Hi everyone!
I’m relatively new to Bayesian modeling, and I was hoping to get some insights into my approach.
I have a dataset of ratings, where people are asked to make binary choices about a given stimulus. They make many ratings about each stimulus over the course of an experiment, resulting in a continuous, average percent chosen variable that is bound between 0 and 1 (PercentChosen). I am interested in exploring how features about the stimulus (Stimulus) and the condition (Condition) that people were assigned to influence their average proportion of ratings. There are 21 different pairs of stimuli (Pair) and 57 participants (Participant) in this dataset. Stimulus is a continuous numeric variable, Condition is a factor with two levels (Friend, Rival), Pair is a factor with 21 levels, and Participant is a factor with 57 levels.
Please see my full brms model below:
brm(PercentChosen ~ Stimulus * Condition + (Condition|Pair) + (Condition|Participant),
data = df,
prior = c(prior(normal(0,10), class = "b"),
prior(cauchy(0,5), class = "sd"),
prior(normal(0.5,1), class = "Intercept")),
family = Beta(link = "logit"),
iter = 10000,
warmup = 2000,
init = 0,
chains = 4,
cores = 6)
Here is the model summary I get:
Family: beta
Links: mu = logit; phi = identity
Formula: PercentChosen ~ Stimulus * Condition + (Condition | Pair) + (Condition | Participant)
Data: df (Number of observations: 9500)
Draws: 4 chains, each with iter = 10000; warmup = 2000; thin = 1;
total post-warmup draws = 32000
Group-Level Effects:
~Pair (Number of levels: 21)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.71489 0.12139 0.52183 0.99565 1.00095 6334 11065
sd(ConditionA) 1.24624 0.21052 0.91177 1.73056 1.00112 6247 11241
cor(Intercept,ConditionA) -0.97654 0.01324 -0.99278 -0.94268 1.00057 9074 15853
~Participant (Number of levels: 57)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.01371 0.01070 0.00050 0.03988 1.00017 26272 17285
sd(ConditionA) 0.02098 0.01625 0.00081 0.06054 1.00019 23371 17556
cor(Intercept,ConditionA) -0.16661 0.57854 -0.97376 0.93088 1.00006 45602 22570
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 0.01210 0.16454 -0.31312 0.33992 1.00129 3561 6790
Stimulus -0.21907 0.13921 -0.49233 0.05294 0.99993 37531 25153
ConditionA -0.11456 0.28352 -0.67777 0.44660 1.00123 3673 7099
Stimulus:ConditionA 0.58161 0.19753 0.20340 0.96824 1.00014 38952 26825
Family Specific Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
phi 0.92056 0.01099 0.89916 0.94206 1.00002 73177 22498
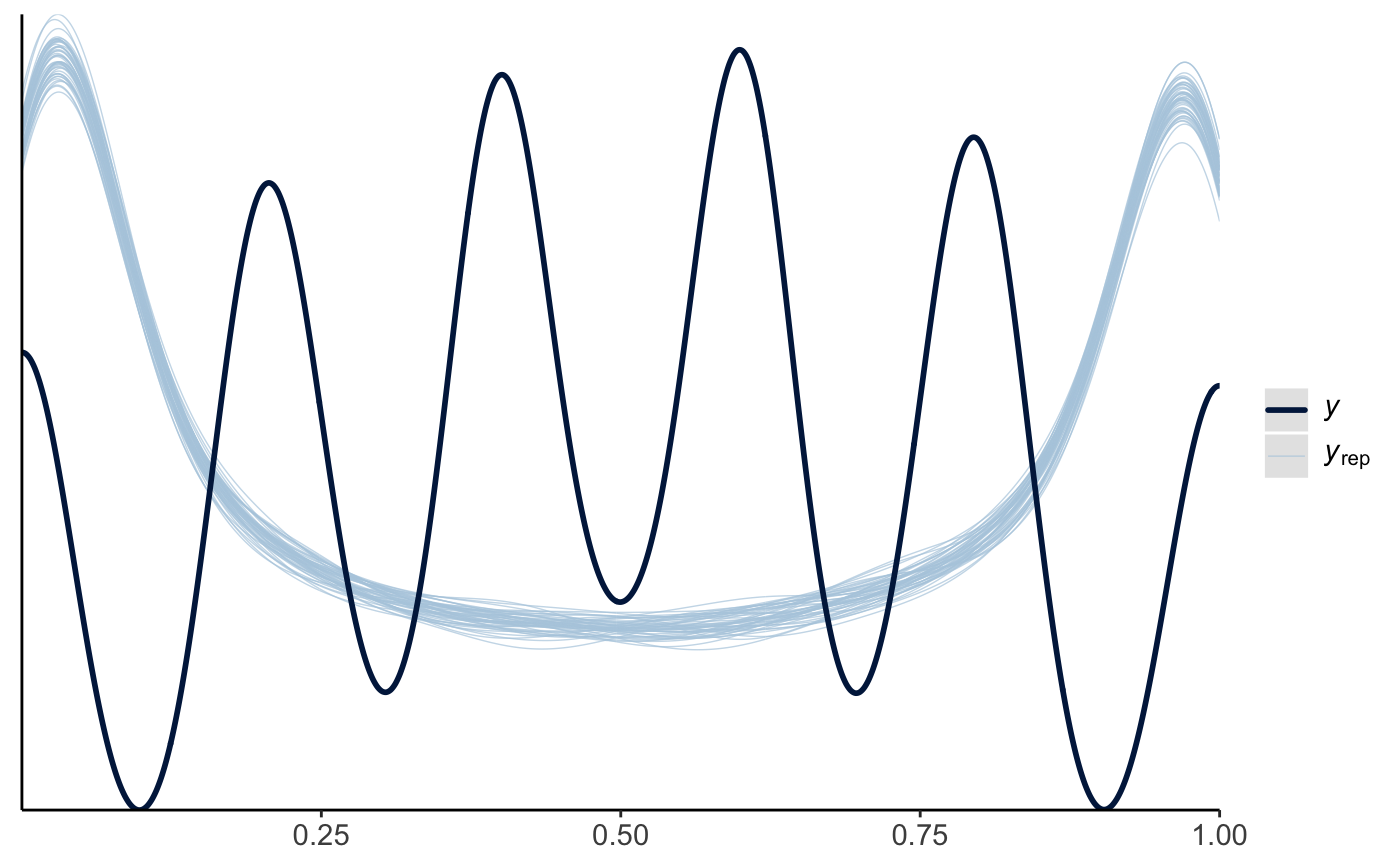
My question comes when I use pp_check() to run posterior predictive checks on this model.
