I compiled cmdStan with the fix-gamma-lccdf branch of Stan math but am still running into issues when sampling from a Gamma distribution with left-censored data. I consider the following models:
censored_stan_lccdf.stan
data {
int<lower=0> N_obs;
int<lower=0> N_cens;
vector<lower=0>[N_obs] obs;
vector<lower=0>[N_cens] cens;
}
parameters {
real log_alpha_raw;
real log_beta_raw;
}
transformed parameters {
real<lower=0> alpha = exp(log(30) + log_alpha_raw);
real<lower=0> beta = exp(log(1.0 / 3.0) + log_beta_raw);
}
model {
target += normal_lpdf(log_alpha_raw | 0, 1);
target += normal_lpdf(log_beta_raw | 0, 1);
target += gamma_lpdf(obs | alpha, beta);
target += gamma_lccdf(cens | alpha, beta);
}
censored_manual_lccdf.stan
functions {
real gamma_lccdf_manual(real y, real alpha, real beta) {
if (y <= 0) return 0;
return log1m_exp(gamma_lcdf(y | alpha, beta));
}
real gamma_lccdf_manual(vector y, real alpha, real beta) {
real s = 0;
for (n in 1:num_elements(y)) {
s += gamma_lccdf_manual(y[n], alpha, beta);
}
return s;
}
}
data {
int<lower=0> N_obs;
int<lower=0> N_cens;
vector<lower=0>[N_obs] obs;
vector<lower=0>[N_cens] cens;
}
parameters {
real log_alpha_raw;
real log_beta_raw;
}
transformed parameters {
real<lower=0> alpha = exp(log(30) + log_alpha_raw);
real<lower=0> beta = exp(log(1.0 / 3.0) + log_beta_raw);
}
model {
target += normal_lpdf(log_alpha_raw | 0, 1);
target += normal_lpdf(log_beta_raw | 0, 1);
target += gamma_lpdf(obs | alpha, beta);
target += gamma_lccdf_manual(cens, alpha, beta);
}
and simulate data from a Gamma distribution with $$\alpha=30.0$$ and $$\beta=1/3$$ with a censoring threshold of $$T_{censor} = 100.0$$
rng = np.random.default_rng(42)
samples = rng.gamma(shape=30.0, scale=3.0, size=2_000)
is_obs = samples <= 100.0
obs = samples[is_obs].astype(float)
cens = np.full(np.sum(~is_obs), 100.0)
data = {
"N_obs": int(obs.size),
"N_cens": int(cens.size),
"obs": obs,
"cens": cens,
}
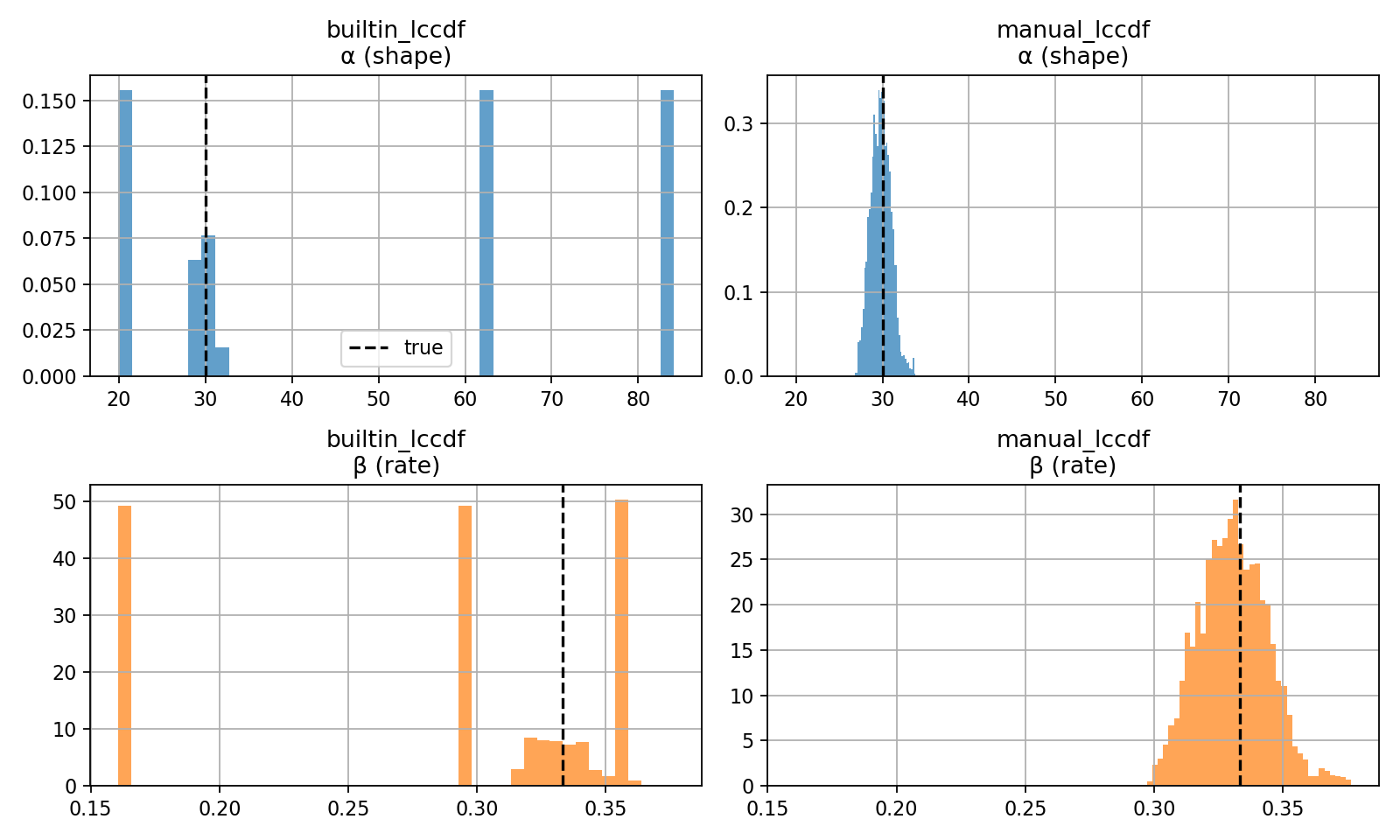
I then sample from each model using the default NUTS hyperparameters and the same initial seed. As you can see below, only censored_manual_lccdf.stan generates samples close to the true values of alpha and beta. The model that uses gamma_lccdf from Stan reaches max tree depth 90% of the time.
I have run this over multiple seeds (for Stan and data generation) and repeatedly see the same behaviour. Implementing a basic MH sampler in Python and using BridgeStan to call log_probyields decent results for both models.
To try and isolate the issue, I created two separate models that are parameterised as:
data {
real<lower=0> alpha;
real<lower=0> beta;
}
parameters {
real<lower=0> y;
}
model {
...
}
And use BridgeStan to evaluate log_prob and log_prob_grad for each model across y=0 to y=200, but the values agree with one another, so I’m a bit stumped where the discrepancy is coming from. Any suggestions on how to isolate this?