Hi,
While building models and trying out different priors, I noticed that using a prior that seemed more sensible based on my sensitivity analysis decreased my loo performance. The old prior, the one before the sensitivity analysis, also seems to sample slightly better.
Would it be correct to go with the old priors based on those facts, even though the sensitivity analysis made the new priors seem like a better choice?
I put the brms code for both models below.
old.priors = brm(
formula = EXAM ~ 1 + Weighting + LOC + (1|Project),
data = ls.df,
family=Beta(),
prior = c(
prior(normal(0,10), class=Intercept),
prior(normal(0,0.5), class=b),
prior(cauchy(0,0.5), class=sd),
prior(gamma(0.1, 0.1), class=phi)
)
)
new.priors = brm(
formula = EXAM ~ 1 + Weighting + LOC + (1|Project),
data = ls.df,
family=Beta(),
prior = c(
prior(normal(0,1), class=Intercept),
prior(normal(0,0.05), class=b),
prior(cauchy(0,0.05), class=sd),
prior(gamma(0.1, 0.1), class=phi)
)
)
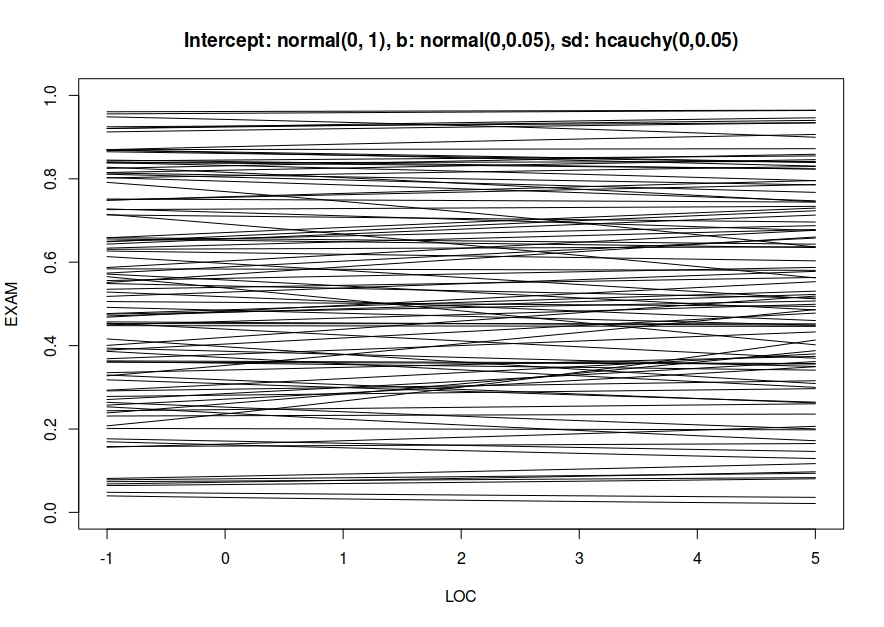
One guess is that my prior sensitivity analysis is not correct. I tried following McElreath’s book but I didn’t find examples for how to do it for varying intercepts so I tried to come up with something myself.
If I understand it right, I might have to make multiple plots (or multidimensional plots, one for each parameter) so maybe that is my error?
sensitivity<- function(intercept, parameters, var_intercepts) {
N = 100
b_intercept = rnorm(N, 0, intercept)
b_weighting = rnorm(N, 0, parameters)
b_loc = rnorm(N, 0, parameters)
m_project = rhcauchy(N, var_intercepts)
b_project = rep(0, N)
for (i in 1:N) {
b_project[i] = rnorm(1, m_project, intercept)
}
for (w in 0:1){
plot(NULL, xlim = c(-1, 5), ylim = c(0, 1))
for (i in 1:N) {
curve(exp(b_intercept[i] + b_weighting[i] * w + b_loc[i] * x + b_project[i]) / (
1 + exp(b_intercept[i] + b_weighting[i] * w + b_loc[i] * x + b_project[i])
) ,
add = TRUE)
}
}
}
sensitivity(10, 10, 10)
...