I have invested lotsa lotsa time changing my code that was based on saved pystan2 fits, and calling pystan2 estimates, so that it works with pystan3, since the fora said pystan2 ain’t cool (supported) any more (or won’t be).
And then more time making my code work with both, when I ran into multiple problems trying to switch over.
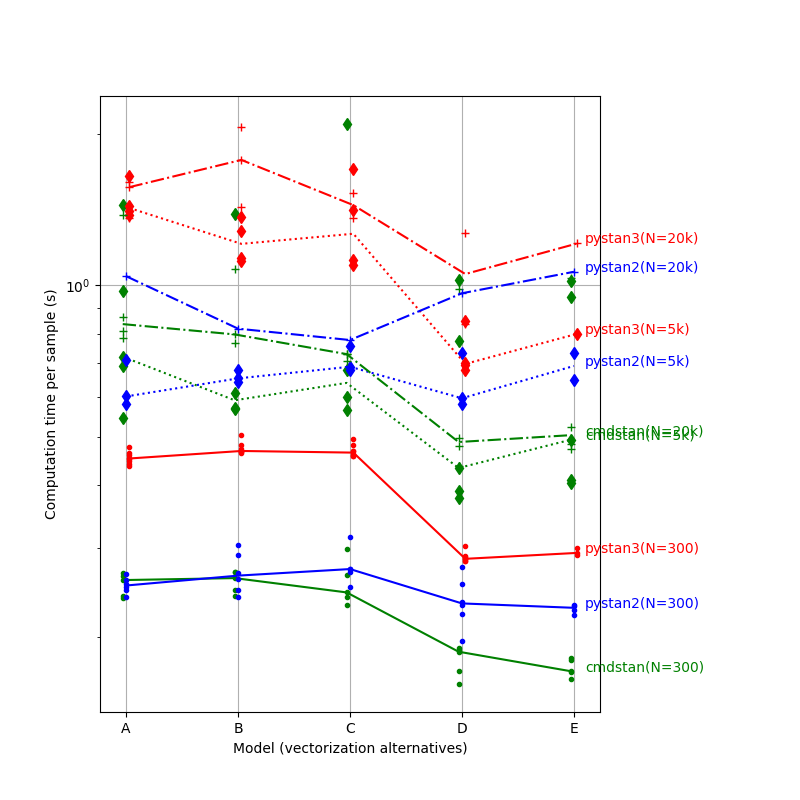
Now I’ve actually run some comparisons. My estimates are something like an ordered logit typically on 5k to 20k and sometimes 80k+ samples.
The plots below show run times (and run times divided by the number of samples) for N=300 and 5000 .
(As an aside: the A/B/C/D models are increasing degrees of vectorizing my main loop. Model E also adds (back) in my extensive generated quantities.)
The tests show pystan3 a factor of nearly 2 slower than pystan2, though this difference is happily somewhat mitigated in my most-vectorized effort.
Has anyone else run into this too?
I’m running on a big GNU/Linux server, using pystan3.2 and the latest pystan2.
Updated plots with larger samples (I hope this is an okay way to share images):
It seems clear that pystan3 is benefiting more than pystan2 from the bits of vectorization I was able to do (esp “D”). However, pystan3 is scaling worse than pystan2 (esp for “D” case) with sample size (N).
My generated quantities (E) are taking a bit of time, but still not much.
Thanks for posting. That looks like some constant overhead plus overhead per draw. I don’t have a sense for why a more highly vectorized model would have less overhead, as the time spent on the Stan side of things should be the same. Do all the vectorization options output the same parameters?
You might want to try cmdstanpy, which just calls CmdStan directly.
Thank you very much.
Yes, the output parameters are identical. The temporary ones defined in the model block are not, I suppose. None has any extra generated quantities except for “E”.
@ariddell in pystan2 did you build the model once per python object then use it when the user called sample()? Looking at the code for httpstan it looks like the model is created each time sample is called now
I think that could account for the overhead @cpbl is seeing.
Serialization does slow things down a bit. It’s essentially a fixed cost. If it takes a few minutes to gather your draws from a model, it should not matter much if you’re using pystan vs. cmdstan.
If having really fast, short runs is important to you, there’s probably certain changes which could be made to the httpstan code which would speed things up.
Just to be sure, what is a “short run”? The ones I posted are taking 40,000 s (11 hours) but some of my real data is larger than that, so might I expect the scaling to improve still at larger sizes? Surely not…
In your graphs, the worst case for PyStan 3 vs Pystan 2 appears to be short runs. That’s consistent with what I’ve found.
If you want to dig into this further, I’d suggest comparing CmdStan 2.22 (PyStan 2’s Stan version) vs. CmdStan 2.28 (current). The interface overhead should be about the same. With PyStan 2 and PyStan 3 the overhead is both different and difficult to change (as it’s due to design decisions).
There is some scatter across runs; maybe I had too many jobs running on the server for some. In any case, it looks like I should just switch to cmdstan. I can’t see the downside right now.
Thank you all!
Doesn’t cmdstan force you to write the output content to a file? That would add major overhead if you have big chains and your goal is to analyze them using some other script.
To avoid that you could add a pipe between cmdstan and, for example, a Python script to analyze the data, if you were to do that, what would you think would be the difference between pystan3? That’s what I think should be compared here after all.
PyStan 3 is not slower. In fact, it can be faster, if you set a few compiler flags.
Here’s a reproducible example which shows that pystan 3.3.0 is about 2.5% slower than cmdstan 2.28.0 (i7-10510U, gcc, Ubuntu 20.04, ldaK2 from posteriordb).
pystan 3.3.0:
Benchmark #1: python ldaK2.py
Time (mean ± σ): 375.532 s ± 60.630 s [User: 386.998 s, System: 2.477 s]
Range (min … max): 300.288 s … 454.281 s 10 runs
cmdstan 2.28:
Benchmark #1: /tmp/posteriordb/posterior_database/models/stan/ldaK2 sample num_warmup=150 num_samples=150 data file=/tmp/prideprejudice_chapter.json
Time (mean ± σ): 366.327 s ± 37.354 s [User: 365.676 s, System: 0.115 s]
Range (min … max): 277.826 s … 411.225 s 10 runs
If you set certain compiler flags, however, you can get pystan 3.3.0 running 8% faster than cmdstan 2.28:
pystan 3.3.0 with additional flags (-flto -mtune=native -fvisibility=hidden -fno-semantic-interposition):
Benchmark #1: python ldaK2.py
Time (mean ± σ): 338.119 s ± 19.024 s [User: 347.348 s, System: 2.128 s]
Range (min … max): 307.601 s … 366.789 s 10 runs
Of course, you could set these flags in cmdstan and speed things up too. (They do not appear to be set by default in the release tarball’s makefiles.)
Why the original difference? I think it likely has to do with the fact that CPython requires that extensions be compiled with -fPIC. This apparently makes certain optimizations more difficult.