Dear BRMS community,
I have been trying to build a simple tutorial to show how shrinkage works in a multilevel model for my collaborators. Using @Solomon 's brms example from Chapter 13 “Multilevel tadpoles”, I’ve discovered the shrinkage does not appear to always be towards the fixed effect. A reprex is below:
Original example is model 13.2.2 taken from here: 13 Models With Memory | Statistical rethinking with brms, ggplot2, and the tidyverse: Second edition
The tadpole data involves estimating survival probabilities of tadpoles in 60 different ponds.
library(tidyverse)
library(brms)
# Create data parameters
a_bar <- 1.5 # average log odds of survival for all ponds
sigma <- 1.5
n_ponds <- 60
ni <- rep(c(5, 10, 25, 35), each = n_ponds / 4) %>% as.integer() # n per pond
set.seed(5005)
a_pond <- rnorm(n = n_ponds, mean = a_bar, sd = sigma) # log odds survival per pond
dsim <-
tibble(pond = 1:n_ponds,
ni = ni,
true_a = a_pond) %>%
mutate(true_p = inv_logit_scaled(true_a))
# Simulate data (survival of tadpoles)
dsim <- dsim %>%
mutate(surv = rbinom(n = n(),
prob = true_p,
size = ni))
# Calculate no pooling estimates
dsim <- dsim %>%
mutate(p_nopool = surv / ni)
# Fit the model
fit <- brm(data = dsim,
family = binomial,
surv | trials(ni) ~ 1 + (1 | pond),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(exponential(1), class = sd)),
iter = 2000, warmup = 1000, chains = 4, cores = 4,
seed = 1)
# conditional effects of each pond
p_partpool <- coef(fit)$pond[, , ] %>%
data.frame() %>%
transmute(p_partpool = inv_logit_scaled(Estimate))
# fixed effect (model estimated average survival)
p_overall <- inv_logit_scaled(fixef(fit))[1,1]
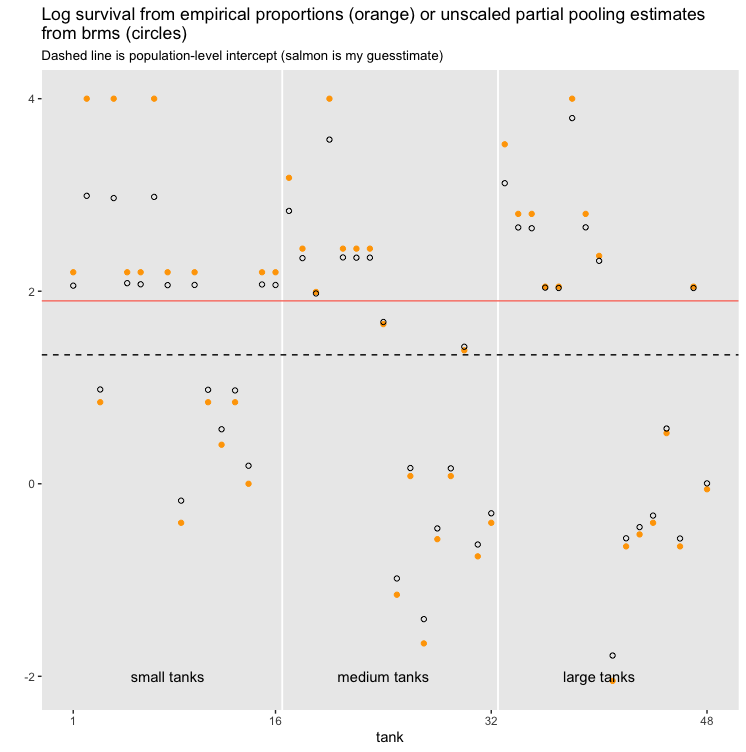
If we then plot the conditional estimates relative to the unpooled estimates, we can see that the estimates are not always shifted (shrunk) towards the fixed effect (dotted line). This is especially clear in small to large ponds where some of the conditional effects (black) fall further away from the dotted line than the unpooled estimates (blue):
dsim %>%
bind_cols(p_partpool) %>%
ggplot(aes(x = pond)) +
geom_vline(xintercept = c(15.5, 30.5, 45.4),
color = "white", size = 2/3) +
geom_point(aes(y = p_nopool), color = "blue") +
geom_point(aes(y = p_partpool), shape = 1) +
geom_hline(aes(yintercept = p_overall),
linetype = "dotted") +
annotate(geom = "text",
x = c(15 - 7.5, 30 - 7.5, 45 - 7.5, 60 - 7.5), y = 1.05,
label = c("tiny (n=5)", "small (n=10)", "medium (n=25)", "large (n=35)")) +
scale_x_continuous(breaks = c(1, 10, 20, 30, 40, 50, 60)) +
labs(title = "Estimates by no pooling (blue) or partial pooling (black)",
subtitle = "Dotted line is estimated overall survival (fixed effect)",
y = "estimate") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.subtitle = element_text(size = 10))
(apologies, but I’m not sure how to add a plot or graphic here but if it is any help then I have a github pages documenting the issue here - see Figure 2 at Partial pooling, where the estimates seem to be shrunk towards a point much higher than the fixed effect)
As an aside, if I fit the same model with lme4::glmer(cbind(surv, ni - surv) ~ 1 + (1 | pond)) then all the conditional effects fall on the correct side of the unpooled estimates.
Thanks for helping me understand shrinkage a bit better,
Rich