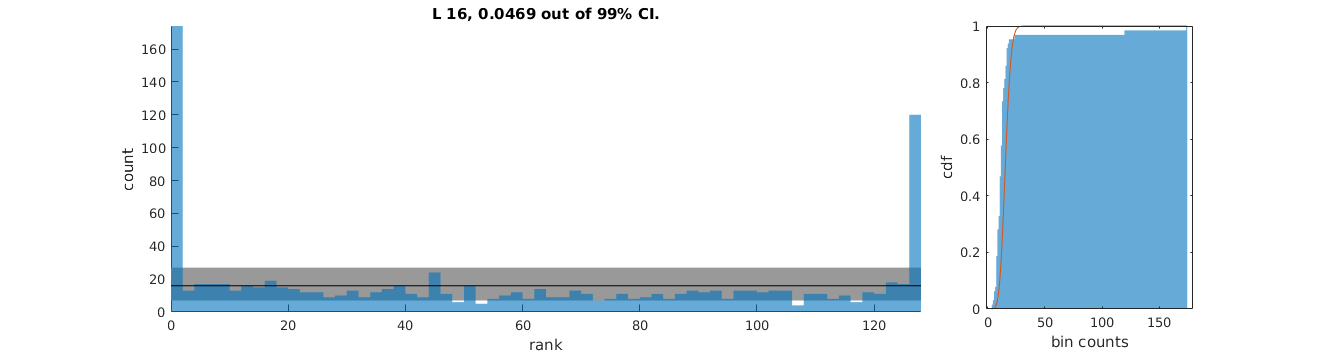
Hello Stan Community,
I have been attempting to fit a reduced-rank regression model with Stan. Briefly, reduced-rank regression takes the multivariate regression Y=XB+e with p predictors (in X) and q outcomes (in Y), and decomposes the p-by-q coefficient matrix B as B = UV', with U being p-by-k and V being q-by-k, where k < min(p, q).
This general form introduces a couple of complications, in that different U and V can result in identical likelihoods. More specifically, flipping the sign on both U and V and permuting the columns of U and V produce equivalent models.
I have managed to get a model where k=1 to work to my satisfaction [it recovers parameters of simulated data and produces interpretable results on real data] by using a transformed parameter that forces the signed sum of squares of V to be positive. It would be simpler to constrain just one entry of V to be positive, but I have no good reason to expect a particular value of V to be positive, and with the data I have so far, none of the posterior distributions of the entries in V are far enough from zero to not fold some non-trivial part of the tail over the zero line.
functions {
int sign(real x) {
if (x == 0)
return 0;
else if (x < 0)
return -1;
else
return 1;
}
}
data {
int N; //number of rows
int P; //number of predictors
int C; //number of outcomes
real<lower=0> sig; //sigma of prior t
real<lower=1> nuf; //nu of priors on coefficients
matrix[N, C] y; //outcome
matrix[N, P] X; //design matrix
}
parameters {
real<lower=1> nu; //nu of noise student t distribution
vector[P] urU;
vector[C] urV;
vector<lower=0>[C] sigma;
}
transformed parameters {
vector[P] U;
vector[C] V;
{ //scope hider
//point V in a positive direction
real s;
real sgn;
s = 0;
for (i in 1:C) {
s += sign(urV[i])*urV[i]^2;
}
sgn = sign(s);
for (i in 1:C)
V[i] = urV[i] * sgn;
for (j in 1:P)
U[j] = urU[j] * sgn;
} // end scope hider
}
model {
nu ~ gamma(2, 0.1);
sigma ~ cauchy(0, 1);
urU ~ student_t(nuf, 0, sig);
urV ~ student_t(nuf, 0, sig);
{
matrix[N,C] mu;
mu = X*U*V';
for (j in 1:C)
y[:,j] ~ student_t(nu, mu[:,j], sigma[j]);
}
}
Anyway, things really fall apart when k>1. I suspect it is because of the column-ordering issue, but there may be some additional problem that I am missing. I have tried introducing a k by k diagonal matrix S (i.e. Y=XUSV') with the diagonal entries constrained to be positive and ordered, but that hasn’t really helped. A while ago I looked at orthogonalizing the columns of U with the Gram-Schmidt process, but I have learned a lot about Stan since then, so I should perhaps revisit that idea. Here is the Stan model for k>1 (that doesn’t really work and doesn’t use the ordered S). Apologies for changing variable names, here Y=XBA'+e, and B and A have qstar columns.
functions {
int sign(real x) {
if (x == 0)
return 0;
else if (x < 0)
return -1;
else
return 1;
}
}
data {
int N; //number of rows
int P; //number of predictors
int<lower=2> C; //number of outcomes
int<upper=min(C,P)> qstar; //ceiling on rank
matrix[N, C] y; //outcome
matrix[N, P] X; //design matrix
}
parameters {
matrix[P, qstar] B0;
matrix[C, qstar] A0;
vector<lower=0>[C] sigma;
matrix<lower=0>[P, qstar] lam;
positive_ordered[qstar] tau;
real<lower=0> nu;
}
transformed parameters {
matrix[P, qstar] B;
matrix[C, qstar] A;
for (j in 1:P) {
for (h in 1:qstar) {
B[j,h] = B0[j,h]*lam[j,h]*tau[h];
}
}
A = A0;
//point A in a generally positive direction
for (c in 1:qstar) {
real ss = 0;
for (r in 1:C)
ss += sign(A[r, c])*A[r, c]*A[r, c];
A[:,c] = A[:,c]*sign(ss);
B[:,c] = B[:,c]*sign(ss);
}
}
model {
matrix[N, C] mu;
nu ~ gamma(2, 0.1);
sigma ~ cauchy(0, 1); // different from reference paper
to_vector(A0) ~ normal(0, 1);
to_vector(B0) ~ normal(0, 1);
to_vector(lam) ~ cauchy(0, 1);
tau ~ cauchy(0, 1);
mu = X*B*A';
for (i in 1:C)
y[:,i] ~ student_t(nu, mu[:,i], sigma[i]);
}
As a rank newbie to Stan (and Bayesian modelling in general), I would appreciate any help figuring out how to get something like rank-reduced regression working. I know there are a lot of similar approaches with different names, but in the papers I have found describing related methods, I get lost before I understand how the sign and column permutation problems get solved.
I’d also welcome any general tips or advice on my models. Thanks!