Hi! I am fitting my first ever stan model with the help of my colleagues/supervisor and have some questions.
I simulated fake data to test my model. I have added a non-centered parameterization on my asp because of the banana shape of the log-posterior distribution. But, the way I am recovering asp (or zsp for the non-centered parameter) is worse than before:
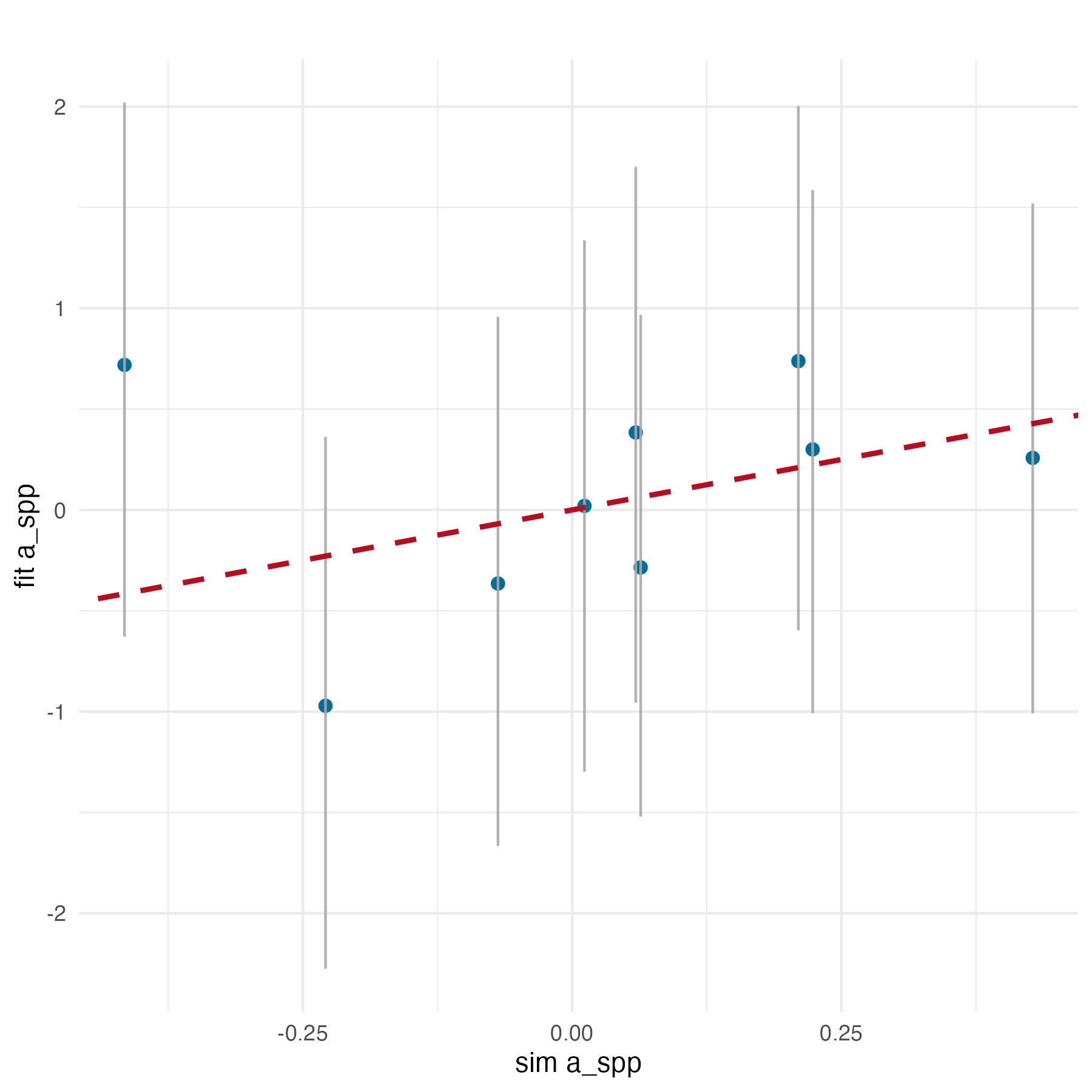
Any idea what would cause this?
