The Short Story
I have written a multilevel model that includes normal and gamma distributions, and it does really well at retrodicting (i.e. recovering) the “true” parameters from simulated data. However, for one parameter is does a bad job at retrodiction. No matter what the true parameters are in the simulated data, the estimator is too high. This is not a result of overinformative priors, nor the result of lower-level estimators. Therefore, there is some kind of “bias” or consistent error in my Bayesian estimator, and I don’t know how to approach fixing it. I would love some help or references to literature on the subject to try to resolve this. Thank you!
The Longer Story
I am looking at the calls that individual frogs in a population make to understand how they are distributed for an evolutionary model. Each frog has a repertoire—a normal distribution of frequencies—which is parameterized by a peak frequency (the mean of the normal distribution, \overline x) and a repretoire width (the standard deviation of the normal distribution, s). I am trying to derive parameters that describe the population’s distribution of repertoire parameters. If the model were very simple, this would be the mean and standard deviation of each of the peak and width of frog repertoires (i.e. a bivariate normal distribution). However, because s must be positive, we have to use gamma distributions in the place of normal distributions, and this makes life a bit harder.
I have the following model:
x_i\sim\mathcal N(\overline x_{\textrm{frog}[i]}, s_{\textrm{frog}[i]}) // The calls produced by a frog follow that frog’s inherent normal distribution
\overline x_j\sim\mathcal N(\mu, \sigma) // The peak frequencies of frog repertoires in the population follows a normal distribution with a mean \mu and standard deviation \sigma
s_j\sim\mathcal G(\gamma, \gamma/\nu) // The widths of frog repertoires in the population follow a gamma distribution with shape \gamma and rate \gamma/\nu — the mean of this distribution is \nu, and the standard deviation of this distribution is \nu/\sqrt{\gamma}.
The main issue I’m facing is that the model retrodicts \gamma incredibly well, but totally whiffs it for \nu. Here’s a plot of the posteriors for each population (all populations are fit independently in a single MCMC run).

And as I move the true values of \nu that go into the simulated data, the posteriors move so that they are just too far right of the “true” values.
What’s strange is that it also does really well for s, which is the “data” that goes into fitting \nu and \gamma:

I suppose on some level this makes sense, because \gamma would not be fit well if s were not fitting well.
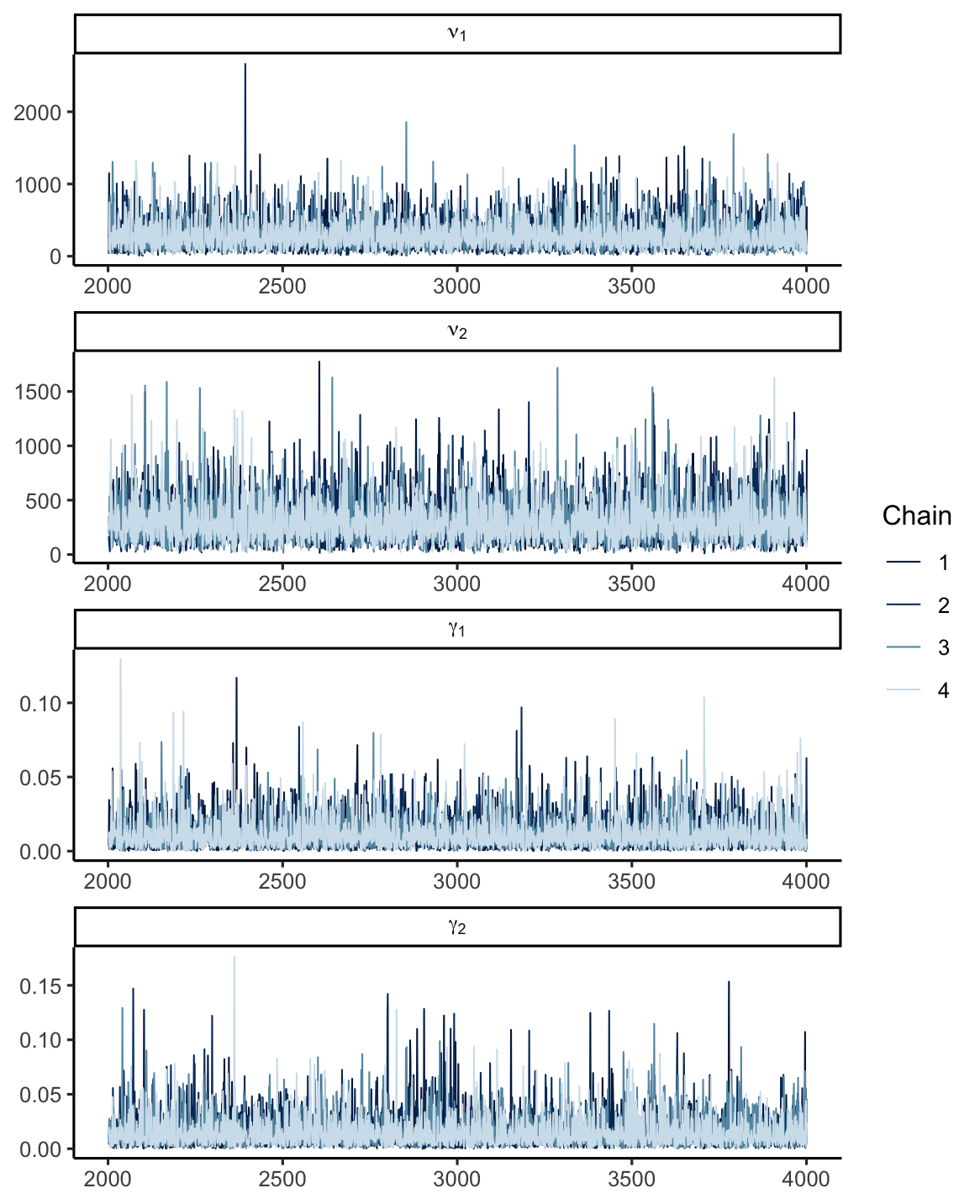
The traceplots look good:

