- Operating System: Windows 10
- brms Version: 2.9.0
Dear all,
Problem:
-
I performed a series of Bayesian MLM analyses on difference scores using
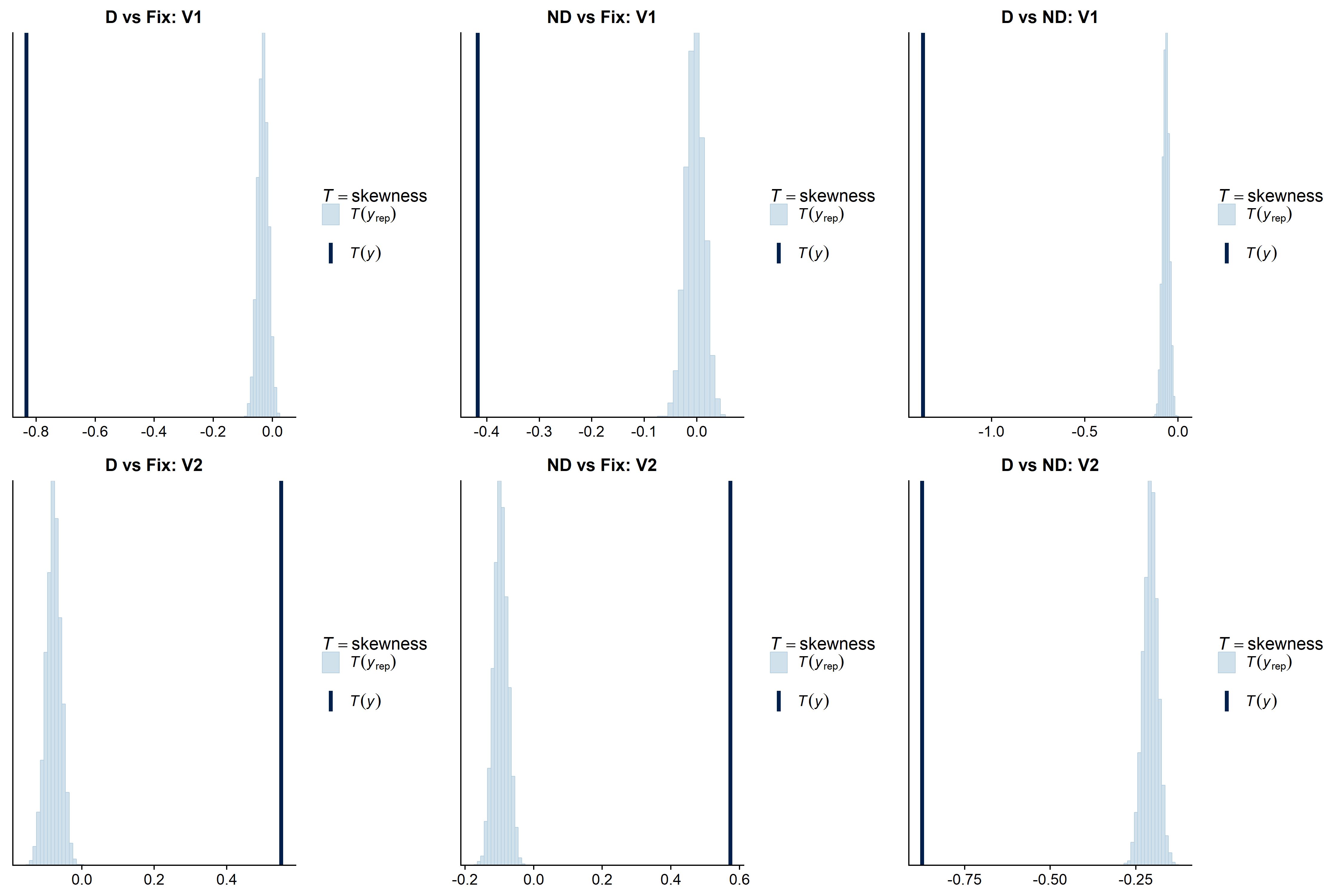
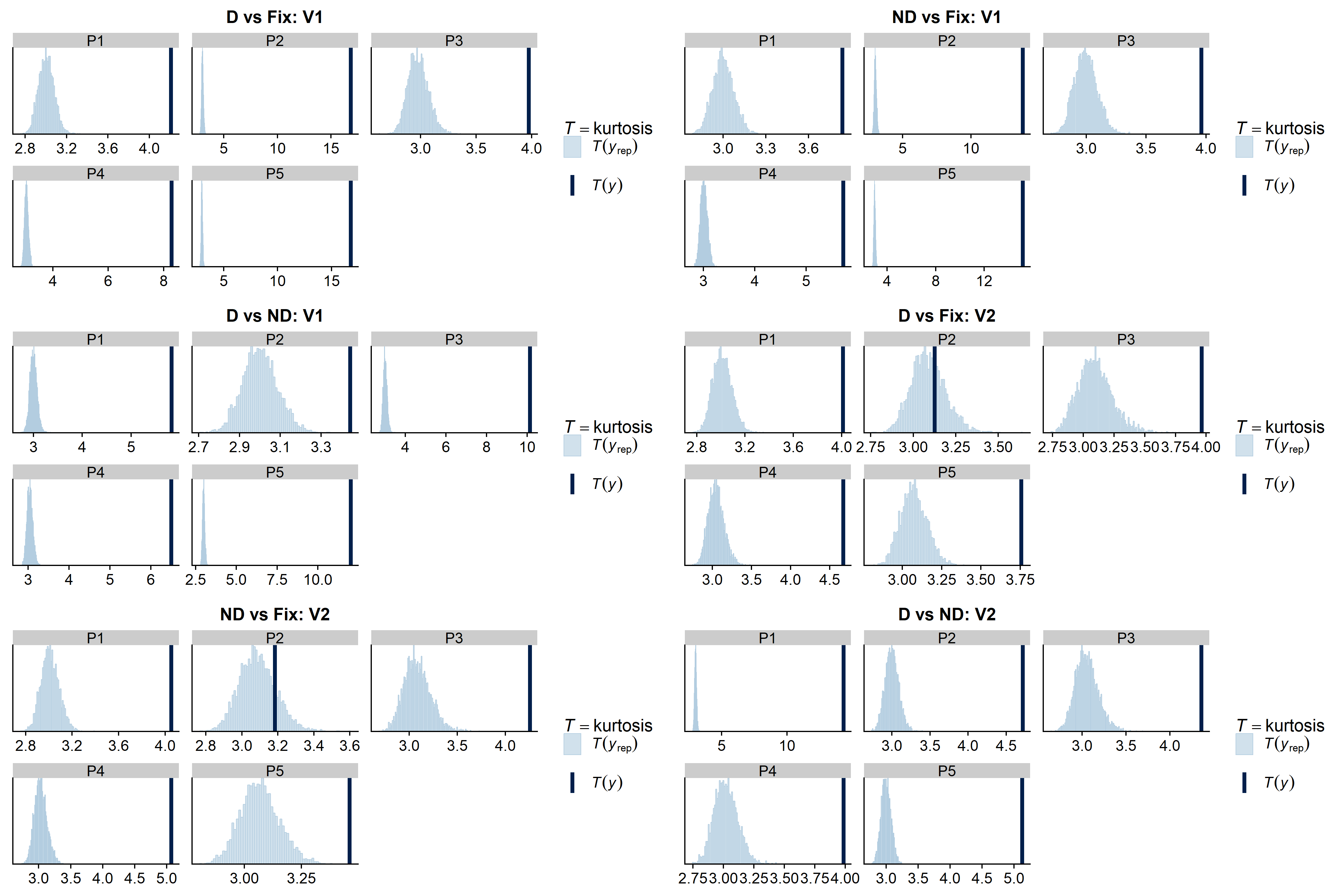
brms.I evaluated my models using posterior predictive checks viapp_check(), indicating kurtosis and skew in my data, both of which not captured by my models. -
My first impression is that this discrepancy could be potentially tackled by changing the family from Gaussian to sth like (skewed) hyperbolic secant. I might be wrong though.
Questions:
- What is your take on this?
- How would you tackle these discrepancies?
Posterior predictive checks:

General model details + context:
Family: gaussian
Links: mu = identity; sigma = identity
Formula: BetaDiff ~ 0 + intercept + VisROI + (1 + VisROI | ID)
Data: Data[Data$Contrasts == CurrContrast & Data$Area == (Number of observations: 20381)
Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup samples = 4000
- BetaDiff: Differential brain activity
- VisROI: Visual field region of interest (i.e. a particular subregion of the visual field); categorical with 4 levels: segments, corners, background, center; dummy-coded with “segments” as a reference category
- ID: Participant ID with 5 levels corresponding to 5 human observers
- The number of data points for each observer per level of VisROI is at minimum 10 but can be as much as ~3600
