The thread I started at Request for Mathematica code review: generating test cases - #8 by Bob_Carpenter devolved into discussion about general principles for tests in Stan math. As the title (and start of the discussion) is about something else, I am moving the discussion here to make it better visible and findable and so that more people can join if they like. This post recapitulates the discussion since it started to change topic and has been slightly edited for brevity.
Background: I’ve been working on addressing some issues in neg_binomial_lpmf and related functions. Part of the tests I’ve written involve computing high-precision values in Mathematica and test against those.
@bgoodri mentioned:
I would just reiterate a couple of things that I have said before that few people agree with:
- I think we should be testing that known identities hold. For example, since \ln \Gamma\left(x\right) = \ln \Gamma\left(x + 1\right) - \ln x for all positive x, plug in an x to that equation and verify that the equation holds and that all derivatives of interest are the same on both sides.
- Even better are identities that hold for integrals involving the function in question over a range of values of x, such as http://functions.wolfram.com/GammaBetaErf/LogGamma/21/02/01/0001/MainEq1.gif .
- If we want arbitrary precision tests to compare to, then the gold standard is Arb rather than Mathematica, because the ball arithmetic has bounds that are correct. And Arb is already in C.
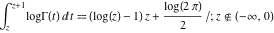{kind=link}
My response:
I am trying to approach this from a pragmatic viewpoint. I think developer efficiency in writing tests is really important. My interest in this has been sparked by the fact that many (most?) functions/codepaths in Stan math currently have no or only very weak tests for numerical precision.
IMHO you are making perfect the enemy of the good here. I totally agree that tests against precomputed values shouldn’t be the only tests we do. In my recent struggle with neg_binomial_2 and surrounding functions, both approaches let me to identify some of the issues.
For me the biggest advantage of precomputed values is that those tests are quite easy to create. Let’s say I fear that lbeta fails with one very large and one very small argument. So I precompute values for this case in high precision and check. Not bulletproof, but quick. I am sure a clever formula-based test would show this as well, but I can’t make up one quickly.
Another issue with formulas is that I always have to worry about the numerics of the formula itself.
And there are functions for which good formulas are hard to come by, for example the lgamma_stirling_diff function I wrote (defined as the difference between lgamma and it’s Stirling approximation). Here any tests actually involving lgamma are weak because the interesting use cases for lgamma_stirling_diff are when lgamma is large and we would need more digits to capture the desired precision. I believe you may come up with some clever way around this, but using precomputed values let me to have a reasonably strong test quickly.
Using Arb might well be a better way forward in the long run, but I personally lack the skill and patience to work with C/C++ more than I have to. The cloud Mathematica is a good enough tool for me in that it lets me iterate quickly (and I already use it to check my symbolic manipulations). If someone integrated Arb with the test code in Stan math, than it would be a big advantage for Arb as the tests wouldn’t need to rely on external code. But I don’t think that has been done yet.
You seem to imply that Mathematica can provide wrong results in cases where Arb would work. That would be a good reason to prefer Arb over Mathematica. I tried to quickly Google for some evidence in this regard and didn’t find any.
Where I think I would agree with you is that the unit tests of Stan Math emphasize whether code compiles and whether the code is correct, as opposed to whether the code produces the correct numbers for almost all inputs that are likely to be called when doing dynamic HMC. And I wrote a bunch of unit tests starting at
https://github.com/stan-dev/math/blob/develop/test/unit/math/rev/functor/integrate_1d_test.cpp#L423
that did what I thought was an admissible test for each of the univariate
_lpdffunctions, namely testing the identity that their antilog integrates to 1 over their entire support and the derivatives with respect to all of the parameters are zero. Fortunately, most of our_lpdffunctions satisfied this after some tweaking. I couldn’t do exactly that for the_lpmffunctions, and I am not surprised that you encountered some issues with the negative binomial that should be addressed.But I am bitter that the success of this approach has not changed anyone’s mind about how to unit test functions in Stan Math more generally. I have made what I think are strong arguments about this for years, and they have mostly been ignored. I appreciate that you did take the time to make some good-faith arguments for your approach, although I am not that persuaded by them. I’m just going to let it drop for now. If you make a PR with tests like this, I won’t object and I haven’t objected to anyone else’s PRs on these grounds.
@Bob_Carpenter joined:
I think you may have misinterpreted my earlier comments. I think this is a good idea, just not always necessary if we can do thorough tests versus well-defined base cases like the lgamma from the standard library.
To really get traction on this, it should be automated to allow us to plug in two functions and a range of values and make sure all derivatives have the same value. I can help write that. It’d look something like this:
template <class F, class G> expect_same(const ad_tolerances& tol, const F& f, const G& g, Eigen::VectorXd x);where the vector packs all the arguments to
forg. We cold get fancier and put in a parameter pack forxand try to use the serialization framework to reduce it to a vector to supply to our functionals.As @martinmodrak points out,
That’s why I included tolerances.
Wouldn’t we need to write all our functions to deal with their data types? Or recode them?
I don’t get this comment. From my perspective, both @martinmodrak and @bgoodri are suggesting new, complementary tests that go beyond what we have now. If people want to put in effort making tests better, more power to them!
I don’t have any opinion about Arb vs. Mathematica in terms of coverage or accuracy. I’d never heard of Arb before @bgoodri brought it up. The problem I have is that I can’t read that Mathematica code. So the discussion we should have is whether everyone’s OK introducing one more language into the project after OCaml and C++.
On a related note, the thread on tests for distributions discusses possibilities for strengthening current tests for distributions, including precomputed values but also using complex-step derivative.
The thread on tolerances at `expect_near_rel` behaves weirdly for values around 1e-8 - #6 by martinmodrak is also relevant.