I screwed up autodiff on the sliced arguments. I was scared about what would happen if all the vars in the sliced arguments had the same vari, so I just didn’t implement that.
I broke the things into two functions – parallel_sum_var and parallel_sum. I think we need enable_if logic or something to distinguish between these things properly.
This should allow for Stan arguments real, int, real[], int[], vector, row_vector, matrix to be passed as the shared arguments. I think we can generalize to get arrays of arrays of whatever without too much trouble, but given I’m not actually testing much of any of that, I didn’t want to push the features yet.
It would require changes to deep_copy/count/accumulate_adjoints/save_varis.
We need to go through this and think out the references/forwarding stuff. I’ve forgotten how && works and if we need it. I wasn’t strictly being const correct when I coded this as first and it led to memory problems cause the deep copy wasn’t actually copying, so gotta be careful with that stuff I guess.
Whow! This looks really cool already… but it doesn’t compile for me at the moment and there are some things which need to change. Not sure where its best to comment, let’s try here.
First, when the reducers do a split, then the partial sums need to be set to 0 for the newly created reducer
The final return type should be return_type_t<M, Args...>; … so it must include M
The first argument which is being sliced also needs to be allowed to be a var, so it must move into the start_nested thing and we have to create deep copies from that as well.
I think it would be more efficient to create value-only representations first from all inputs. Right now we loop over the input stuff every time whereas converting things to only values for everything first leaves us with blocks of memory (for the data arguments we can be efficient and use references). Maybe this can be remedied at a later time if its design wise not straightforward.
What really does not seem to work is the count_elems and save_varis functions. I see how these are supposed to work, but what - I think - is missing is to “peel” off arguments from the args... whenever we actually do count/do stuff. Right now this logic leads to ambiguous calls for the compiler.
My guess is that you haven’t run the tests with parallelism… so always do STAN_NUM_THREADS=4 ./runTests.py .... to run the tests with 4 cores.
I created a small performance test here. I also verified that this one is detecting changes which I know did speed up my original stuff. I am a huge fan of checking my work for speed on the go, the microbenchmark should make that easy.
The count_var and save_varis also need to apply to the first argument which we slice. It will be much more efficient if users slice over larger vectors of vars in the first argument rather than putting data there. So allowing vars there is really important from a performance perspective.
We should merge in the latest from develop to also have prim flattened for the types.
Otherwise, it would be great to get the unit test working again. Right now it does not compile due to the args not being peeled off right, I think… and this apply stuff seems to be very easy for you, so I let you sort it out.
We should probably just continue developing on the cleanup branch. No need to merge back.
Thanks a lot! This is massive progress.
EDIT: Ah… no I see how you peel of arguments. That’s tricky. However, it does not compile for me at the moment. Anyway, there is one thing which is currently not correctly implemented: Whenever we have a std::vector of some type T, then the number of varis are not the size of the vector. Rather we have to loop over the vector to find out about the how many varis each element of the vector has, since each element is allowed to have structure itself.
EDIT2: We can definetly discuss on the WIP PR… but maybe we disable the testing pipeline there.
Just a little note - the thread became quite long and involved, which may discourage people not already involved with the issue from reading through it and thus prevent them from providing feedback. This is OK, while you are prototyping (which I believe you are), but is potentially problematic once this becomes an official proposal to be included in Stan. So if you didn’t plan to do so already, please do start another thread once the dust settles, so that more people actually provide fedback on the proposal.
Good luck - the work seems cool and possibly very useful!
You are not allowed to make any assumptions on how the slicing will occur - this is under the control of the TBB scheduler (depends on the grain size and the partitioner used).
BTW, I thought that we can define the reduce_sum for anything which does not match our specialisations (so anything other than a double or a var) simply as
With this definition as base case we can then go ahead and take advantage of the ad testing framework. At least this was my thinking to get testing done in a convenient way.
Thanks. The first prototype is basically done and now it’s about C++ engineering. People who want to contribute should go to the WIP PR which we have now I guess. I tried to make a wiki page, but that one is already outdated to quite some extend.
Things are moving here quickly. Since @bbbales2, @stevebronder and myself are on this, I don’t think that we need a bigger group of people driving this, I think… and anyone who wants to join is welcome to.
I pulled a copy of the proto-parallel-v3 branch and the same thing is happening to me there.
Ubuntu 18.04, clang 6.0.0, output looks like:
bbales2@frog:~/math-tbb2$ git branch
develop
* proto-parallel-v3
bbales2@frog:~/math-tbb2$ STAN_NUM_THREADS=4 ./runTests.py test/unit/math/rev/functor/parallel_v3_reduce_sum_test.cpp
------------------------------------------------------------
make -j1 test/unit/math/rev/functor/parallel_v3_reduce_sum_test
make: 'test/unit/math/rev/functor/parallel_v3_reduce_sum_test' is up to date.
------------------------------------------------------------
test/unit/math/rev/functor/parallel_v3_reduce_sum_test --gtest_output="xml:test/unit/math/rev/functor/parallel_v3_reduce_sum_test.xml"
Running main() from lib/gtest_1.8.1/src/gtest_main.cc
[==========] Running 6 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 6 tests from v3_reduce_sum
[ RUN ] v3_reduce_sum.value
ref value of poisson lpdf : -2.70508e+08
value of poisson lpdf : -2.70508e+08
[ OK ] v3_reduce_sum.value (2 ms)
[ RUN ] v3_reduce_sum.gradient
Segmentation fault (core dumped)
test/unit/math/rev/functor/parallel_v3_reduce_sum_test --gtest_output="xml:test/unit/math/rev/functor/parallel_v3_reduce_sum_test.xml" failed
exit now (01/15/20 10:18:40 EST)
We also need an ifdef for STAN_THREADS. If this is not defined then the base case needs to run… although we could allow for the TBB double version to run in parallel, but maybe that is not intended by the user in this case (but it would work).
