Hi,
I need to fit a model with following information:
where p(c)=\pi_j is a proportion. I have defined the prior distributions for the logit(\pi). My stan model is as follows:
data {
int<lower=1> N1;
int<lower=1> N2;
int<lower=0,upper=1> y1[N1];
int<lower=0,upper=1> y2[N2];
int<lower=1> K1;
matrix[N1,K1] x1;
matrix[N2,K1] x1h;
real <lower=0,upper=1> pi1[N1];
real <lower=0,upper=1> pi2[N2];
}
parameters {
real alpha1;
real alpha2;
vector[K1] beta1;
vector[K1] beta2;
}
model {
vector[N1] mu1 = alpha1+ x1 * beta1;
vector[N2] mu2 = alpha2+ x1h * beta2;
//priors
target +=normal_lpdf(beta1| 0,10);
target +=normal_lpdf(beta2| 0,5);
target += normal_lpdf(alpha1| 0,10);
target += normal_lpdf(alpha2| 0,10);
target += normal_lpdf(log(pi1/(1-pi1))| 0.6,0.1);
target += normal_lpdf(log(pi2/(1-pi2))| 0.72,0.14);
for(i in 1:N1){
target += bernoulli_logit_lpmf(y1[i] | mu1[i]);
target += pi1[i];
}
for(i in 1:N2){
target += bernoulli_logit_lpmf(y2[i] | mu2[i]);
target += pi2[i];
}
}
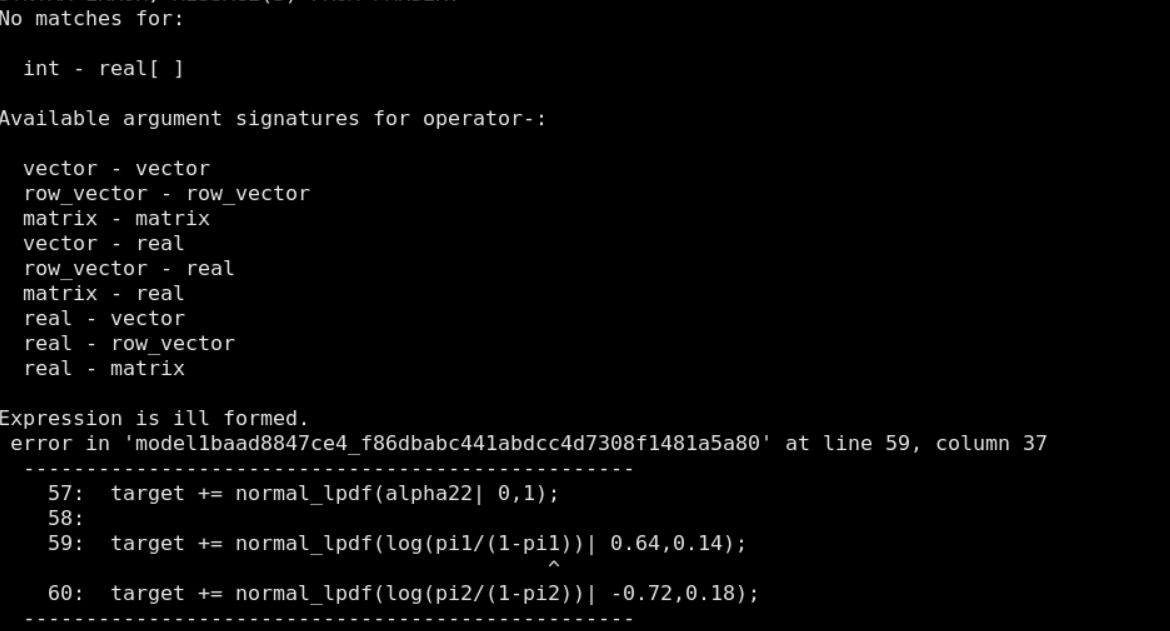
However I got following error:
Can anybody help me to fix this issue?
