This is all racing ahead much faster than I can keep up. I have no idea how map_rect works now, much less how it can be made to work with closures.
This whole notion of data was meant to be things that we didn’t autodiff against that we could pass to functions like ode_integrate. I think @wds15 is now imagining it as something that’s immutable after data read.
I don’t even know if map_rect works correctly now.
What happens if I do this in a Stan program:
for (i in 1:2)
y = map_rect(f, phi, thetas, { { 1.0 }, {2.0} }, { { i }, { i } });
The integer data changes each iteration. But I thought we tagged memory batches by instance of map_rect. So I don’t see how this can assign a single map_rect call to a processor with fixed data because the data changes by call.
Also, what if the function f in my map_rect call also calls map_rect? That’s all fine under serial evaluation, but I have no idea what’ll happen with MPI or threading. Does anything make sure we don’t wind up spawning hundreds of threads or processes?
The current doc doesn’t say what the requirements are:
So I’d like to start with fixing the current doc to indicate the requirements on the data arguments, etc. Then maybe we can fix the parser to deal with that.
Why not?
Is this only going to apply to functions with a single scalar output? Why that restriction? And what is “automatic parallelism” (I think that’s the same question @seantalts asked).
Even if it weren’t, there’s no way to write a stateful function in the Stan language. Of course, you could in the math lib, but it’d be very tricky now given our basic abstraction that log density evals are independent.
So closures won’t be any use at all here—their main utility in Stan would be implicit capture of parameters and data so we didn’t need to do all the packing and unpacking. But that won’t work with the parallelization we have in place, so I don’t see the point of adding closures. Sure, they’re cool, but I don’t think they’ll be so useful for Stan given that we won’t allow them to be used anywhere useful.
How can start_nested work in parallel? It’s using a resizable contiguous stack.
Is there an example? I never figured out how we could split out all the argments given that we have shared parameters, mapped parameters, mapped real data, and mapped integer data. How could the function call know which is which? You can’t have four parameter packs in a function—it’d be ambiguous.
It already does with print(). There shouldn’t be a problem with variable length functions if they’re well defined.
The case of MPI is special, because we are trying to be smart about distribution of the data. For MPI data is not only “we don’t autodiff against it”, but also “this data is immutable during the runtime of the program”. Let’s keep the MPI / map_rect matters with another thread which I can start to clarify.
For closures to be useful for MPI things will be very hard, indeed. Since we failed to refactor the AD tape closures will also be hard to use with what I have worked out, but it can be done. So what I need is to be able to break links between copied AD variables and create what I would call a “deep copy” of a var:
var a = 1.0;
var a_copy = a; // this will leave a_copy linked to a
var a_deepcopy = var(value_of(a)); // will create a deeply copied var which is not linked to a
So we should need to be able to do deep copies of closures with their entire state internally.
I am using the same technique as done for map_rect, which doesn’t work for higher-order as I understood. Now, we can probably make programs compile and run if higher-order things are used; it’s just that calling the reduce facility with anything else than a var as return type will simply not run parallel. I guess that’s fine.
The approach can be made to work with any output shapes - as long as we know the shapes. So there is no problem in coding that up other than wrestling the C++ outputs types correctly. Making something work which only outputs a scalar is a lot easier. “Automatic parallelism” is something I am not targeting and not so clear what @bbbales2 meant. What I have in mind is to let users basically mark what he/she wants to run in parallel.
Can’t closures be used to, for example, accumulate things which I pass into it? That would be a state which exists during evaluating the log-prob function.
Sorry about any frustration here. It’s that I hit a wall when I attempted to refactor the AD system. What I am coming up with now has the benefit of also running the reverse sweep in parallel. Closures can still be used in this new scheme if we can create deep copies. In any case can we already now remedy the need for closures through variadic functions.
start_nested is not a parallel operation at all. It affects only the thread-local stack. So if you only fire-up thread tasks which themselves always do start_nested, then continue to run and always to a recover_memory_nested, then everything is just fine. This is why map_rect works - the AD operation is never really run in parallel. What we do instead is evaluating small AD tasks in nested environments which are totally separated from one another. Then we collect the results as doubles from the sub tasks and use precomputed gradients to insert the information in the originating, big AD task.
I have never worked with the parameter packs, but since each member of the ... type tuple has its own type, it would be possible to mix the different types. So each argument can have it’s own type.