Not yet. You have to move the sliced stuff inside the nested thing and you also have to store the gradients you get. The thing with the gradients of the sliced argument is that you need to index into a global container for the gradients of the sliced argument as I did before. Maybe have a look at the old branch?
Can you run all of my unit tests I wrote (I commented out quite a bit to make some progress)?
This is probably better. Clearer what’s going on with the memory there and probably faster. I’ll try to change it. What’s there is fine cause shared memory makes it so we can use main stack varis on substacks – we just have to make sure varis will not get manipulated by multiple threads. But what you’re saying is better, I think.
edit: Changed “will get manipulated” to “will not get manipulated”… Big difference haha
Ah, I see what you mean… I am really not sure if that’s safe. If you copy-construct vars then they link to one another and as such the chain method will pollute the adjoints of their parents… and these are not reset to zero. I am relatively sure its a trouble maker in a very nasty way. We should keep these really separate. Also: These varis will get placed on the AD tapes of the child threads… and you do not clean them away ever! Yack!
So yes, let’s do house keeping and do it the “old” way.
+1
BTW… it happened to me a few times that I started decent debugging and then I had to realise that I did not turn STAN_THREADS on… doh.
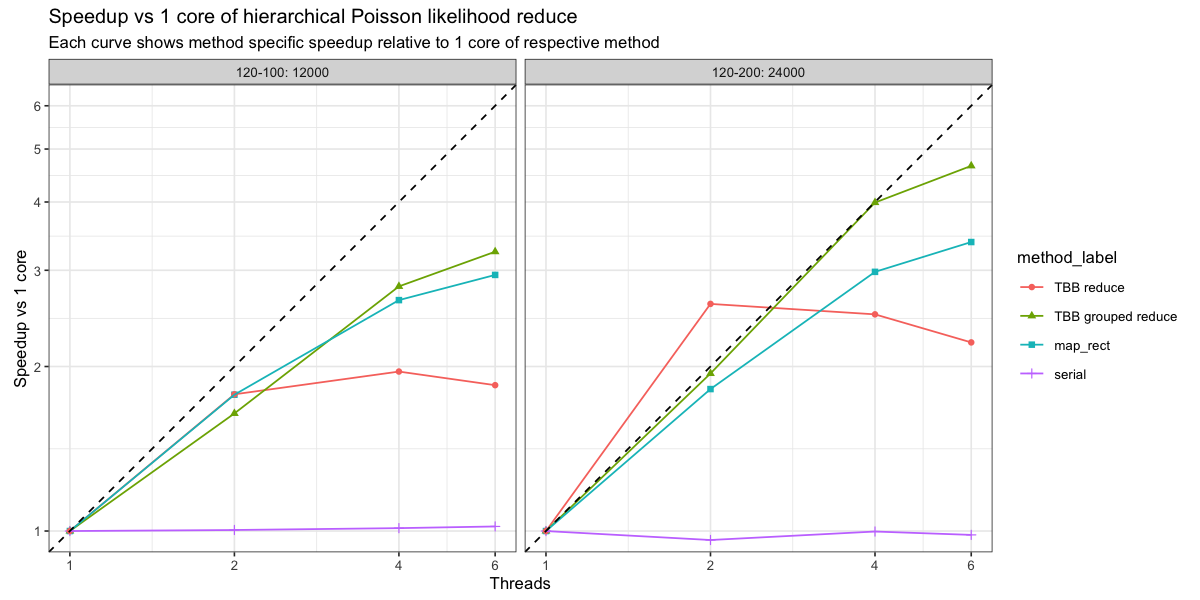
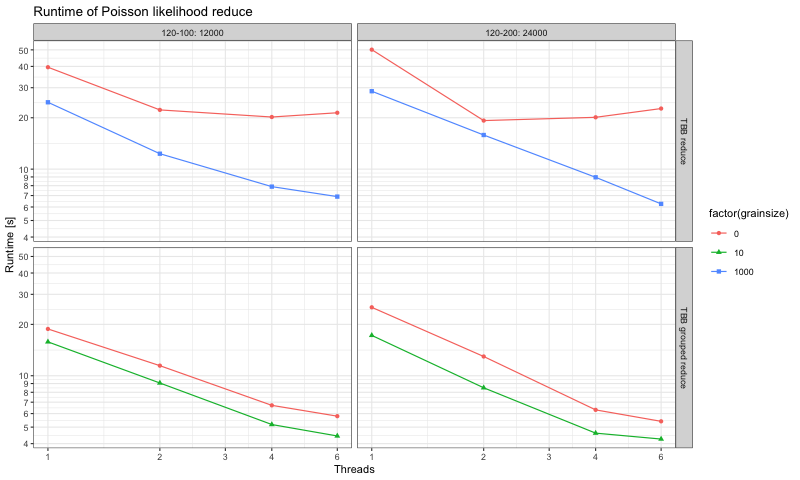
I took your code and slightly modified it so that proper cleanup happens. Then I was curious how it performs on the benchmark I came up with. Here is the result:
So the new code is not yet as efficient as the old one, but we are getting there.
I think we should do first as_value copies as I did before. These are then used as basis for the deep copies. However, we can also stay with what we have and optimize that later. Would be fine with me as well.
std::make_tuple drops references. So if deep_copy passed through something like a const vector<int>& it would get cast to vector<int> and then get copied. Now the pass-through works.