Thank you both @spinkney and @jsocolar for this conversation, I really appreciate both of your recommendations.
1. Current Model (not for help debugging, but for inspiration)
I thought I’d mention the model I’m using right now, since it’s somewhat working:
real masked_l_pdf(vector x, real mu, real sigma, vector nu, real lambda, real sign) {
// https://www.desmos.com/calculator/dmdknl0tnw
// x: is the value pulled from the distribution
// mu: is the location of the normal distribution
// sigma: is the SD of the normal distribution
// nu: is the vector of locations of the sigmoid masks
// lambda: is the steepness of the sigmoid mask (be careful -- sigma and lambda are weakly identifiable)
// sign: is the constant that chooses which side is open (-1 = left open, +1 = right open)
vector[size(x)] log_sigmoid = -log1p_exp(-sign*(x-nu)*lambda);
vector[size(x)] log_normal = -log(sigma)-0.5*square((x-mu)/sigma);
return sum(log_sigmoid + log_normal);
}
This is the log PDF of my sigmoid-masked normal distribution. As you said @jsocolar, it has two parameters that it needs to fit, and very little data with which to do so. At the moment, I’m just setting lambda=10 (high steepness), so it’s only trying to fit nu, the position parameter. Here’s how I do that:
model {
mu ~ normal(0,1); // Weakly informative prior
sigma ~ normal(1,1); // Weakly informative prior
beta ~ normal(0,3); // Uninformative prior
vector[nBird] nu = beta*behavior; // Regression occurs here
target += masked_l_pdf(
pitch,
mu,
sigma,
nu[pitch_bird],
lambda/sigma, // Divide by sigma so that steepness is sigma-invariant
-1.0 // Left-open sigmoid
);
}
The issue with this model—and I’m not sure how much of an issue this is—is that it takes all of the data without any form of multilevel structuring. This means that I have ~260 individual pitch measurements (unevenly distributed over 36 birds) to fit the “tail” of this distribution. I put “tail” in quotes because there isn’t just 1 tail, it’s actually a moving tail based on the value of the behavior. In this model, beta is underestimated (but its sign is correctly retrodicted), but mu and sigma are properly retrodicted.
To make this multilevel, I tried this instead:
parameters {
real mu;
real<lower=0> sigma;
vector[nBird] nu;
real beta;
real<lower=0> error;
}
model {
// Fit the masked normal for each bird
mu ~ normal(0,1); // Weakly informative prior
sigma ~ normal(1,1); // Weakly informative prior
target += masked_l_pdf(
pitch,
mu,
sigma,
nu[pitch_bird],
lambda/sigma, // To put steepness in standard units
-1.0
);
// Fit the regression on behavior by nu
beta ~ normal(0,3); // Uninformative prior
error ~ normal(1,1); // Weakly informative prior
nu ~ normal(beta*behavior, error); // Do the regression
}
Here, nu is fit for each bird, and then I directly do the regression on nu by behavior. This makes more sense, but suddenly I have much less data (at most 20 points, but often closer to 5-10) to fit the tail for each bird (yikes!). Add to this the underestimation in beta from my first model, and this model completely fails to retrodict beta.
Questions: How much of an issue is my first model, without a multilevel structure? I go back on forth on this. Clearly it isn’t great, but is it as indefensible as e.g. doing a straight linear regression on pitch by behavior value? Is there an argument to be made about using the data we have as effectively as possible (i.e. we can always make a model more mechanistic and “accurate” than the last one but there is not enough data in the world to fit effectively, therefore at some point we have to make a trade-off between a “good” model and one that actually informs us about the world)? If I were to use this non-multilevel model, how bad would that actually be? I’m open to hearing “no, don’t do this”—I want to do good, defensible statistics to understand the world better. But I’d also like to build a model that my data can actually fit.
2. Two Truncated Normal Models
I liked the idea of an unknown truncation approach recommended by @spinkney. I would be very curious to see if a high-steepness (i.e. lambda=50 as a constant not a parameter) sigmoid-masked normal would be a better fit than a truncated normal, since that fits better with the physiological mechanism (the birds are attempting to sing higher, but are physiologically limited by a logistic-type mask)—or maybe these would be functionally identical, I’m not sure.
This high-steepness model would be the multilevel model from above, just with a lambda much higher than I was anticipating using. It fails to retrodict beta, but happily retrodicts mu and sigma.
Here’s my implementation of the multilevel truncated normal model @spinkney described. I’m not quite sure I understood everything you said, so I’ve kept it relatively simple at the moment with a bird-level truncation and a regression on truncation-point and behavior, and a constant mu and sigma shared between all birds.
parameters {
real mu;
real<lower=0> sigma;
vector<lower=max_pitch>[nBird] upsilon; // max_pitch is an nBird-length vector from data
real beta;
real<lower=0> error;
}
model {
// Fit the truncated normal for each bird
mu ~ normal(0,1); // Weakly informative prior
sigma ~ normal(1,1); // Weakly informative prior
for (i in 1:nPitch) { // I'm not sure if I can just do pitch ~ normal(mu, sigma) T[,upsilon[pitch_bird]]?