- The above model specs were used to fit 6 models, one for each contrast of interest (i.e. D vs Fix, ND vs Fix, D vs ND) and brain area (i.e., V1, V2). D and ND reflect different precepts of a visual stimulus and Fix is a fixation baseline where the stimulus was not presented
Priors
> prior_summary(ListFits$ListModels$Segments$`D vs Fix`$V1)
prior class coef group resp dpar nlpar bound
1 b
2 normal( 0,7) b intercept
3 normal( 0,7) b VisROIBackground
4 normal( 0,7) b VisROICenter
5 normal( 0,7) b VisROICorners
6 lkj_corr_cholesky(4) L
7 L ID
8 normal(0, 5) sd
9 sd ID
10 sd Intercept ID
11 sd VisROIBackground ID
12 sd VisROICenter ID
13 sd VisROICorners ID
14 normal(0, 5) sigma
> prior_summary(ListFits$ListModels$Segments$`D vs ND`$V1)
prior class coef group resp dpar nlpar bound
1 b
2 normal( 0,3) b intercept
3 normal( 0,3) b VisROIBackground
4 normal( 0,3) b VisROICenter
5 normal( 0,3) b VisROICorners
6 lkj_corr_cholesky(4) L
7 L ID
8 normal(0, 5) sd
9 sd ID
10 sd Intercept ID
11 sd VisROIBackground ID
12 sd VisROICenter ID
13 sd VisROICorners ID
14 normal(0, 5) sigma
- The priors for V2 were as for V1 and the priors for ND vs Fix as for D vs Fix
- Given that I have only 5 subjects per model, I tightened the default priors on the group-level standard deviations and correlations quite a bit. Please do also note that I ran into problems of divergent transitions with the defaults.
Many thanks in advance for your help!