However, in the meantime I was able to work out something which allows the user to pass in optionally 4 shared arrays of whatever type the user wants to. This does not use parameter packs. The limitation of 4 shared parameters as a maximum is attributed to the operands_and_partials only allowing 5 edges. In any case, I think this is already useful enough for now to be included as-is from my perspective (I still need to do some work for the code to be ready for a PR).
Here is the latest Stan model running the latest code from the branch, which is now general enough to handle quite a few different input types.
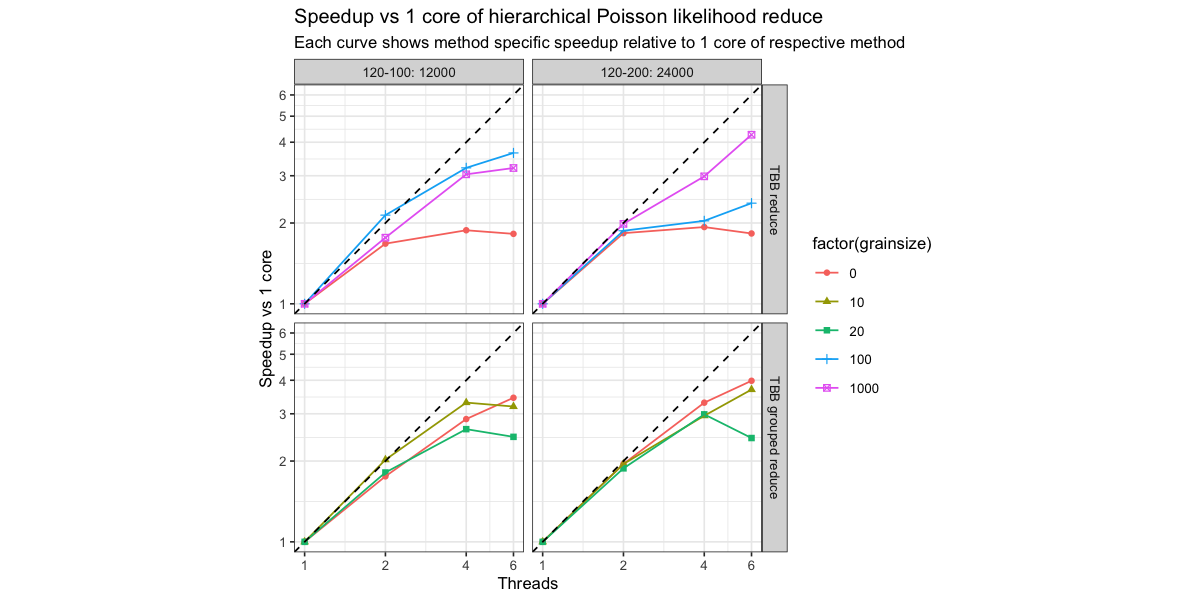
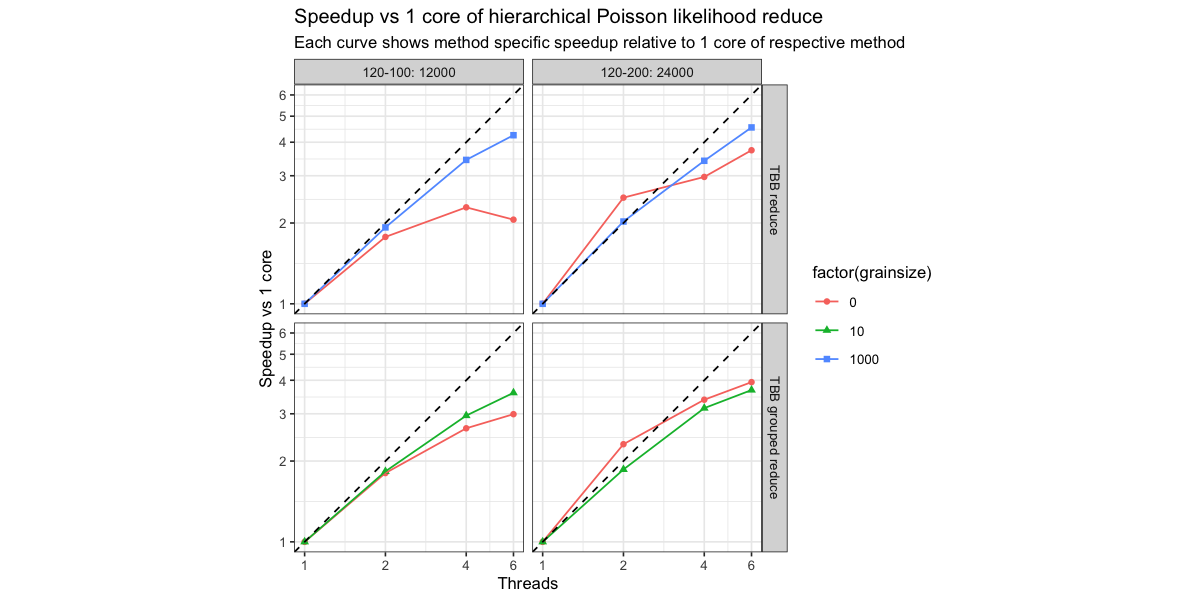
So we see, that “TBB reduce” with a grainsize of 0 is really slow and is also not able to speedup really well. The reason is that the TBB is chunking the work into way too small pieces. That’s totally fine as the TBB can not know what is a reasonable chunk of work to parallelize over. The TBB grouped reduce on the other hand works out almost “just fine”.