pitch[i] ~ normal(mu, sigma) T[,upsilon[pitch_bird[i]]];
}
// Fit the regression on behavior by upsilon
beta ~ normal(0,2); // Weakly informative prior (not sure how to do this properly)
error ~ normal(1,1); // Weakly informative prior
upsilon ~ normal(beta*behavior, error); // Do the regression
}
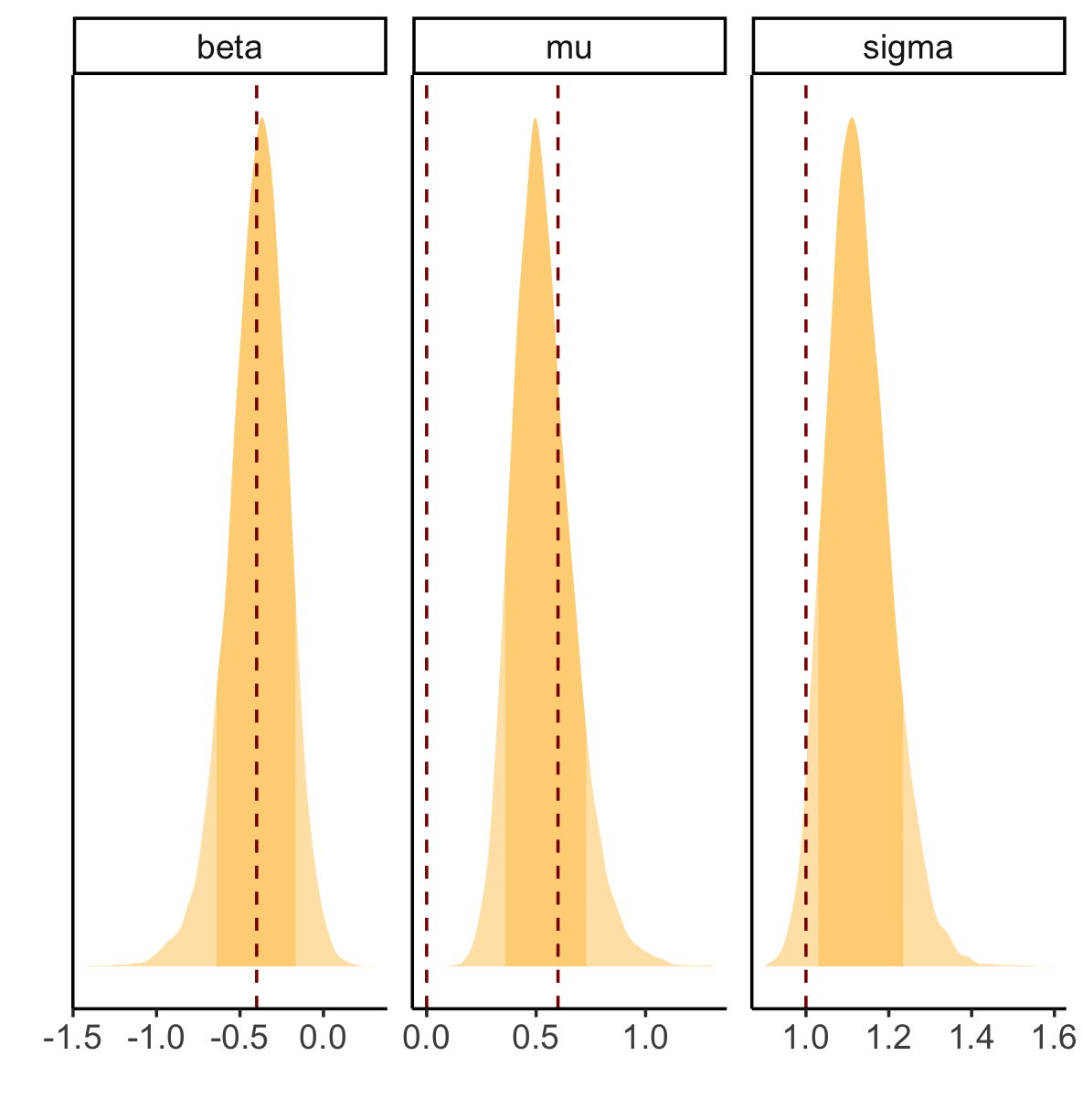
This does a much better job of retrodicting beta, but struggles with mu and sigma:
This is using the same data I used for the previous models (i.e., generated from a sigmoid-masked normal with
mu=0,
sigma=1,
lambda=10, and
nu for each bird being a linear relationship of
beta_behavior=-0.4, and
beta0=0.6. The red lines are
beta_behavior for
beta,
beta0-mu and
mu for
mu (I wasn’t sure what was the right choice for mu here), and
sigma for
sigma.
Questions: @spinkney does this look like the model you were picturing in your comment?
3. Quantile Approach
Based on my understanding of @jsocolar’s comment, I don’t think I have enough data to even attempt a quantile-based approach. For some birds I have but a single data point (unfortunately, it was really, really hard to get good recordings of these birds in the field), so I’m not sure any quantile (except median) would be a real value for every bird. Am I understanding your comment correctly?
Thank you again both for your thoughts on this slightly strange model I’m trying to build. I really, really appreciate all of your help with this!!