Hi everyone,
I struggle with building a hierarchical model when my data is in long format. Here some example data:
ID | Object | Outcome | Statement | Value
---|--------|---------|-----------|------
1 | A | 5 | X | 3
1 | A | 5 | Y | 2
1 | A | 5 | Z | 1
1 | B | 3 | U | 5
1 | B | 3 | V | 4
1 | B | 3 | X | 3
2 | C | 2 | U | 1
2 | C | 2 | X | 2
2 | C | 2 | Y | 2
2 | A | 1 | X | 3
2 | A | 1 | Y | 4
I have different objects and some set of statements, fixed for each object. Participants responded to these statements (Value) and gave an overall rating for the object (Outcome). Participants saw a random subset of all available objects (e.g. participant 1 saw A and B, participant saw A and C). Some statements are shared between the objects (e.g., X is asked for all objects, V is unique to B).
My model should predict Outcome based on available Statement-level ratings. The no-pooling model using “wide format” data would be (in R formula notation):
Outcome_A ~ Statement_X + Statement_Y + Statement_Z
But my thinking was, that a multilevel model makes so much more sense, because it can (a) regularize my estimates and (b) we can learn from all the ratings (e.g. it is unlikely that the effect of X rating is so very different for object A compared to B).
In a first attempt I used brms to build the model:
m1 <- brm(Outcome ~ 1 + (1 | ID) + (0 + Value | Statement:Object), data = df_mlm,
family = cumulative("logit"), chains = 2)
The posterior predictive checks are looking very good for two different datasets (one shown below).
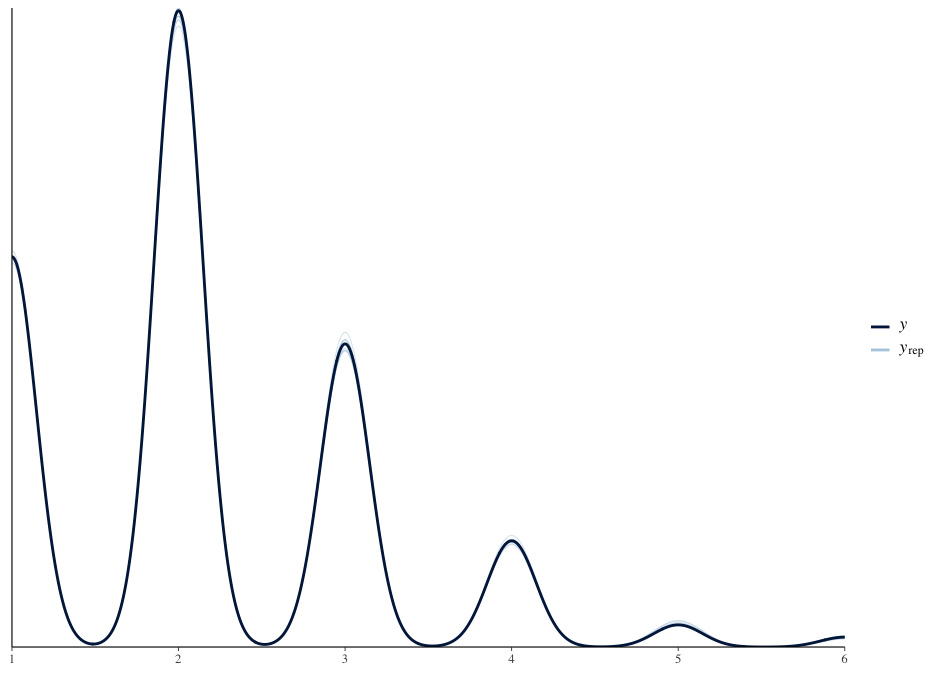
Looking at the coefficients for Value tells me that there is something wrong with the model: While for some objects, all coefficients for the Statements are around 1.0 while they are around 0.0 for all Statements of another Object (“Detail” in the plot should be Statement, y-axis is coefficients for Value).
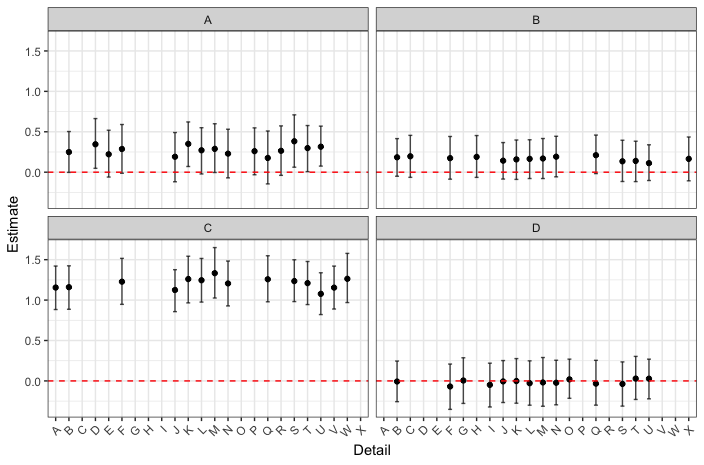
My first thought was to add a random intercept for Object. This however leads to divergent transitions and Rhat > 1.1.
In general, I don’t trust these results, but wonder how to properly specify this model. Does the model take the ratings by a single participants properly into account?
This is likely to be a trivial problem and might be primarily related to the fact that I have data in long format. So, there should be a simple solution. Unfortunately, I wasn’t able to find something online yet. Looking forward for some wisdom…
Many thanks
Christopher