Hello,
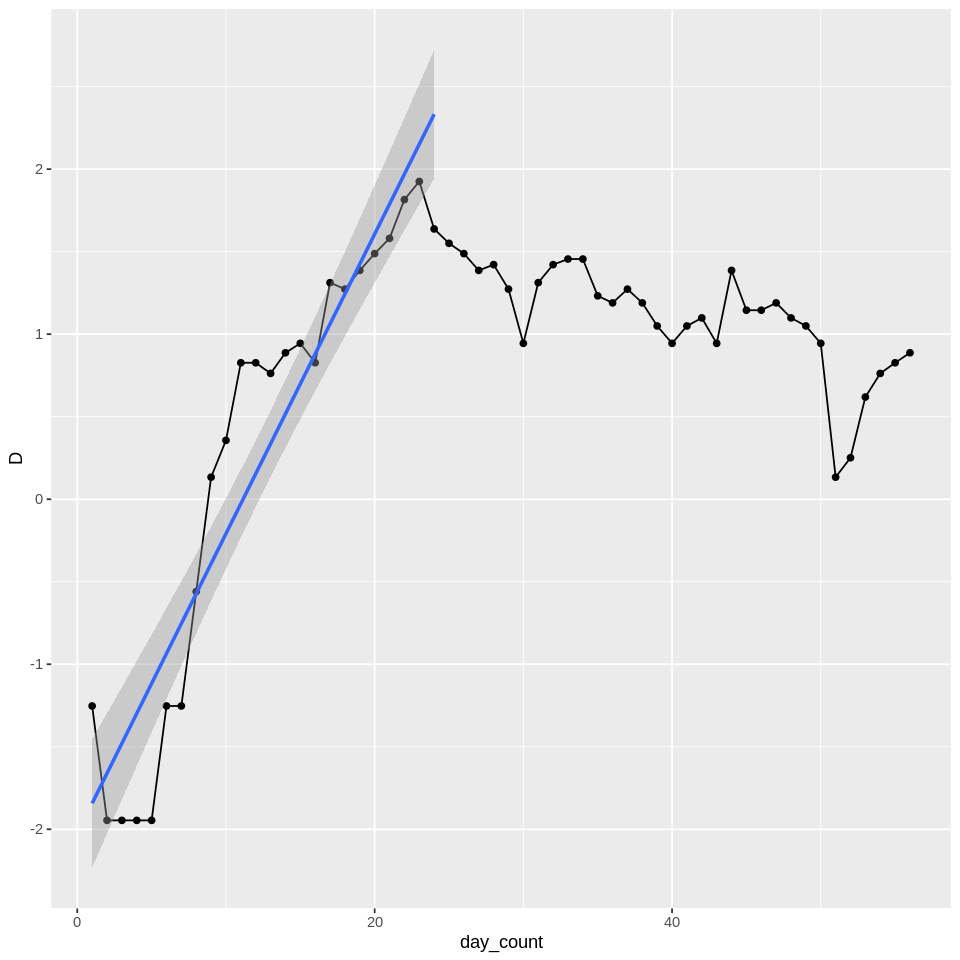
I am new to Stan and I am trying to fit a simple linear model to daily data D, but I want the fit to be only to the initial part of the data that fits the best. In R, I can do this by starting from the first observation and gradually including new observations until the fit worsens. I have included a plot for what I want the fit to look like. Is there a way to do a similar fit in Stan?
I followed the Change Point example in the manual here https://mc-stan.org/docs/2_21/stan-users-guide/change-point-section.html. That example marginalizes the change point, and finds a change point and fits two models: one to the early part of the data and one to the later part. I thought that I can also marginalize the change point and ignore the later part of the data by only computing the log_likelihood for the early part. So, I changed the inner loop to 1:s instead of 1:T so that the data likelihood is only computed up to the change point, but that didn’t work. I am not sure what I am doing wrong. Here is my R and Stan code based on the change point example.
Thanks!
{kind=link}
day_count <- c(1:56)
D <- c(-1.252763,-1.9459101,-1.9459101,-1.9459101,-1.9459101,-1.252763,-1.252763,-0.5596158,0.1335314,0.3566749,0.8266786,0.8266786,0.7621401,0.8873032,0.9444616,0.8266786,1.3121864,1.2729657,1.3862944,1.4880771,1.5804504,1.81529,1.9252909,1.6376088,1.5505974,1.4880771,1.3862944,1.4213857,1.2729657,0.9444616,1.3121864,1.4213857,1.4552872,1.4552872,1.2321437,1.1895841,1.2729657,1.1895841,1.0498221,0.9444616,1.0498221,1.0986123,0.9444616,1.3862944,1.1451323,1.1451323,1.1895841,1.0986123,1.0498221,0.9444616,0.1335314,0.2513144,0.6190392,0.7621401,0.8266786,0.8873032)
test <- list(T = length(day_count),
day_count = day_count,
D = D)
fit <- stan(file = 'best_fit.stan', data = test, chains = 1)
data {
int<lower=1> T;
vector[T] day_count;
real D[T];
}
transformed data {
real log_unif;
log_unif = -log(T);
}
parameters {
real<lower=0> sigma;
real a0;
real<lower=0> a1;
}
transformed parameters {
vector[T] mu = a0 + a1 * day_count;
vector[T] lp;
lp = rep_vector(log_unif, T);
for (s in 1:T)
for (t in 1:s)
lp[s] = lp[s] + normal_lpdf(D[t] | mu[t], sigma);
}
model {
target += log_sum_exp(lp);
}
{kind=link}