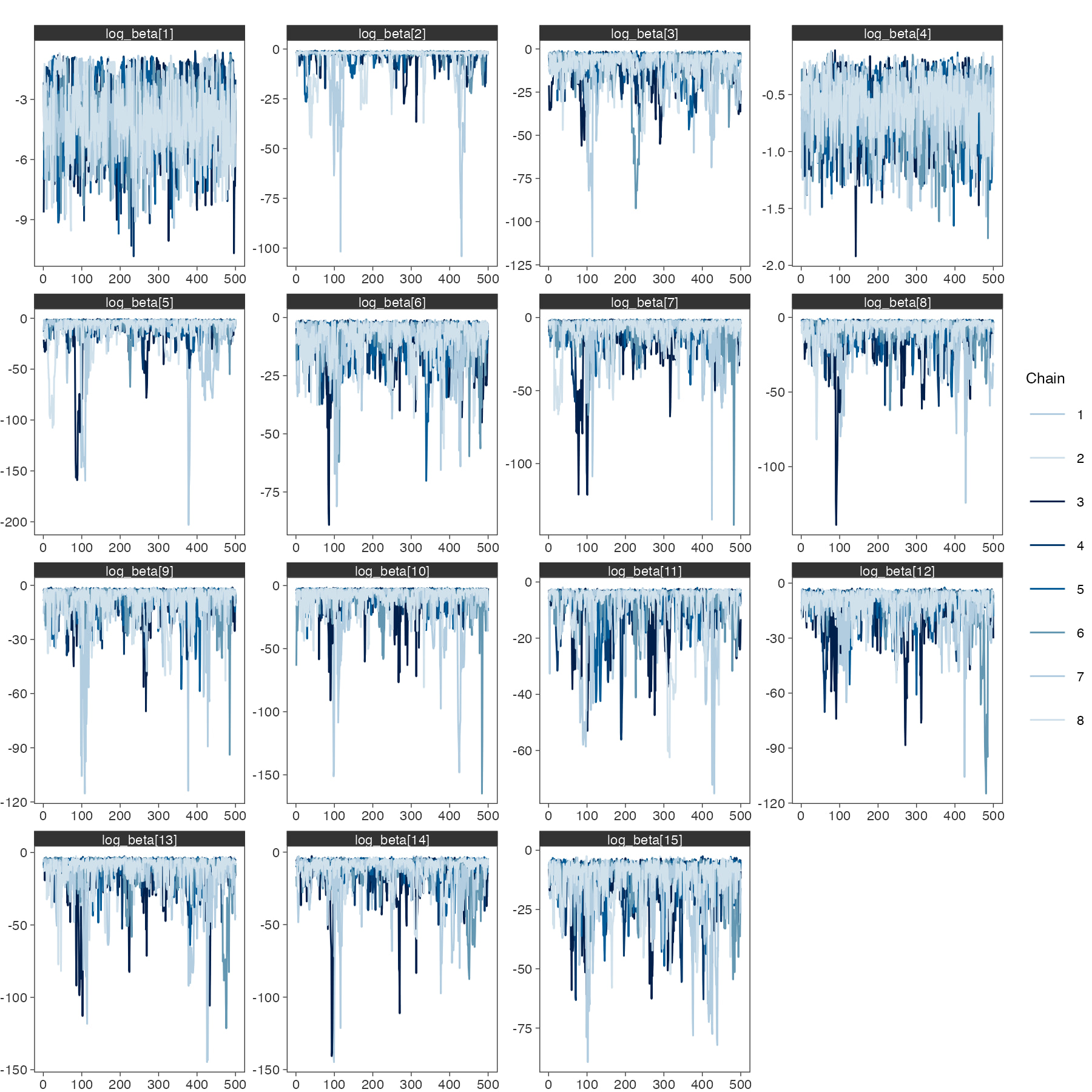
Thank you, that works for me as well. I think it’s coming down to the initial values, perhaps. Below is the Stan program I’m using it for, a Jolly-Seber mark-recapture model, with the definitions happening in transformed parameters. When I place a Dirichlet prior over beta with concentration parameters alpha, I get the horrible behaviour shown above. When I set alpha = ones_vector(J), mixing is much better but still horrible. So, I’m guessing the issue is that u is getting initialised and it’s yielding a horrible simplex beta. However, when I produce the simplex manually like you’ve done, the mixing is fine. So somewhere there’s a difference between the manual approach and the simplex_jacobian approach.
functions {
#include ../stan/util.stanfunctions
#include ../stan/js.stanfunctions
#include ../stan/js-rng.stanfunctions
}
data {
int<lower=1> I, J; // number of individuals and surveys
vector<lower=0>[J - 1] tau; // survey intervals
array[I, J] int<lower=0, upper=1> y; // detection history
int<lower=1> I_aug; // number of augmented individuals
int<lower=0, upper=1> dir, // logistic-normal (0) or Dirichlet (1) entry
intervals; // ignore intervals (0) or not (1)
}
transformed data {
int I_all = I + I_aug, Jm1 = J - 1;
array[I, 2] int f_l = first_last(y);
vector[Jm1] tau_scl = tau / mean(tau), log_tau_scl = log(tau_scl);
}
parameters {
real<lower=0> h; // mortality hazard rate
vector<lower=0, upper=1>[J] p; // detection probabilities
real<lower=0> mu; // concentration parameters or logistic-normal scale
vector[Jm1] u; // unconstrained entries
real<lower=0, upper=1> psi; // inclusion probability
}
transformed parameters {
vector[J] log_alpha = dir ?
rep_vector(log(mu), J)
: append_row(0, mu * u);
if (intervals) {
log_alpha[2:] += log_tau_scl;
}
// this approach doesn't work well
vector[J] log_beta = dir ?
log(simplex_jacobian(u))
: log_softmax(log_alpha);
// this works well
vector[J] log_beta;
if (dir) {
vector[J] z = sum_to_zero_constrain(u);
real r = log_sum_exp(z);
log_beta = z - r;
jacobian += 0.5 * log(J);
jacobian += sum(z) - J * r;
} else {
log_beta = log_softmax(log_alpha);
}
real lprior = gamma_lpdf(h | 1, 3) + beta_lpdf(p | 1, 1)
+ gamma_lpdf(mu | 1, 1);
}
model {
vector[Jm1] log_phi = -h * tau;
vector[J] logit_p = logit(p);
tuple(vector[I], vector[2], matrix[J, I], vector[J]) lp =
js(y, f_l, log_phi, logit_p, log_beta, psi);
target += sum(lp.1) + I_aug * log_sum_exp(lp.2);
target += lprior;
target += dir ?
dirichlet_lupdf(exp(log_beta) | exp(log_alpha)) // ones_vector(J) works OK
: std_normal_lupdf(u);
}
generated quantities {
vector[I] log_lik;
array[J] int N, B, D;
int N_super;
{
vector[Jm1] log_phi = -h * tau;
vector[J] logit_p = logit(p);
tuple(vector[I], vector[2], matrix[J, I], vector[J]) lp =
js(y, f_l, log_phi, logit_p, log_beta, psi);
log_lik = lp.1;
tuple(array[J] int, array[J] int, array[J] int, int) latent =
js_rng(lp, f_l, log_phi, logit_p, I_aug);
N = latent.1;
B = latent.2;
D = latent.3;
N_super = latent.4;
}
}