I am currently trying to use projpred as a variable selection tool and ran into some problems/questions.
The reference model is a mixed model with repeated measurements nested in persons (fit in brms) for which I would like to select relevant covariates.
A reoccurring theme in the ranking of the variables is that the random intercept is selected first. What usually follows are level-1 covariates, while level-2 covariates are always ranked last. I wonder if projpred considers that between-level covariates may explain some of the variance in the random intercept without changing the prediction of the within-level covariates.
To circumvent this, I delayed the inclusion of the random intercept term with the search_terms argument. Is this the correct approach for my problem? The results are more in line with the theoretically expected covariate ranking and some of the level-2 covariates are now allowed to explain some of the variance:
In addition, I get the following warning when using cv_varsel:
1: In cv_varsel.refmodel(ref_model, search_terms = s_terms, cv_method = “loo”, :
K provided, but cv_method is LOO.
2: Some Pareto k diagnostic values are too high. See help(‘pareto-k-diagnostic’) for details.
Is there a way to call the pareto k diagnostic from the cv_varsel output? I have read the associated FAQs and help pages, but I’m not sure how to solve this problem. Is building a better reference model the only way to achieve lower pareto k values? Can the results still be interpreted if the warning remains (varsel and cv_varsel look similar)?
I would like to include autoregressive effects in the reference model. As far as I can tell this is not implemented in projpred. Is this a planned feature?
Search terms can be indeed used for your purpose and it seems to work very well. I’ll explain myself. It seems that the random intercept in your model can soak the whole variance of the outcome, which is common as the random intercept represents each individual. This is a common issue in the sense that projpred does not directly project the posterior distribution but rather focus on the predictive distribution, which may lead to this type of situations.
When forcing the random intercept to be included last you get some sensible behaviour that seems to be in line with your expectations. The warning you are getting is product of a legacy bug and is fixed in the latest develop branch, but is not an issue.
As for the individual Pareto k, we are not storing that for now, but you should be able to recover it by running loo(reference_fit), as the PSIS is run on the reference model.
We haven’t really thought about autoregressive features for now, but feel free to open an issue in projpred’s issue tracker with a bit more details so we can gauge its implications!
Thanks for your interest in using projpred, I hope my answer helps you!
Thank you for your immediate and helpful response! I have a few follow-up questions if you do not mind.
Using suggest_size on the resulting object does not work anymore due to the delay of the random intercept. It now suggests including all covariates. Is there a workaround for this problem?
Can you tell me something about the interpretability of the cv_varsel output given the Pareto k diagnostic warning? The reference model has one k value between .7 and 1. 99% falls into the good category. What does this entail for the covariate selection?
We haven’t really thought about autoregressive features for now, but feel free to open an issue in projpred’s issue tracker with a bit more details so we can gauge its implications!
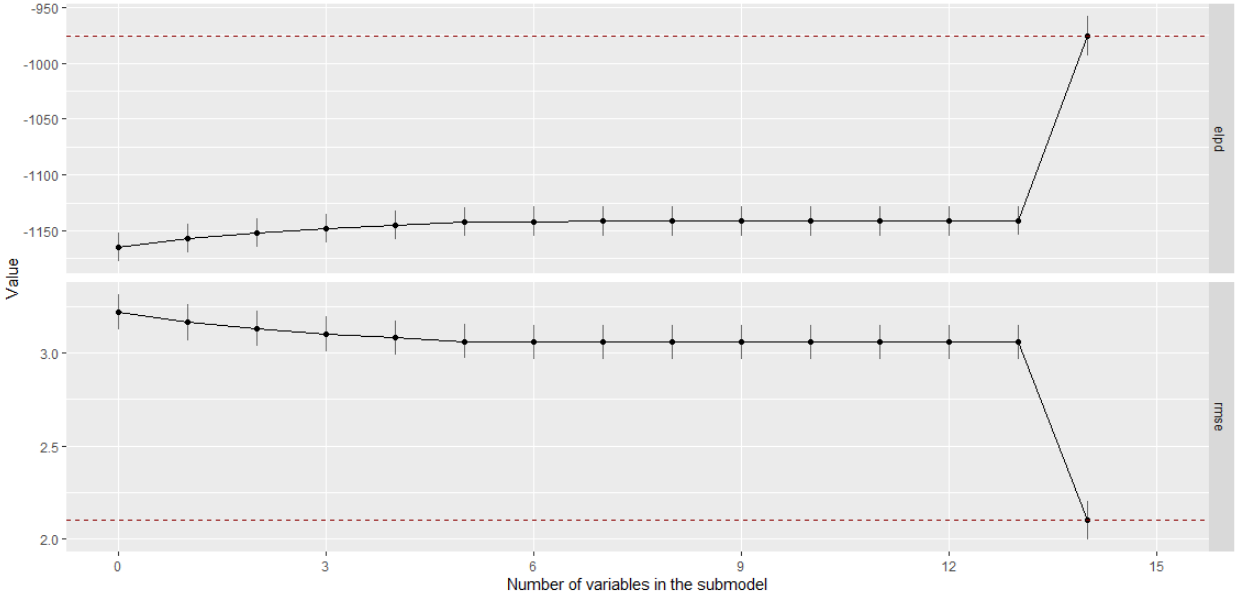
I need to know a bit more about this. Can you show the summary of the varsel object? Possibly the projections are not reaching the reference performance, you can improve the accuracy of the projections by increasing ndraws_pred = 400 or larger. Beware though, this increases the computational cost!
Pareto k indicates how reliable our estimates are with respect to individual observations. In this case it seems that there is only one problematic observation. In practice that may not be too bad, but we don’t really know as that depends a lot on the model. We always encourage users to work the reference model to the point where diagnostics are okay, maybe a stronger prior helps in this, as much as that can be reasonable for your data. Most likely the selection will still work alright with only one bad Pareto k.
This is expected as you are manually restricting the order in which the projection explores submodels. That’s okay. You can see that most of the fixed effects do not significantly contribute to the predictive improvement. suggest_size does not take that into account just yet, but you can very easily check which covariates add, according to the plot I would say that up to 5 fixed effects (plus the intercept) plus the random intercept would be optimal.