And the density overlays are all similar:

Autocorrelation seems weirdly high in \mu and \sigma (which is concerning), but for \nu which actually faces tangible fitting problems, and for \gamma, autocorrelation drops off quickly:

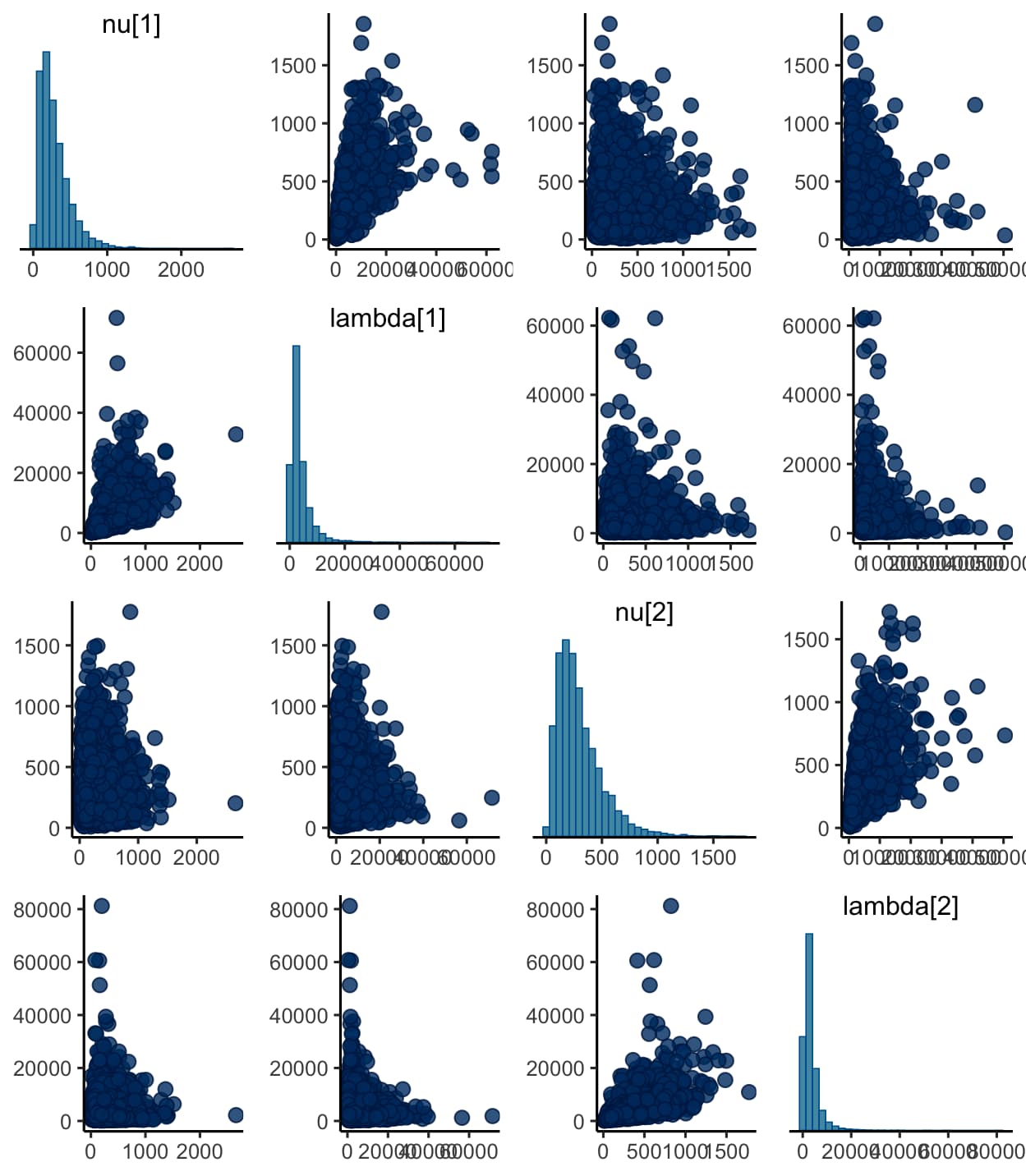
A pairwise correlation plot for each variable shows that each parameter is explored independently of all others.
I wondered if this was happening because s of \gamma were too low at the beginning of the chains, and thus this was causing \textbf P(\nu|\gamma, s)\propto\exp(-\gamma s/\nu) values too be too high for larger values of \nu. So I ran my chains for 6k iterations with 3k warmup, and it didn’t change anything.
In case it makes a difference, I’m running my analyses with adapt_delta=0.975 and max_treedepth=12. Thank you in advance for any of your ideas! And I’m happy to include any more information you’d like as well.
data {
int nCall; // number of calls
int nFrog; // number of frogs
int nPopulation; // number of populations
array[nCall] int frog; // group indicator for frogs
array[nFrog] int population; // group indicator for populations
vector[nCall] x; // peak frequency of each call
