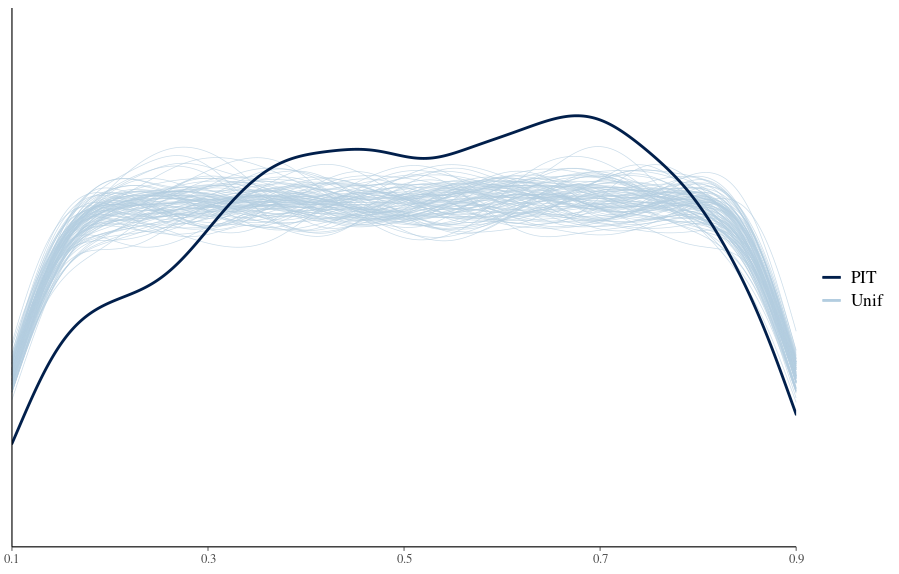
I’m working with a data set and fitting a multi-level gaussian model with several (scaled and centered) continuous predictors as well as a categorical predictor and some interaction terms.
While the posterior predictive checks look somewhat acceptable:
My reading suggests this is likely due to over-dispersion, which in turn could be related to not capturing the uncertainty adequately (model specifies more uncertainty than exists in the data) , both of which mean more modelling is required.
But, I’m unsure of what direction to take?
Is this something I can overcome by revisiting and broadening (or tightening) my SD priors?
I’m running into difficulty imparting any noticeable changes to these plots.
That would often be attributable to non-constant error variance across observations. The brms package has a good bit of functionality for “distributional models” that allow you to utilize a GLM for the error variance.
I generalized the model somewhat by estimating additional variances for the 2nd categorical predictor and the interaction with the first. This change seems to have improved things!