Also when I define the proportions, do I need to specify it as “target += log(pi1[i]);”, instead of “target += pi1[i];”. I have this question because Stan calculates the log posterior distribution.
Thank you very much
Where you have 1-, do 1.0-
@mike-lawrence Thank you for your reply. But it didn’t work. I got this error:
In this model, ‘pi1’ and ‘pi2’ are group specific constant proportions. That means for all the observations from group 1 (size=N1) , pi1 is same and for group2, pi2 is same.
Oops. Sorry, didn’t realize they were arrays. Try rep_array(1.0, N1) ./ pi1
Since pi1 is data, you should compute log(pi1/(1-pi1)) outside Stan and pass the result as data, ditto pi2. Or do it in transformed data if you want everything in one place code-wise.
@mike-lawrence
Thank you again. But I am afraid that I still couldn’t solve this.
My data looks like this:
> data_f=function(y1,y2,x_1,x_2){
> list(N1=length(y1),N2=length(y2),
> K1=2,y1=y1,y2=y2,
> x1=x_1,
> x1h=x_2,
> pi1=a$pi,
> pi2=b$pi
>
> )
> }
You may see that pi1 and pi2 has already defined as arrays (Before creating the Stan model)
And I included the transformed parameters section:
data {
int<lower=1> N1;
int<lower=1> N2;
int<lower=0,upper=1> y1[N1];
int<lower=0,upper=1> y2[N2];
int<lower=1> K1;
matrix[N1,K1] x1;
matrix[N2,K1] x1h;
real <lower=0,upper=1> pi1[N1];
real <lower=0,upper=1> pi2[N2];
}
parameters {
real alpha1;
real alpha2;
vector[K1] beta1;
vector[K1] beta2;
}
transformed parameters{
vector[N1] log_pi1= log((rep_array(1.0,N1)./pi1)/(1.0-(rep_array(1.0,N1)./pi1)));
vector[N2] log_pi2= log((rep_array(1.0,N2)./pi2)/(1.0-(rep_array(1.0,N2)./pi2)));
}
model {
vector[N1] mu1 = alpha1+ x1 * beta1;
vector[N2] mu2 = alpha2+ x1h * beta2;
//priors
target +=normal_lpdf(beta1| 0,10);
target +=normal_lpdf(beta2| 0,5);
target += normal_lpdf(alpha1| 0,10);
target += normal_lpdf(alpha2| 0,10);
target += normal_lpdf(log_pi1| 0.64,0.14);
target += normal_lpdf(log_pi2| -0.72,0.18);
for(i in 1:N1){
target += bernoulli_logit_lpmf(y1[i] | mu1[i]);
target += pi1[i];
}
for(i in 1:N2){
target += bernoulli_logit_lpmf(y2[i] | mu2[i]);
target += pi2[i];
}
}
I got this error:
I am pretty sure this error is due to some variable type issue of pi1 and pi2 like you are trying to help. But I couldn’t figure it out yet.
@mike-lawrence , I will think about this and see what I did wrong. Is it possible to answer to my second question ?
i,e, in the model I used “target += pi2[i]; and target += pi1[i];” to include pi1 and pi2 in the likelihood. Is it correct or do I need to include it as “target += log(pi2)[i] and target += log(pi1)[i]” as Stan calculates the log posterior distribution?
Thank you for your help.
Actually, wait a second. I didn’t look at your model carefully until now. What role is the data variable pi1 and pi2 intended to play in the model? Just as normalization constants? Do you know that you need these? (I.e. for LOO maybe?)
If you don’t explicitly know you need normalization constants, don’t bother with them; MCMC is fine without them.
@mike-lawrence The pi1 and pi2 values are proportion of group status. There are two groups with N people. The likelihood function p(y,c|x) of N people (Please have a a look again if possible, there was a typo before) can be factored in to two parts (with N1 and N2). The response variable y depends on the group status.