New question from a newbie who tries to wrangle my brain around cumulative probit models (ordinal responses, in this case a 7-item Likert, coded as 1-7)
I have skewed data (currently 7 respondents, each replying to 6 questions) as per the below:
# each respondent answers 6 questions on a 7-point Likert (coded as 1-7)
data <- data.frame(
id=rep(c("A", "B", "C", "D", "E", "F", "G"), each=6),
gender=c(rep("male", 6*4), rep("female", 6*3)),
name=rep(c("Q1", "Q2", "Q3", "Q4", "Q5", "Q6"), times=7),
response=c(rep(6,6), # resp.1, male
c(rep(7,4), rep(6,2)), # resp.2, male
rep(7,6), # resp.3, male
c(7, rep(6,4), 5), # resp.4, male
rep(7, 6), #resp.5, female
rep(6, 6), #resp.6, female
c(7, 6, 6, rep(5,3)) # resp.7, female
))
data |> group_by(id, gender, response) |> tally()
When I fit a regular, non-pooled model, things line up to the data quite nicely:
d <- data |> select(response, gender)
formula <- response | thres(6) ~ 1 + gender
priors <- c(prior(normal(-1.068, 1), class = Intercept, coef = 1),
prior(normal(-0.566, 1), class = Intercept, coef = 2),
prior(normal(-0.180, 1), class = Intercept, coef = 3),
prior(normal( 0.180, 1), class = Intercept, coef = 4),
prior(normal( 0.566, 1), class = Intercept, coef = 5),
prior(normal( 1.068, 1), class = Intercept, coef = 6),
prior(normal(0, 1), class = b))
M2 <- brm(
data = d,
family = cumulative(probit),
formula=formula,
prior = priors,
backend="cmdstanr",
cores = 4,
seed = 1
)
m <- M2
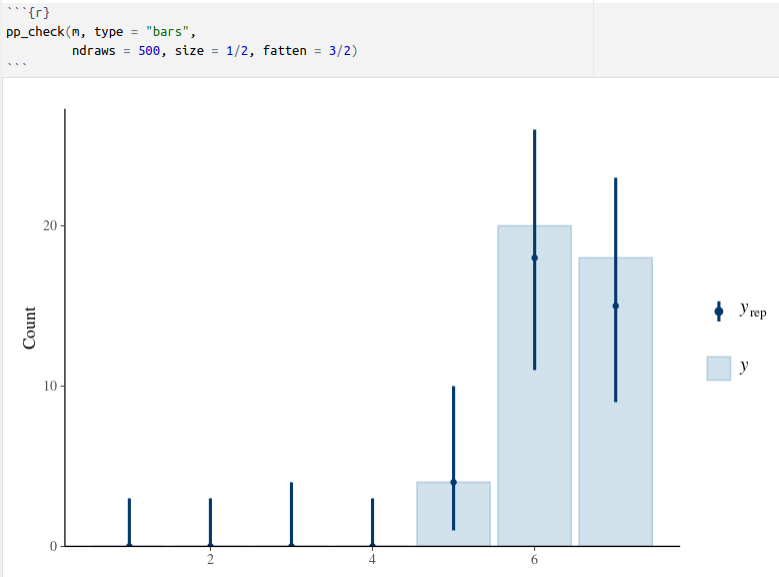
Diagnostics look OK (around 40ish divergent transitions, but the caterpillar plots look OK, etc)
Posterior predictive plots line up to the data:
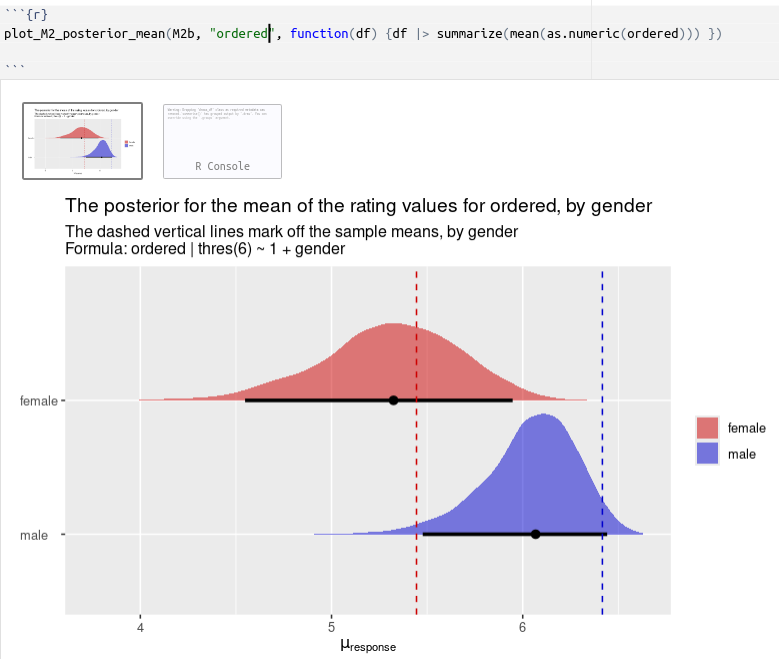
I modified the plot function from the blog that @Solomon provides here Notes on the Bayesian cumulative probit | A. Solomon Kurz (it has helped me a lot) to fit my data (e.g. I use 7-item Likert):
plot_M2_posterior_mean <- function(m, title) {
m_male <- m$data |> filter(gender == 'male') |> summarize(m=mean(response)) |> pull()
m_female <- m$data |> filter(gender == 'female') |> summarize(m=mean(response)) |> pull()
# note, the magrittr pipe %>% is needed, because native |> pipe does not handle dot
as_draws_df(m) %>%
select(.draw, starts_with("b_")) %>%
set_names(".draw", str_c("tau[", 1:6, "]"), "beta[1]") %>%
