I was wondering if you would have some resources on codes or math representation for the below scenario.
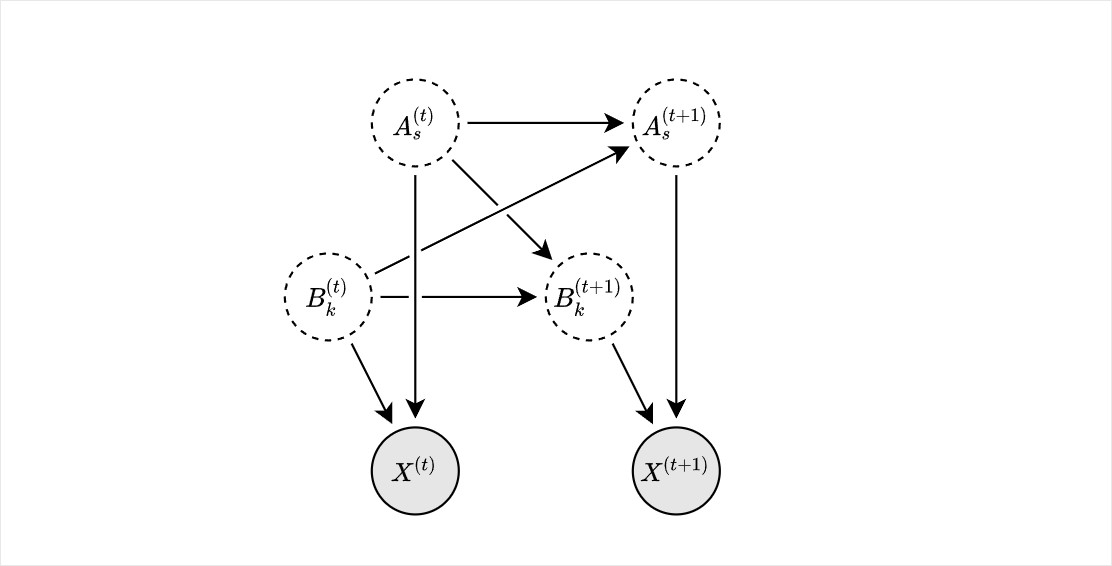
Where the X node are the observed variables, A_{s}^{(t)} and B_{k}^{(t)} are the nodes representing the hidden state for A and B at time t, where s \in \{1, ..., S\}, k \in \{1, ..., K \}. Many HMM examples (Stan codes and math representation) are usually for one hidden state node. However, in the figure below a hidden state node depends on the other hidden state.
Can anyone direct me to some materials or codes around this model? Also, any idea on what this type of HMM is called?
It looks to me that the only difference from the typical scheme is that the state is shown as separate nodes; you could instead show it as a single node with two components A = (a_1, a_2) and it would look like a regular Hidden Markov Model with one hidden node.
I’m not sure how common this is in HMMs, but in the general state-space formulation there would normally be vector-valued states, which could also take continuous values instead of discrete (I came across a model that I thought of formulating as an HMM but couldn’t really figure out how and I ended up concluding that it was worth thinking of it as a general state-space model). The advantage of this is that it is general.
The advantage of the former is you can compute a closed-form likelihood and inference should be a lot easier. I’m guessing you can write down the (Markovian) update step and work out the recursion to get: P(X) = \sum_A P(X|A) P(A), you will just have more state possibilities to sum over. I’d be curious to see if this works out if you carry it through.
@caesoma is spot on. Just to rephrase it in a slightly different way, the model you’ve shown is equivalent to a HMM with a single hidden state variable that allows for S \times K states. Since there is a dependency between the A and B processes, I fear that this explosion of states is inevitable - you have to consider all the pairwise combinations of states to compute the likelihood. If A and B were independent it would be a factorial HMM and there is some reasearch (which I didn’t read) claiming to be able to avoid the explosion of states when independence is assumed: Factorial Hidden Markov Models | SpringerLink ; https://emilemathieu.fr/files/fhmmreport.pdf but from a quick glance, I am unsure it can be translated to Stan as it discusses Gibbs sampling and Expectation-Maximization algorithms, but not a faster equivalent of the forward algorithm.
I’ll also note that @vianeylb is probably the best person to ask about HMMs in Stan.
I might try combining the two components like what @caesoma mentioned if the state combinations are not too large to deal with.
@martinmodrak I got another idea from your suggestion around factorial HMM if the state combinations become too large. I try modelling the A and B process as independent, which directly influences an observation, which in turn influences the states in the next time slice. So the transition matrices for A and B are varying with time. This will make the two different processes having indirect influence on each other.
@vianeylb your published work around HMMs in Stan is on my reading list :)
Just here to agree with @caesoma and @martinmodrak’s fabulous advice. There are factorial HMMs and your structure almost reminded me of coupled HMMs as well (although there would be more than one observation process for these). Writing out the expanded state space with all combinations of states would be a good step, to see if you can come up with some clever way of writing the transition probability matrix in a concise way. Without knowing too much about the application, I’d keep in mind also how well you might be able to identify the two latent processes using only one observation process, unless it was multivariate. Sounds like an exciting application.
It might be clearer to say that the processes have no influence on each other, but if the observed value X depends on both the latent states of A and B, that learning information about the possible state of process A through X also gives you information about the state of process B, and vice versa.
If A and B are independent Markov processes, then the state of A at time t+1 should depend only upon the state of A at the prior time t and the transition matrix for A, it should not depend upon other things such as the observation X^{(t)}, or the state of B at time t. So in this sense the two processes would be unrelated.
If two independently evolving Markov processes A and B each contribute toward some observation X that gives information about both of their states, then the conditional distributions of A and B given X become coupled, i.e. you have to work with the full joint conditional distribution over the product space A \times B.