All of the above runs on the back of our current AD system… and that’s really cool, I think… let’s cross fingers I haven’t screwed up somewhere… but tests do work out so far just fine.
Haven’t thought it out, honestly. The simplest answer are the var copies @wds15 is talking about. I haven’t though about writing this function for anything other than vars.
What I meant by automatic parallelism is the grainsize = 0 case of @wds15’s plots. I just meant TBB automatically scheduling stuff. I can see how that is confusing now :D.
Well the packing and unpacking is something we want. It doesn’t work with the parallization we have in place, sure, but we’re building more parallelization so that we can do closures.
I suppose we’d need to do some sorta deep-copy shuffling around them, so I guess the connection between closures and parallelism isn’t complete.
We should talk about this but I don’t know what question to ask. So, uh, can you ask a question about using closures and parallelization so we can kick it off?
My understanding is that nested autodiff is already threaded in some way (for map_rect – maybe it’s one nested autodiff stack per thread? Not sure).
I think the interface that @wds15 is talking about looks like:
I just pushed an update of the C++ code… it’s still a bit messy, but it’s starting to settle down and I think I see how we can generalize to non-array shared arguments and hopefully also to using the ... template parameter packs.
Anyway, I suggest that we start a wiki page for reduce_sum in order to keep track of the latest state of things. This hopefully makes it easier for other devs to join this project.
Let’s cross fingers this lands in Stan 2.24 …
EDIT: I pushed forward the code into a state where I start to like it and I have setup a wiki page which hopefully helps interested contributors to give me a hand on this. Would be much appreciated. I need some help with C++ meta-fu fun.
In particular, I am now taking better advantage of knowing what is being autodiffed which allows me to tell the compiler to run more efficient code which avoids some copying. Running the benchmarks now shows that this clearly pays off. The performance is now better than the map_rect case which I never saw before:
Had a look through the updated code (this: https://github.com/stan-dev/math/blob/proto-parallel-v3/stan/math/rev/functor/reduce_sum.hpp). What you’re writing seems fine to me. I’ll point out some points of comparisons between the stuff we’re doing here and adj_jac_apply in the off-chance that looking at the adj_jac_apply code is helpful :D. The goals are different enough I don’t see any reason to try to go out of our way to make these things use the same code.
I definitely think we should at least allow the shared arguments to be any of a scalar, an array of reals, a vector, row_vector, or matrices. This seems really close.
The routine for handling parameter packs is defining everything recursively so you process one argument at a time, and then there’s a special case that handles one argument and stops the recursion (this seems good enough: Introduction to C++ Variadic Templates · R and C++).
At the bare minimum you have two function definitions for these sortsa things. In our cases, each of the arguments are var, real, int, std::vector, std::vector, … and all the different things. For each of these different types you get two more functions (unless there’s a way to only have one termination thing, but looks like I didn’t figure out how to do that).
There’s a connection between parameter packs and tuples. I suspect you’ll have to juggle tuples more than I did. std::apply is the way to go from tuples to parameter packs. You can go the other direction with std::make_tuple. There’s a custom apply in the adj_jac_vari stuff that awaits C++17 to remove: https://github.com/stan-dev/math/blob/develop/stan/math/rev/functor/adj_jac_apply.hpp#L36
Pretty sure I got that pattern from here: Unpacking Tuples in C++14 – Andreas Herrmann . I didn’t leave a link in the comments though. I should have cite something cause it’s a weird looking pattern, but apparently I didn’t.