# insert another copy of the data below
bind_rows(., .) %>%
# add the two values for the dummy variable gendermale
mutate(gendermale = rep(0:1, each = n() / 2)) %>%
# compute the p_k values conditional on the gender dummy
mutate(p1 = pnorm(`tau[1]`, mean = 0 + gendermale * `beta[1]`),
p2 = pnorm(`tau[2]`, mean = 0 + gendermale * `beta[1]`) - pnorm(`tau[1]`, mean = 0 + gendermale * `beta[1]`),
p3 = pnorm(`tau[3]`, mean = 0 + gendermale * `beta[1]`) - pnorm(`tau[2]`, mean = 0 + gendermale * `beta[1]`),
p4 = pnorm(`tau[4]`, mean = 0 + gendermale * `beta[1]`) - pnorm(`tau[3]`, mean = 0 + gendermale * `beta[1]`),
p5 = pnorm(`tau[5]`, mean = 0 + gendermale * `beta[1]`) - pnorm(`tau[4]`, mean = 0 + gendermale * `beta[1]`),
p6 = pnorm(`tau[6]`, mean = 0 + gendermale * `beta[1]`) - pnorm(`tau[5]`, mean = 0 + gendermale * `beta[1]`),
p7 = 1 - pnorm(`tau[6]`, mean = 0 + gendermale * `beta[1]`)) %>%
# wrangle
pivot_longer(starts_with("p"), values_to = "p") %>%
mutate(response = str_extract(name, "\\d") %>% as.double()) %>%
# compute p_k * k
mutate(`p * response` = p * response) %>%
# sum those values within each posterior draw, by the gendermale dummy
group_by(.draw, gendermale) %>%
summarise(mean_response = sum(`p * response`)) %>%
mutate(gender = ifelse(gendermale == 0, "female", "male")) %>%
# the trick with and without fct_rev() helps order the axes, colors, and legend labels
ggplot(aes(x = mean_response, y = fct_rev(gender), fill = gender)) +
stat_halfeye(.width = .95) +
geom_vline(xintercept = m_male, linetype = 2, color = "blue3") +
geom_vline(xintercept = m_female, linetype = 2, color = "red3") +
scale_fill_manual(NULL, values = c(alpha("red3", 0.5), alpha("blue3", 0.5))) +
labs(title = paste0("The posterior for the mean of the rating values for ", title, ", by gender"),
subtitle = paste("The dashed vertical lines mark off the sample means, by gender\nFormula:", m$formula),
x = expression(mu[response]),
y = NULL) +
theme(axis.text.y = element_text(hjust = 0))
}
Using this function seems to show reasonable alignment with the sample mean:

However, I have learned that in order to avoid overfitting, and make the model more generalizable, I should use partial pooling, and in my case I thought that using pooling on respondents as well as on questions might make scientific sense.
