Hello, I am working on a project devoted to promotions estimation.
My first model was a stan regression with truncated normal distribution on some betas based on the model in the prophet python library. This regression gave expected results, but the warning about divergencies happens after model fitting. So a asked about that in Divergencies with truncated normal.
Then thanks to stan documentation and stan community help in Divergencies with truncated normal I fixed regression by forcing positive influence on some beta during variable initialization in a truncated normal model. The divergencies problem was solved.
But after the fix stan model sometimes doesn’t converge. I get bad Gelman-Rubin statistics, the impact of the promotion takes away some trend influence. It turns out that fitting becomes unstable.
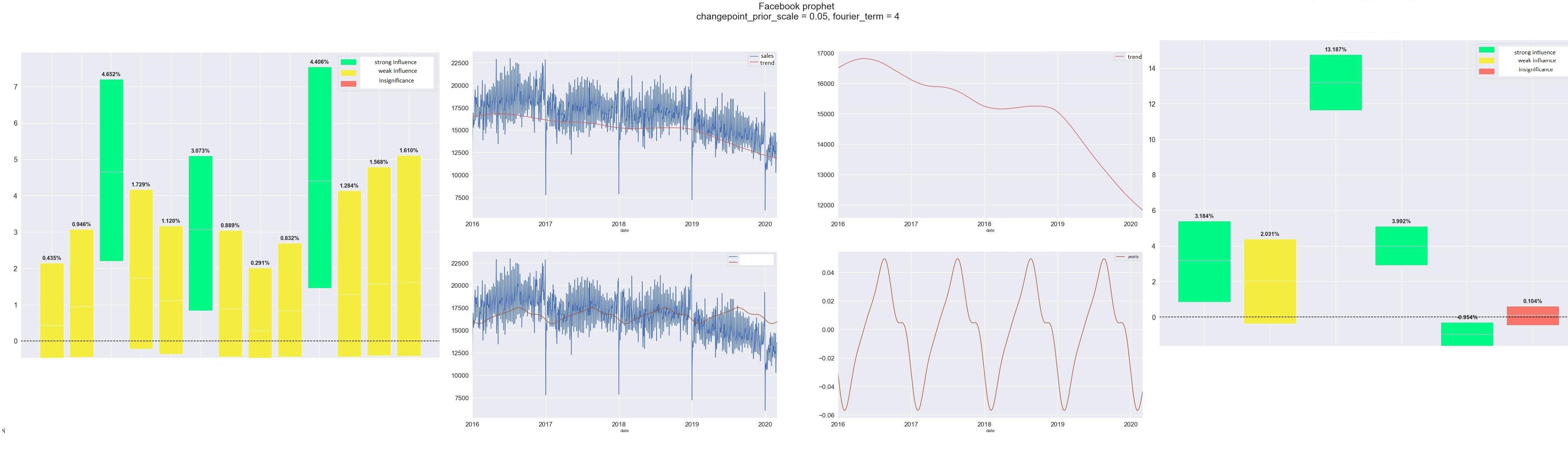
So I tested 3 models on my sales data and made plots with constrained beta influence, trend, seasonality, and other factors influence:
- A regression with positive constraints for the part of betas. Here the impact of the promotion takes away some trend influence. So the model doesn’t converge.
- A truncated normal model. Results are stable, but the warning about divergencies happens. According to documentation and stan community it is an incorrect model.
- A truncated normal model with positive constraints for the part of betas. This is the expected and ideal result. The problem is that sometimes instead of such results in the plot I can get something like in the 1st plot.
It is clear that the cause of such a fitting issue is forcing some beta coefficients to positive during variables initialization. I think that forcing positive constraints violates the premise of an equal probability transition in HMC. Is it right or not? Can we solve the problem and leave constraints in the model?
I’d appreciate any thoughts on this. Thanks.
Aleksandr
I am sorry, but I don’t really understand the model or the plots. Could you post your updated Stan code? Also share for which parameters are the Rhats wrong and possibly some pairs plots or other diagnostics plots as described in https://cran.r-project.org/web/packages/bayesplot/vignettes/visual-mcmc-diagnostics.html
Hi! Thank you for your reply!
I attached:
- prophet_original - original model.
- prophet_2 - model with truncated normal. This is the recent code I use.
- prophet_3 - model made according to stan documentation with constrained beta and truncated normal that currently has convergence issue.
I will sample models and send diagnostics a bit later.
I just checked prephet_3 and I would guess that the problem is that constraints in Stan cannot be implemented with the truncated distributions - those only work well for data. The sampler needs to be aware of the constraints and this information currently can’t be inferred from the code as you’ve written it. Usually, you would put constraints into your variable definitions (e.g. real<lower=B[1,1], upper=B[1,2] beta_constr_1;) but this doesn’t support variable number of constraints.
If you need variable number of constraints, the best you can do is IMHO to have unconstrained parameter vector[K] beta_raw and compute beta in the transformed parameters block, reimplementing the transform and log Jacobian (derivative) adjustment as described in https://mc-stan.org/docs/2_23/reference-manual/logit-transform-jacobian-section.html (see https://mc-stan.org/docs/2_23/reference-manual/change-of-variables-section.html for discussion of the adjustment).
Does that make sense?
Once you do this, then the sampling statements for beta as you’ve written them should work.
Hi! Thank you for the reply!
I realized that I got the file numbering wrong in my previous reply:
prophet_2 - model made according to stan documentation with constrained beta and truncated normal that currently has convergence issue.
prophet_3 - model with truncated normal. This is the recent code I use.
And prophet_2 is the model you described.
The problem was that sometimes the model didn’t converge. So the results were unstable.
Anyway, when I was preparing diagnostics plots for my next reply here I also tried to change “init_r” argument in pystan fit class. “init_r” controls the range of randomly generated initial values for parameters. The default value was 2 which means that we have [-2, 2] uniform distribution for initial values. When I changed “init_r” to 0.01 I got stable results and convergence. As a result, all the r_hat =1.0-1.01, no divergencies were detected.
So the reason for the whole issue in my final model was initial values that could be sampled from U[-2, 2] too far relative to priors. As a result, the lack of convergence could happen.
prophet_constrained.stan (4.0 KB)