This is joint work with @shoshievass and follows an earlier discussion: Quadratic optimizier. We’re a little stuck and there are a few open questions. We’ll keep thinking about the issues at hand, but anyone’s welcome to chime in.
As a recap, we want to model optimal bids for an auction. Shosh can fill in the details of the problem or point readers to a reference. As previously discussed, we wrote a quadratic optimizer, which verifies KKT conditions, and exposed it to Stan on a dev branch. See issues 888 on math and 2522 on stan GitHub repos. Using this branch, one can run the quadratic optimizer from cmdStan.
In one of our tests, part of the data generating process involves computing x_p, the solution to a KKT problem. The parameter \gamma controls how many elements of x_p are 0, i.e. at the boundary. In the case where \gamma > 0.5, none of the x_p's are 0, and the unconstrained optimum satisfy the equality and inequality constraints. We simulate data with varying values of \gamma, and fit the same model to the simulated data.
The model fits easily, even as we get (arbitrarily) close to the boundary case, for example when we simulate data with \gamma = 0.6. But, as was suspected notably by @betanalpha, things go south when we hit the boundary, i.e. when we simulate data with \gamma \le 0.5. To be more specific, at \gamma = 0.5:
- the one x_p that is 0 is correctly estimated as such.
- the chain does not mix: very little movement in the parameter space, and a high autocorrelation. Increasing the number of sampling iterations from 1000 to 5000 does not help.
- HMC hits the maximum tree-depth a lot.
- The chain is slow.
- There are no divergent transitions.
- There are no Metropolis proposal rejections.
When \gamma < 0.5 and more than one value of x_p is 0, the sampler only finds one of the inactive values. This suggests the Markov chain gets stuck in a neighborhood of the parameter space.
The above symptoms are all visible in the diagnostic plots, which are attached:
MCMCplot_gamma_06.pdf (26.9 KB)
MCMCplot_gamma_05_1.pdf (21.8 KB)
MCMCplot_gamma_05_2.pdf (21.8 KB)
quadprog_test_5dim.stan (2.8 KB)
And the pairs plot for \gamma = 0.6:

and \gamma = 0.5:
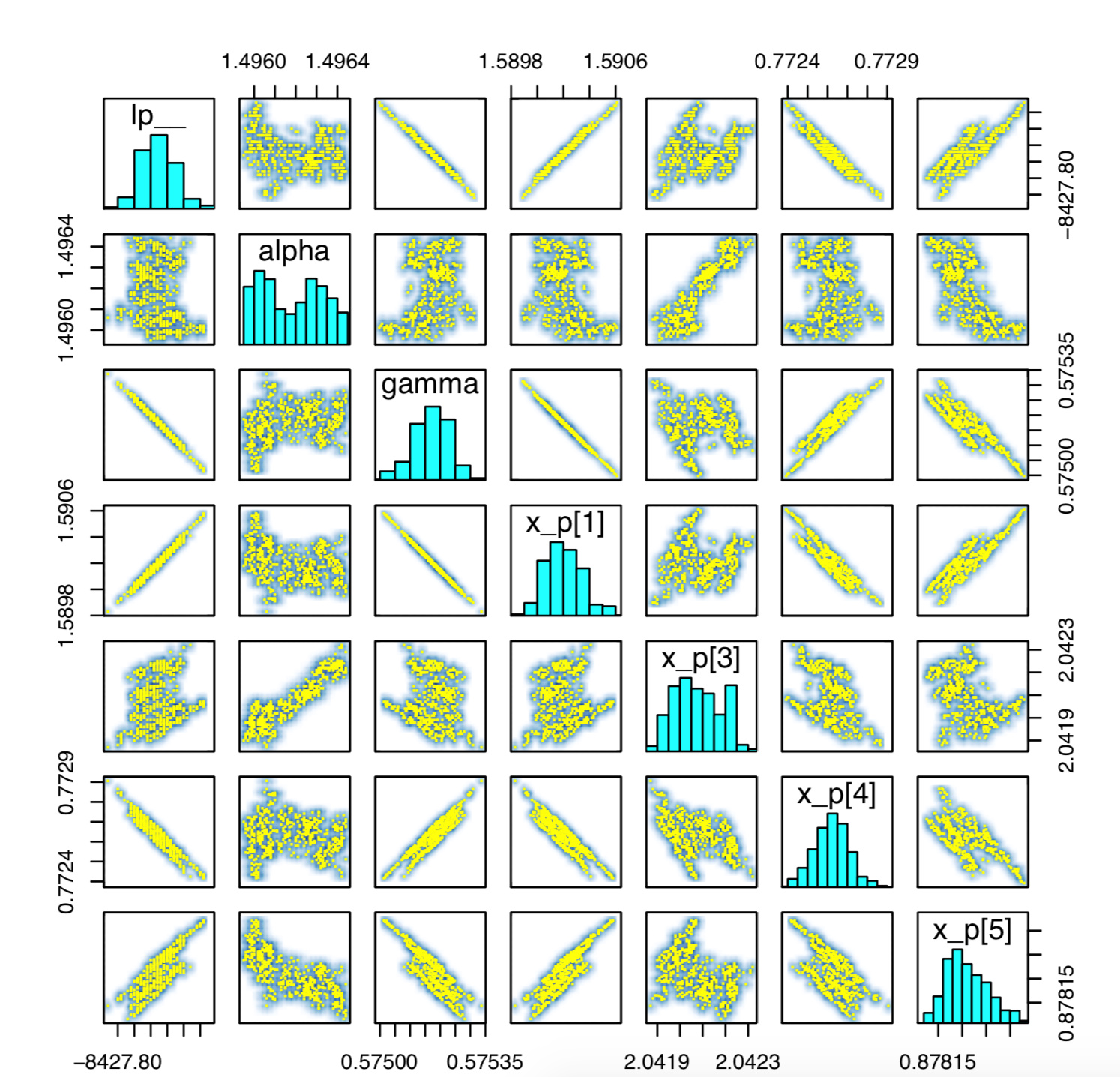
So clearly, the non-smoothness of the joint distribution is hurting us. It is not clear to me exactly why we observe these particular symptoms. I expected the joint to either be roughly smooth, in which case HMC could jump across this boundary; or HMC to spit out divergent transitions, or reject Metropolis proposals because we violate energy conservation when simulating Hamiltonian trajectories.
The next thing I hope to do is work out what the correct posterior would look like. And eventually, think about ways to fit (or approximate) models with this kind of non-smooth structure.