), center=TRUE),
nl = TRUE
)
fit2 <- brm(bform, data = dat1, prior = c(prior1, prior2, prior3,
prior4, prior5, prior6),
cores=4)
When comparing the STAN code (which is not my strong suit. I’m learning though…), the differences appear to be minimal, and seemingly inconsequential. I can see how they would differ when there would be several covariates, but in this case, as there is only an intercept, the b values are simply set to the intercept at the end.
So, as I understand, for a CP, we should have theta ~ normal(mu, tau), while for an NCP, we should have theta ~ mu + tau * eta , where eta ~ normal(0 , 1). So, in brms, as far as I understand, eta is represented by z_*, and tau is represented by sd_*. Please do correct me if I’m wrong. But in a CP, I would not have expected to see the z_* values represented here? This seems to be a centred parameterisation of the mean, but not of the SD. Is that correct? And is there a way of doing the full CP?
Here are some of the diffs between the STAN code:

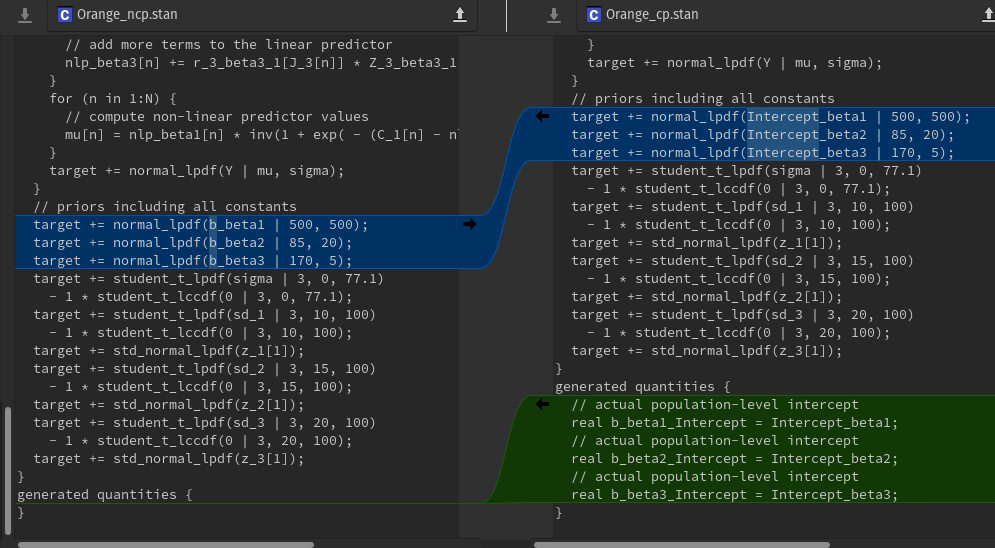
Lastly, if I would like to examine the funnel geometry in eta (or in z_*) in brms, I can’t figure out how to look at it. It doesn’t seem to be in the posterior?
Thanks so much in advance for any help or advice!
brms_parameterisation[rmd2r].R (2.7 KB)
Orange_cp.stan (3.9 KB) Orange_ncp.stan (3.9 KB)