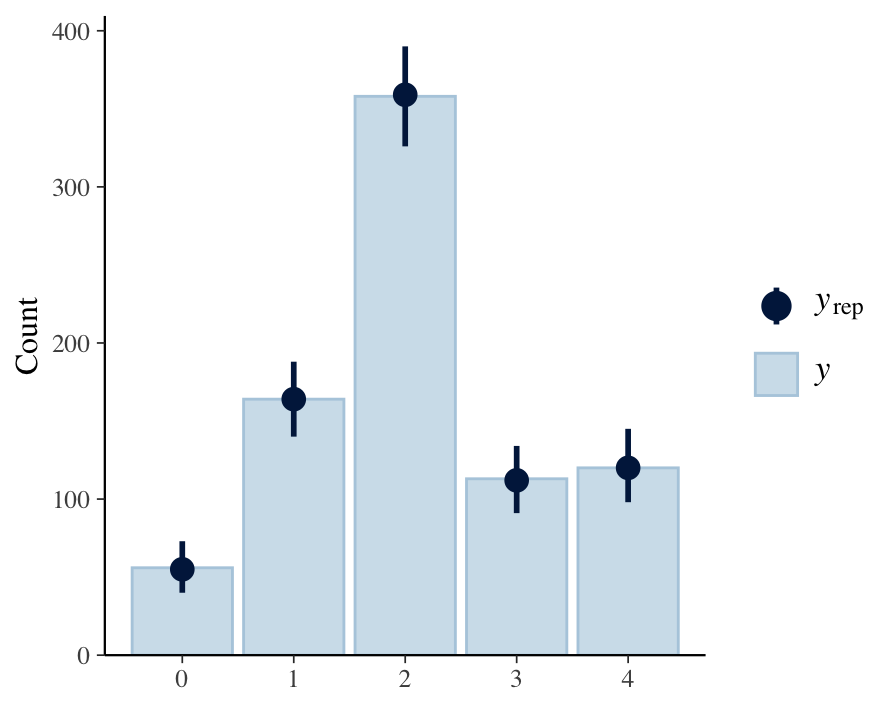
Hi everyone!
This is my first Stan Discourse post, so I apologize in advance for anything I may have missed. I’m working with a bunch of ordinal response variables (for this example I’m using Angela Merkel’s favorability as reported by Pew, data available here) from several surveys.
Some of the questions have a fair proportion of ‘don’t know / don’t respond’ answers, and I want to avoid removing them (or using MICE / full Bayesian imputation) because the level of non-response is informative for us, but also because if I do MRP later on I’d want to be able to model the % of non-respondents by cell (so I want to be able to predict it).

I know there was some discussion of Tobit / Heckman selection models here, and @Solomon discussed conditional logistic models a while ago, but this feels slightly different so I’m curious about your thoughts re: how best to do this! (Also, whether it’s possible in #interfaces:brms )
I put together a simple (and hopefully not catastrophically incorrect) Stan model where the prob of not responding is a Bernoulli, and the ordinal part is handled by the usual ordinal logistic, is there a better (and maybe more straightforward) way to do this?
data {
int<lower=2> K; // number of categories
int<lower=0> N; // number of observations
int<lower=1> D; // number of predictors
int<lower=0,upper=K> y[N]; // response variable
matrix[N, D] x; // design matrix
}
parameters {
vector[D] beta; // predictors for ordered logistic part (e.g. likert scale)
ordered[K-1] c; // number of thresholds for ordered logistic
real alpha_p; // intercept for proportion of non-response
vector[D] beta_p; // predictors for proportion of non-response
}
model {
// model
for (n in 1:N) {
if (y[n] == 0) // assume non-response coded as 0
target += bernoulli_logit_lpmf(1|alpha_p + x[n] * beta_p); // predict non-response with probability p
else // otherwise use ordered logistic with prob 1-p
target += bernoulli_logit_lpmf(0|alpha_p + x[n] * beta_p) + ordered_logistic_lpmf(y[n]| x[n] * beta, c);
}
}
generated quantities {
vector[N] yrep; // generate samples
vector[N] temp;
for (n in 1:N) {
temp[n] = bernoulli_rng(inv_logit(alpha_p + x[n] * beta_p));
if (temp[n] == 1)
yrep[n] = 0;
else
yrep[n] = ordered_logistic_rng(x[n] * beta, c);
}
}
Here’s the code to run the model. It seems to work fine.

library(readr)
library(dplyr)
library(rstan)
data <- read_csv("https://raw.githubusercontent.com/octmedina/zi-ordinal/main/merkel_data.csv")
D <- 4 # number of covariates
N <- length(data$confid_merkel) # number of observations
y <- data$confid_merkel # response variable
x <- matrix(c(data$party, # covariates
data$edu,
data$race,
data$income),
nrow = N, ncol = D)
K <- length(unique(data$confid_merkel)) - 1 # number of ordinal levels (0 doesn't count)
stan_data <- list(
N = N,
K = K,
y = y,
x = x,
D = D)
fit_merkel <- stan(file = "https://raw.githubusercontent.com/octmedina/zi-ordinal/main/zi-ordinal-model.stan", data = stan_data,
chains = 2,
cores = 2,
iter = 2000)
print(fit_merkel, pars= c("beta", "c", "alpha_p", "beta_p"))
Thank you so much!