Hi all, I am trying to build an hierarchical model in which the observed outcome dA, detection of new records of group A, is binomial distributed: dA \sim Binomial(yearly\_detections, P).
P is probability of success which is equivalent to the proportion of unrecorded individuals of group A to all the unrecorded individuals (group A + group B): P = \frac{unrecorded_A}{unrecorded_A + unrecorded_B}.
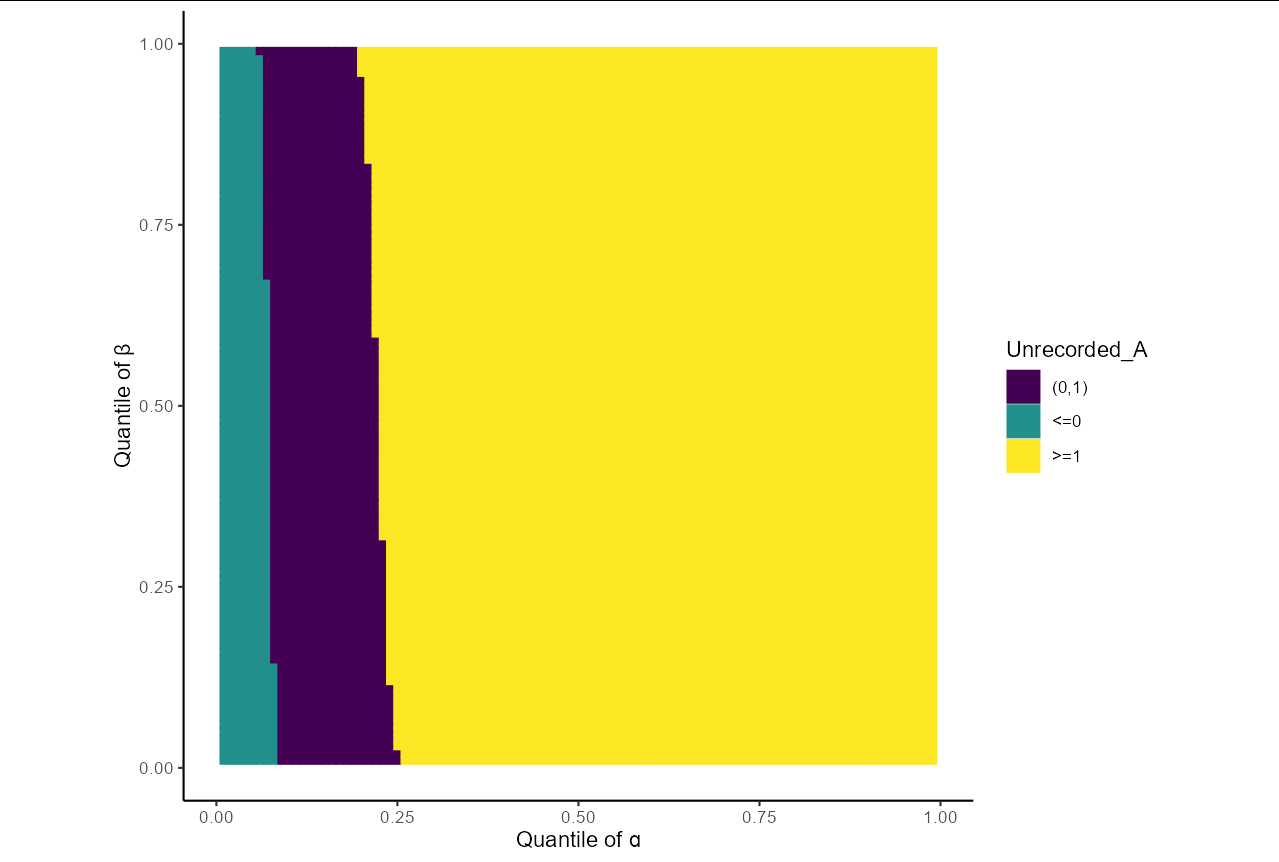
Where unrecorded is simply the difference between the total number of individuals in a group and the cumulative sum of number of yearly records.
Total number of individuals from group B is fixed, but the number of individuals from group A increases with t according to \lambda = exp(\alpha + \beta * t) and has a Poisson distribution y \sim Poisson(\lambda) .
Now, if I ignore the Poisson distribution part and just use \lambda to calculate unrecorded_A, the model “works” but I get this message a lot:
Chain 1 Informational Message: The current Metropolis proposal is about to be rejected because of the following issue:
Chain 1 Exception: binomial_lpmf: Probability parameter[150] is -0.00198042, but must be in the interval [0, 1].
Chain 1 If this warning occurs sporadically, such as for highly constrained variable types like covariance matrices, then the sampler is fine,
Chain 1 but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
But given that y is a Poisson distributed variable around the mean, I think I can avoid getting negative P such as here, but I can’t figure out how, since I can’t define an integer parameter y as far as I understand.
Here is the code:
data{
int <lower = 1> N; // number of rows in the data
int <lower = 1> B_total; // assumed number of ind in group B
array[N] int <lower = 0> dA; // observed number of yearly records A
array[N] int <lower = 0> dB; // observed number of yearly records B
vector[N] t;
}
transformed data {
array[N] int <lower = 0> unrecorded_B;
array[N] int <lower = 0> yearly_detections;
array[N] int <lower = 0> recorded_A; // cumulative recorded A
array[N] int <lower = 0> recorded_B; // cumulative recorded B
recorded_A = cumulative_sum(dA);
recorded_B = cumulative_sum(dB);
for (i in 1:N){
unrecorded_B[i] = B_total - recorded_B[i];
yearly_detections[i] = dA[i] + dB[i];
}
}
parameters {
real alpha;
real beta;
}
transformed parameters {
vector[N] rate = alpha + beta * t;
}
model{
vector[N] y;
vector[N] unrecorded_A;
vector[N] P;
//priors
alpha ~ normal(0, 0.01);
beta ~ normal(0, 0.001);
y = exp(rate);
for (i in 1:N){
unrecorded_A[i] = cumulative_sum(y)[i] - recorded_A[i];
P[i] = unrecorded_A[i]/(unrecorded_A[i] + unrecorded_B[i]);
}
dA ~ binomial(yearly_detections, P);
}
Ideally I would like to replace y = exp(rate); with the more accurate y ~ poisson_log(rate), but I have no idea how to get it to work.
Is it at all possible?
I keep going back to what I believe are the relevant chapters in the documentation, but I may be missing something entirely. Any guidance will be much appreciated.