Also I am not sure on how to interpret my sigmas, now that I have non-centered parameter. Does sigma_asp relate to zasp ? Because I plotted my fit sigmas VS my simulated sigmas, and sigma_asp intervals are as bad as they were… If someone can help me diagnose my problems, I would appreciate it! See sigma recovery:

Here’s my simulated code along with the call of the stan code:
a ← 1.5
b ← 0.4
sigma_y ← 0.2
sigma_a_spp ← 0.3
sigma_a_treeid ← 0.5
sigma_a_site ← 0.1
sigma_b_spp ← 0.25n_site ← 4 # number of sites
n_spp ← 10 # number of species
n_perspp ← 10 # number of individuals per species
n_treeid ← n_perspp * n_spp * n_site # number of treeid
n_meas ← 5 # repeated measurements per id
N ← n_treeid * n_meas # total number of measurementstreeid ← rep(1:n_treeid, each = n_meas)
treeidnonrep ← rep(rep(1:n_perspp, times = n_spp), times = n_site)
spp ← rep(rep(rep(1:n_spp, each = n_perspp), times = n_site), each = n_meas)
spp_nonrep ← rep(rep(1:n_spp, each = n_perspp), each = n_site)
site ← rep(rep(rep(1:n_site, each = n_spp), each = n_perspp), each = n_meas)
site_nonrep ← rep(rep(1:n_site, each = n_spp), each = n_perspp)
quick check
table(treeidnonrep, site_nonrep)
simcoef ← data.frame(
site = site,
spp = spp,
treeid = treeid
)get intercept values for each species
a_spp ← rnorm(n_spp, 0, sigma_a_spp)
a_site ← rnorm(n_site, 0, sigma_a_site)
a_treeid ← rnorm(n_treeid, 0, sigma_a_treeid)get slope values for each species
b_spp ← rnorm(n_spp, 0, sigma_b_spp)
simcoef$a_treeid ← a_treeid[treeid]
simcoef$a_site ← a_site[simcoef$site]
simcoef$a_spp ← a_spp[simcoef$spp]
simcoef$b_spp ← b_spp[simcoef$spp]simcoef$a ← a
simcoef$b ← b
simcoef$sigma_y ← sigma_y
simcoef$sigma_a_treeid ← sigma_a_treeid
simcoef$sigma_a_spp ← sigma_a_spp
simcoef$sigma_a_site ← sigma_a_site
simcoef$error ← rnorm(N, 0, sigma_y)
simcoef$gddcons ← rnorm(N, 1800, 100)/200simcoef$ringwidth ←
simcoef$a_site +
simcoef$a_spp +
simcoef$a_treeid +
simcoef$a +
(simcoef$bsimcoef$gddcons) +
(simcoef$b_sppsimcoef$gddcons)+
simcoef$errorsimcoef$site ← factor(simcoef$site)
simcoef$spp ← factor(simcoef$spp)
simcoef$treeid ← factor(simcoef$treeid)Run models
y ← simcoef$ringwidth
N ← nrow(simcoef)
gdd ← simcoef$gddcons
Nspp ← length(unique(simcoef$spp))
Nsite ← length(unique(simcoef$site))
site ← as.numeric(as.character(simcoef$site))
species ← as.numeric(as.character(simcoef$spp))
treeid ← treeid
Ntreeid ← length(unique(treeid))
table(treeid)fit ← rstan::stan(“stan/twolevelhierint.stan”,
data=c(“N”,“y”,“Nspp”,“species”,“Nsite”, “site”, “Ntreeid”, “treeid”, “gdd”),
iter=4000, chains=4, cores=4,
control = list(max_treedepth = 15))
And the full stan code:
data{
int<lower=0> N; // number of total observations
int<lower=0> Nspp; // number of species (grouping factor)
array[N] int species; // species identity, coded as int
int<lower=0> Nsite; // number of sites (grouping factor)
array[N] int site; // site identity, coded as int
int<lower=0> Ntreeid; // number of tree ids (grouping factor)
array[N] int treeid; // tree id identity, coded as int
vector[N] gdd; // gdd (predictor for slope)
array[N] real y; // day of year of phenological event (response)
}parameters{
real b; // slope
real a; // mean intercept across everything
real<lower=0> sigma_bsp;
real<lower=0> sigma_asp; // variation of intercept across species
real<lower=0> sigma_asite; // variation of intercept across sites
real<lower=0> sigma_atreeid; // variation of intercept across tree ids
real<lower=0> sigma_y; // measurement error, noise etc.
vector[Nspp] bsp;
vector[Nspp] zasp; // defining transformed asp
vector[Nsite] asite; //the intercept for each sites
vector[Ntreeid] atreeid; //the intercept for each tree id}
transformed parameters{
vector[Nspp] asp;
asp = 0 + sigma_aspzasp; // non-centered a_sp
array[N] real ypred;
for (i in 1:N){ // don’t change this for reparameterization
ypred[i]=a +
asp[species[i]] +
asite[site[i]] +
atreeid[treeid[i]] +
bgdd[i] +
bsp[species[i]]*gdd[i];
}
}model{
bsp ~ normal(0, sigma_bsp); // I guess partial pooling on slopes for species
asite ~ normal(0, sigma_asite); // this creates the partial pooling on intercepts for sites
atreeid ~ normal(0, sigma_atreeid); // this creates the partial pooling on intercepts for tree ids// Priors …
a ~ normal(2, 4);
b ~ normal(0, 0.25);sigma_bsp ~ normal(0, 0.2);
sigma_asp ~ normal(0, 0.5);
zasp ~ normal(0, 1); // here i put the standard centered prior on zasp
sigma_asite ~ normal(0, 0.5);
sigma_atreeid ~ normal(0, 0.05);
y ~ normal(ypred, sigma_y); // this creates an error model where error is normally distributed
}