Some respondents might have a bad day, or some questions might be vaguely formulated, so it makes sense to pool that information into the overall model.
I am not overly interested in the actual responses for specific respondents, or specific questions, so when I make predictions, I still intended to only use gender as a predictor (plus the intercept of course).
I figured that I could reuse the function above to plot data from the pooled model as well.
From what I understand, the group-level effects (only affecting intercepts, in my case) work like “offsets from the population parameter”, so if I omit them from the calculation, I would get the behaviour of “the average respondent, responding to the average question” (average in the model-sense, not necessarily arithmetic average).
So, also based on Solomons writings, I defined the following model:
d <- data |> select(response, gender, id, name)
formula <- response | thres(6) ~ 1 + gender + (1 | id) + (1 | name)
priors <- c(prior(normal(-1.068, 1), class = Intercept, coef = 1),
prior(normal(-0.566, 1), class = Intercept, coef = 2),
prior(normal(-0.180, 1), class = Intercept, coef = 3),
prior(normal( 0.180, 1), class = Intercept, coef = 4),
prior(normal( 0.566, 1), class = Intercept, coef = 5),
prior(normal( 1.068, 1), class = Intercept, coef = 6),
prior(normal(0, 1), class = b),
prior(exponential(1), class = sd))
M3 <- brm(
data = d,
family = cumulative(probit),
formula=formula,
prior = priors,
backend="cmdstanr",
cores = 4,
seed = 1
)
m <- M3
Posterior checks look good, both on population level and grouped by id or name.
When I use the same function as above to plot the mean of the response, I get considerable drift towards the middle of the range:
plot_M2_posterior_mean(m, "response")

At first, I figured that this makes sense. I now use partial pooling, making the mean drift towards the population mean, and individual respondents are less influential.
However, I tested by simulating that I got 40 new rave reviews (all 7, the max response)
This turns the model even more towards the center of the scale, which I find counter-intuitive:
d <- rbind(data |> select(response, gender, id, name),
data.frame(response=7, # rave reviews
gender=rep(c("female", "male"), each=120),
id=rep(c("100", "101", "102", "103", "104", "105", "106", "107", "108", "109",
"1100", "1101", "1102", "1103", "1104", "1105", "1106", "1107", "1108", "1109",
"200", "201", "202", "203", "204", "205", "206", "207", "208", "209",
"2100", "2101", "2102", "2103", "2104", "2105", "2106", "2107", "2108", "2109"), each=6), # 40 new respondents
name=rep(c("Q1", "Q2", "Q3", "Q4", "Q5", "Q6"), times=40)))
plot_M2_posterior_mean(
brm(
data = d,
family = cumulative(probit),
formula=formula,
prior = priors,
backend="cmdstanr",
cores = 4,
seed = 1),
"faked response")
Gives the plot:

Before adding the fake reviews, the pooled model had means close to 5 (whereas the non-pooled model was more optimistic, around 6). After adding 40 new respondents, each replying 7 to every question, the expected mean response decreases to around 4.5
What am I misunderstanding? Or mis-coding?
After all, I adapted the code from the blog of @Solomon as above, and I am quite new to ordinal modeling (as stated before here). Thanks in advance!
- Operating System: Ubuntu 22.04
- brms Version: 2.22.0