As far as the code itself, I’d prefer ‘local_operand_and_partials’ to be named something that describes more what it is doing, ‘reallocate_varis’ maybe? ‘local_operand_and_partials’ makes it sound like it’s something used in operands_and_partials, which it isn’t as far as I can tell. I prefer accumulate_adjoints to add_adjoint – add seems like it could also be pushing back adjoints on a stack or something, but feel free to ignore that.
If you want me to specifically do something other than comment, can do, just lemme know. It sounds like you’re having fun figuring out the templates and all though, so don’t let me rob you of that :D.
Why is the walltime for TBB reduce higher than serial but the speedup is 1?
It looks like we should just have a grainsize argument.
The adj_jac_apply code should indeed help me, thanks for making the detailed links; will follow those up.
Now would be a good time to settle on names as it usually hurts to change them.
local_operand_and_partials is supposed to:
hold a reference to the operand
create thread-local deep copies of autodiff variables and just provide references if the operand is a non-autodiff variable
accumulate up the partials
register all the results on the target stack for the pre-computed gradient call
to me that was very similar to operands_and_partials which is why I named it like it. The reallocate_varis would miss out on 3+4 above. I thought call it local_operand_and_partials would make it clear (note the singular operand)… but I see that this may imply too much of a similarity which there isn’t at the moment. Do you have more ideas?
add_adjoint => accumulate_adjoints … ok with me.
Hmmm… probably the best use of you in this project is in reviewing this? That would probably mean to not “burn” you by coding it yourself I suppose.
The wiki page I created lists my current pain points. Maybe have a look at that list and let me know if some meta programs I need already exist to your knowledge (I really don’t know the entire Stan Math source) in order to prevent reinventing the wheel. What you could certainly do is steal some of the utilities which I need (as_value and its meta-program, for example).
Yeah, it’s coding on a decent level which requires a lot of creativity… but it also requires time which is a spare resource in my life. So I do appreciate help as this is a feature which I gauge relatively important for Stan.
These are method specific speedups. So the speedup is relative to running whatever with just one core. There are different serial versions - so which one should I compare to. This is why I also show the absolute wall time runtime.
This is a deep hole I can tell you…living there for a while. Welcome.
If your parameter pack are what we really want, then just throw it on the branch. If you are not so sure, just create a branch off from the current one… anyway is fine for me.
fyi I started munging through the code and I think we can make the base look like what I have in prim reduce_sum. I just need to figure out some of the enable_if stuff with the variadic
Uhm… it sounds as if you both embarked on parameter packs.
In order to coordinate this effort a bit we should probably use the wiki page. So maybe you just put your name besides one of the items in “things left to do” when you start working on this.
In all honesty, I would probably not have started on packs first. My fear is that these obscure the code quite a bit and make it harder to work with as the error messages from the compiler probably get a lot harder to decipher. Maybe I am wrong with that; don’t know.
I have sorted the todo items in the order as I see it.
I also wonder if you both are fine with the structure of the program. I mean, the way its currently written is how I ended up with it after some refactoring rounds… but maybe there is a more genius simpler way.
I will also add a small R script to the wiki page which will run the test model as a benchmark. Running frequently the benchmark was always really helpful for me to judge if my new code was a good idea or not.
I started cleaning it up because I was not a big fan of the design. haha sorry. It was kinda hard to follow so I just deleted a lot of stuff.
In all honesty, I would probably not have started on packs first. My fear is that these obscure the code quite a bit and make it harder to work with as the error messages from the compiler probably get a lot harder to decipher. Maybe I am wrong with that; don’t know.
Parameter packs give pretty normal errors. eod they are just a list of types
The way I implemented optional parameters was a clear hack…which is common in older c++ times. The code you deleted was ugly indeed and exactly why packs where introduced.
If compiler error messages are still easy to read then I am all for it get in sooner than later, sure. I hope all the rest of the code flows well with this.
Eh, I’m gonna spend the afternoon on it. If I get nowhere whatever. No serious loss. I will report back what I find.
@stevebronder I’m gonna go from what you have, which means I’m taking at least one of your todos (“// todo(Steve): Need helper funcs for manipulating / iterating tuples”).