}
parameters {
vector[nPopulation] mu; // Population average of peak
vector<lower=0>[nPopulation] sigma; // Population std of peak
vector<lower=0>[nPopulation] nu; // Population average of width
vector<lower=0>[nPopulation] gamma; // Population std of width
vector[nFrog] xbar_raw; // Frog peaks
vector<lower=0>[nFrog] s; // Frog widths
}
transformed parameters {
vector[nFrog] xbar;
for (j in 1:nFrog)
xbar[j] = mu[population[j]] + sigma[population[j]] * xbar_raw[j]; // Non-centered parameterization of xbar
}
model {
// Population-level parameters
mu ~ normal(4500, 300);
sigma ~ gamma(4, 0.01); // mean = 400, std dev = 200
nu ~ gamma(1.56, 0.006); // mean = 275, std dev = 225
gamma ~ gamma(1.6, 0.5); // gives lambda = nu/sqrt(gamma)
// mean 200 and std dev 100
// Individual-level parameters
xbar_raw ~ normal(0, 1);
for (j in 1:nFrog)
s[j] ~ gamma(gamma[population[j]], gamma[population[j]]/nu[population[j]]);
// Call-level likelihood
x ~ normal(xbar[frog], s[frog]);
}
generated quantities {
vector[nPopulation] lambda;
for (k in 1:nPopulation)
lambda[k] = nu[k]/sqrt(gamma[k]); // The standard deviation of s ~ gamma(gamma, gamma/nu)
}