I was running some prior predictive checks, and trying to confirm my intuition (and something also noted in Statistical Rethinking) that if you specify a regression model in the form: value ~ 1 + gender, that if ‘man’ is the reference group, the prior for ‘women’ will indicate greater uncertainty than for men (because it is estimated by adding the intercept and the b_genderwomen parameters together, which is naturally more uncertain than just the b_Intercept parameter alone).
However, when doing a prior predictive check on this I was surprised that this was not the case, although running a prior predictive check on a model of the form value ~ 0 + gender suggested that the intercepts in this model would be generally a small amount more certain than those for the 1 + gender model (width is the width of the 95% HDI, indicating the uncertainty):

I decided to follow this up by just pulling out the parameter estimates and adding them together, and found that in cmdstanr, for the 1+ gender version of the model, the posterior draws include not only b_Intercept but also just Intercept:
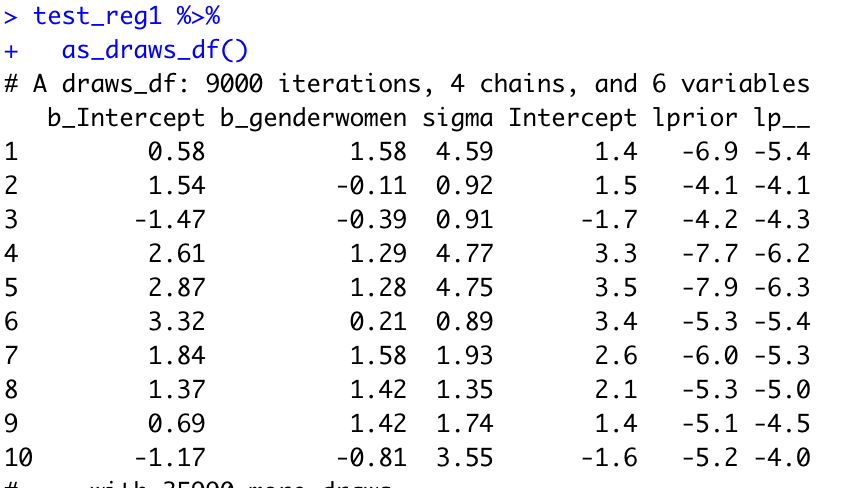
I haven’t seen this before and found it very strange. If I manually add the different intercepts to the b_genderwomen parameter I get the following:

I don’t really understand what is going on here - the values from posterior_epred match b_Intercept + b_genderwomen but I don’t understand how adding one uncertain thing to another can come out the same as just the one uncertain thing, and I really don’t know why this extra Intercept parameter has come up. Running the model without cmdstan means that the Intercept is no longer in the as_draws output, but the posterior_epred values are the same. Can anyone explain what is going on here? In the priors, there was a negative correlation between the b_Intercept and b_genderwomen so I guess they may in some way be ‘trading off’ against one another in some fashion, but it still doesn’t match my expectations.
My expectation would have been that the value for the intercept (men) would have been more certain than for women in the 1 + gender model, and that in the 0 + gender model, the uncertainty for men and women would have been the same, and similar to the intercept in the 1 + gender model.
All the code below to try this out can be run quickly and is pasted below, and any thoughts/explanations would be greatly appreciated!:
library(brms)
library(tidyverse)
library(tidybayes)
test <-
tibble(men = rnorm(1000),
women = rnorm(1000, 1)) %>%
pivot_longer(cols = everything(),
names_to = "gender")
priors_1 <- c(set_prior("normal(0 , 2)", class = "Intercept"),
set_prior("normal(0 , 1)", class = "b"),
set_prior("normal(1 , 2)", class = "sigma"))
test_form1 <- value ~ 1 + gender
get_prior(test_form1,
test,
gaussian)
test_reg1 <-
brm(formula = test_form1,
family = gaussian(),
data = test,
control = list(adapt_delta = 0.99, max_treedepth = 15),
prior = priors_1,
chains = 4,
cores = 4,
iter = 10000,
warmup = 1000,
sample_prior = "only",
backend = 'cmdstanr',
threads = threading(4),
seed = 1010,
stan_model_args=list(stanc_options = list('O1'))
)
test_form2 <- value ~ 0 + gender
priors_2 <- c(set_prior("normal(0 , 2)", class = "b", coef = "gendermen"),
set_prior("normal(0 , 2)", class = "b", coef = "genderwomen"),
set_prior("normal(1 , 2)", class = "sigma"))
test_reg2 <-
brm(formula = test_form2,
family = gaussian(),
data = test,
control = list(adapt_delta = 0.99, max_treedepth = 15),
prior = priors_2,
chains = 4,
cores = 4,
iter = 10000,
warmup = 1000,
sample_prior = "only",
backend = 'cmdstanr',
threads = threading(4),
seed = 1010,
stan_model_args=list(stanc_options = list('O1'))
)
post_1 <- posterior_epred(test_reg1,
newdata = tibble(gender = c("men", "women"))) %>%
as_tibble() %>%
rename(men = V1,
women = V2) %>%
pivot_longer(cols = everything(),
names_to = "gender")
post_2 <- posterior_epred(test_reg2,
newdata = tibble(gender = c("men", "women"))) %>%
as_tibble() %>%
rename(men = V1,
women = V2) %>%
pivot_longer(cols = everything(),
names_to = "gender")
summarised <-
bind_rows(post_1 %>% mutate(type = "value: 1 + gender"),
post_2 %>% mutate(type = "value: 0 + gender")) %>%
group_by(type, gender) %>%
summarise(width = abs(hdi(value)[1] - hdi(value)[2]))
test_reg1 %>%
as_draws_df()
summarised_2 <-
test_reg1 %>%
as_draws_df() %>%
as_tibble() %>%
mutate(`b_Intercept + b_genderwomen` = b_Intercept + b_genderwomen,
`Intercept + b_genderwomen` = Intercept + b_genderwomen) %>%
select(Intercept,
b_Intercept,
b_genderwomen,
`b_Intercept + b_genderwomen`,
`Intercept + b_genderwomen`) %>%
pivot_longer(cols = everything(),
names_to = "gender") %>%
group_by(gender) %>%
summarise(width = abs(hdi(value)[1] - hdi(value)[2]))
