I am fitting brms models on duration data representing the number of days of delay in paying invoices from the expiration date (negative values represents advance payments). The data consists of some exploratory variables such as the customer, invoice amount, revenue type, expiry month, ecc.
The main goal is to do predictions, but instead of a point estimate I need a reliable probability distribution of the outcome (i.e. days of delay) on new invoices, that’s why I am using Bayesian tools.
I removed from the training set observations having values for the outcome variable in the first and the last decile since they complicate the estimation process bringing the models to return worse forecasts on new invoices in the test set. After doing this the response variable ranges from -15 to 103.
This is the initial distribution of the outcome, as you can see it is bimodal:

Below is the distribution of the response on the data that I am using to fit the models.
As I said before, I removed data where the response takes values < -15 or >103 (1st and 9th deciles).

Since the distribution is positively skewed and has a lot of over-dispersion (mean is ~15.4, variance is 437), as a purely practical matter I tried to model the data with Negative Binomial, even if I don’t have count data.
In order to to this I had to make all the values of the outcome greater or equal to 0 removing the minimum observed value (-15).
blm_nb_2_prior <- c(set_prior("normal(0,1)", class = "b"),
set_prior("normal(0,10)", class = "Intercept", coef = ""),
set_prior("exponential(1)", class = "shape"))
blm_nb_2 <- brm(ritardo ~ ., data = train_juiced_shift, family = negbinomial(), prior = blm_nb_2_prior)
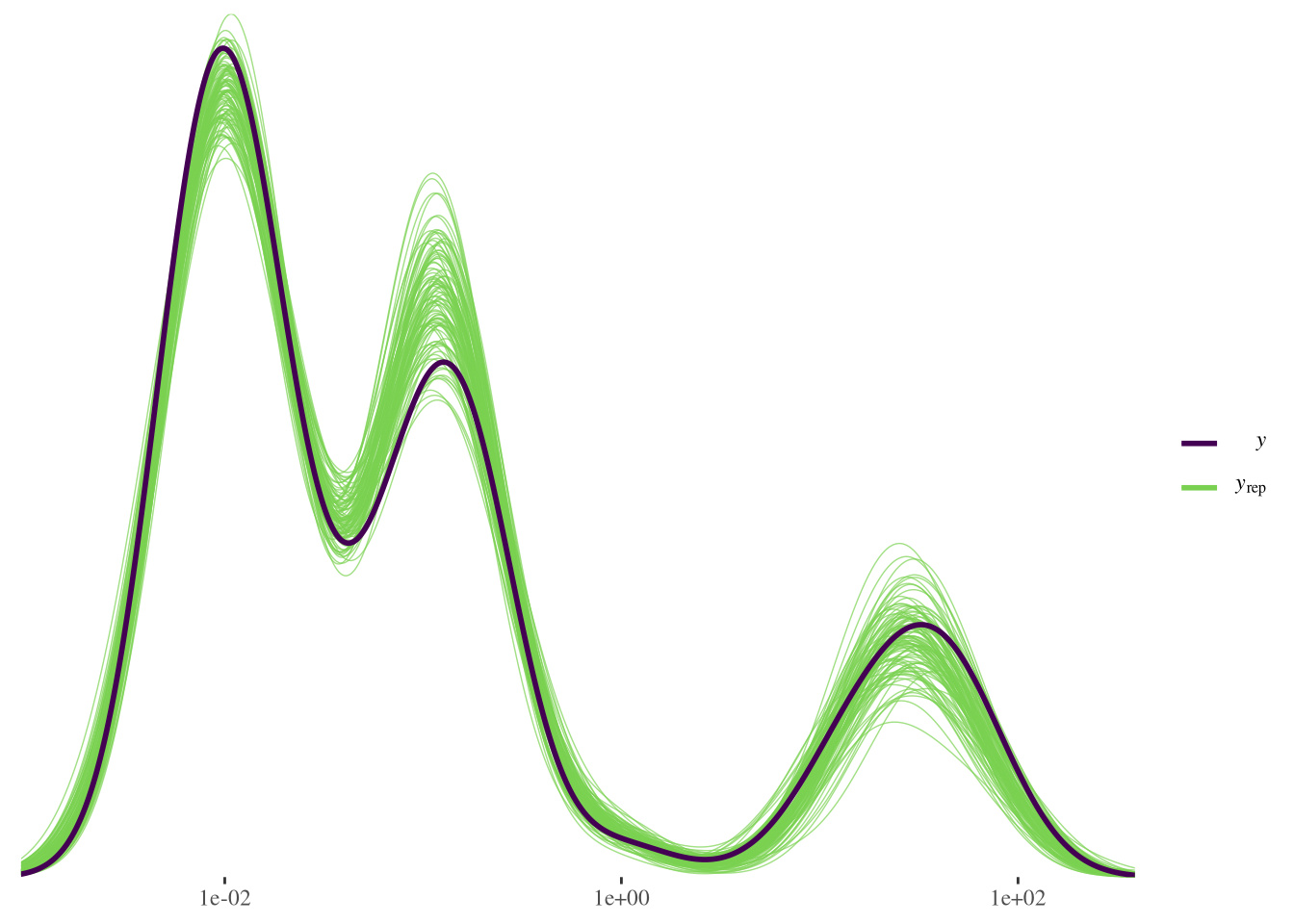
Below posterior predictive checks:

I also tried Weibull regression, which should be more suitable for time-to-event data:
brm(ritardo ~ ., family = weibull(), data = train_juiced_shift_2, chains = 4, cores = 4)

Loo comparison suggests Negative Binomial model is the best of the 2:
elpd_diff se_diff
blm_nb_2 0.0 0.0
blm_w -226.1 12.1
To evaluate the effectiveness of the models on new data (not used to train the models and including those with the outcome variable taking “extreme” values i.e. inside the first or last decile), I also computed performance indicators such as RMSE, MAE, MDAE on the test set (comparing the median of the posterior distributions on the original scale with the actual values). According to this analysis, the best model among the 2 still is the NB, but the difference is small.
I ask you if is there is another model family that I could try that might work better on these duration data, maybe better suited to bimodal data and/or that can be fitted on the original data or removing less than 20% of observations having extreme values.