Hi, I am fitting a simple model with random effect as shown below:

alpha_i in the model represents random effect for different genes (i here represents genes). I assume alpha_i follows a normal distribution with a hierarchical prior sigma_gene. The ultimate goal is to estimate the posterior distribution of sigma_gene. Other variables are not related to this question so I skipped the introduction of them.
Here is how I specified prior for this model:
bpriors <- prior(normal(0, sigma_global_sd), class = "b", coef = "Intercept") +
prior(constant(1), class = "b", coef = "sc.prop") +
prior(normal(0, sigma_gene_sd), class = "sd") +
prior("target += cauchy_lpdf(sigma_global_sd | 0, 10)", check = FALSE) +
prior("target += cauchy_lpdf(sigma_gene_sd | 0, 10)", check = FALSE) +
prior(gamma(0.01, 0.01), class = "shape") +
prior(beta(1, 1), class = "zi")
stanvars <- stanvar(scode = "real<lower=0> sigma_global_sd; real<lower=0> sigma_gene_sd;",
block = "parameters")
sigma_gene_sd in the code represents sigma_gene in the model above. Below is the brms result after fitting the model:

Based on the result and the data I have, I am pretty sure that the distribution of sd_gene__Intercept represents the estimate posterior distribution of the hyperparameter sigma_gene in the model, i.e., the posterior distribution of the variance of the normal distribution of the random effect. Then my first question is, if this is correct, then what is the distribution for sigma_gene_sd? What is the difference between sd_gene__Intercept and sigma_gene_sd?
Another question is that, if I run prior_summary on the model, here are the list of parameters and their corresponding priors:
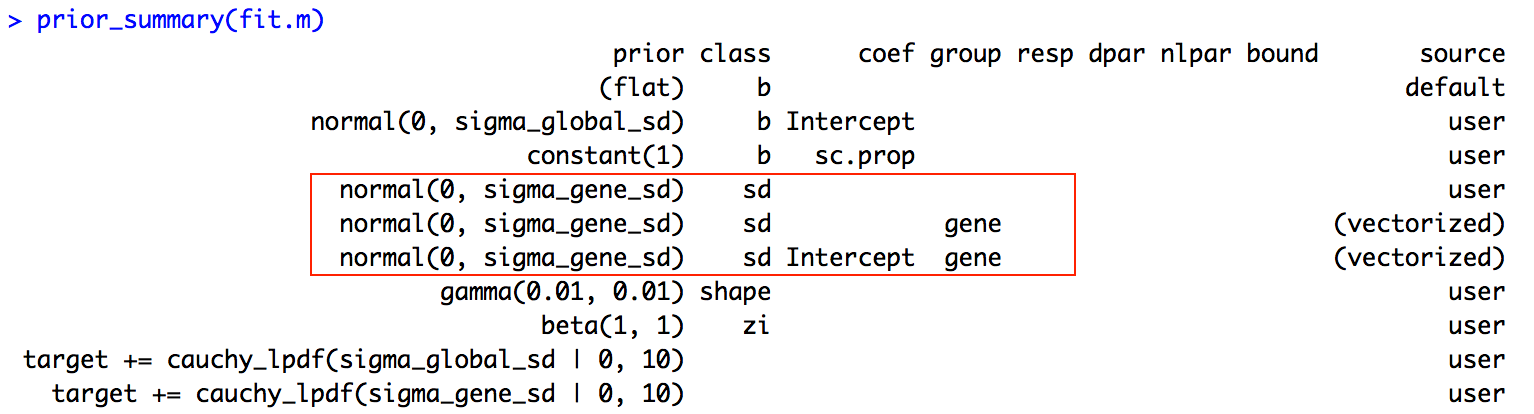
What is the difference between the three parameters in the red square? Are they three different parameters or they represent the same thing?
Thank you!