pp_check(model, ndraws = 50)
pp_check(model, "stat_grouped", ndraws = 50, group = "Condition")
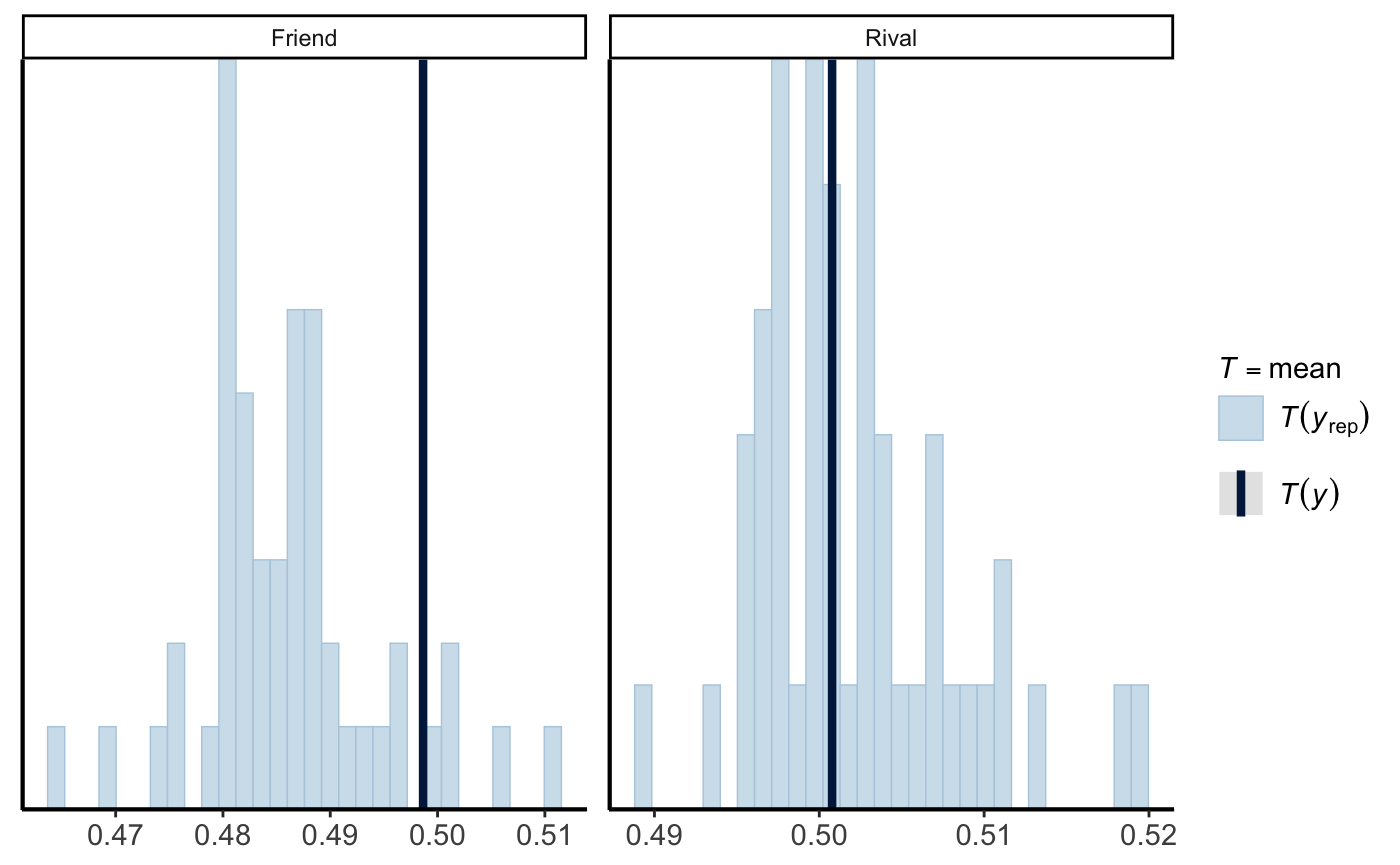
Based on online tutorials that I have been following (namely Causal inference with beta regression | A. Solomon Kurz), it seems like my approach of using the Beta distribution should be appropriate for the bounded (0,1) continuous outcome. However, I’m not sure why there are such differences between the observed data and posterior draws in my pp_check() distribution plots.
Any insights or guidance would be greatly appreciated, thank you!
