I know the idea of a webstan/cloudstan has been brewing around here for quite some time. I was running some performance tests and decided to experiment with cloudstan a bit. I made a live demo that runs on a free AWS instance so its understandably slow.
Underneath it uses httpstan (thanks @ariddell and everyone else working on that, it was a breeze to make a new interface work).
You can check it out here: https://cloudstan-experiment.herokuapp.com/
Logging in is mandatory in order to create and run a model. If you dont want to register, you can use dummy data (the email has to be in valid form, test@test.com is fine, no emails will be sent). Once you login you can create a new model, compile it, supply the data and get the results in table and chart form (some basic charts).
The editor has syntax highlighting, but I havent yet added all the keywords, just some quick ones. The fit summary doesnt include n_eff, Rhat and se_mean as those require a bit more calculation and httpstan doesnt calculate them.
If for some reason the AWS instance would terminate, here are some images of how it looks like.
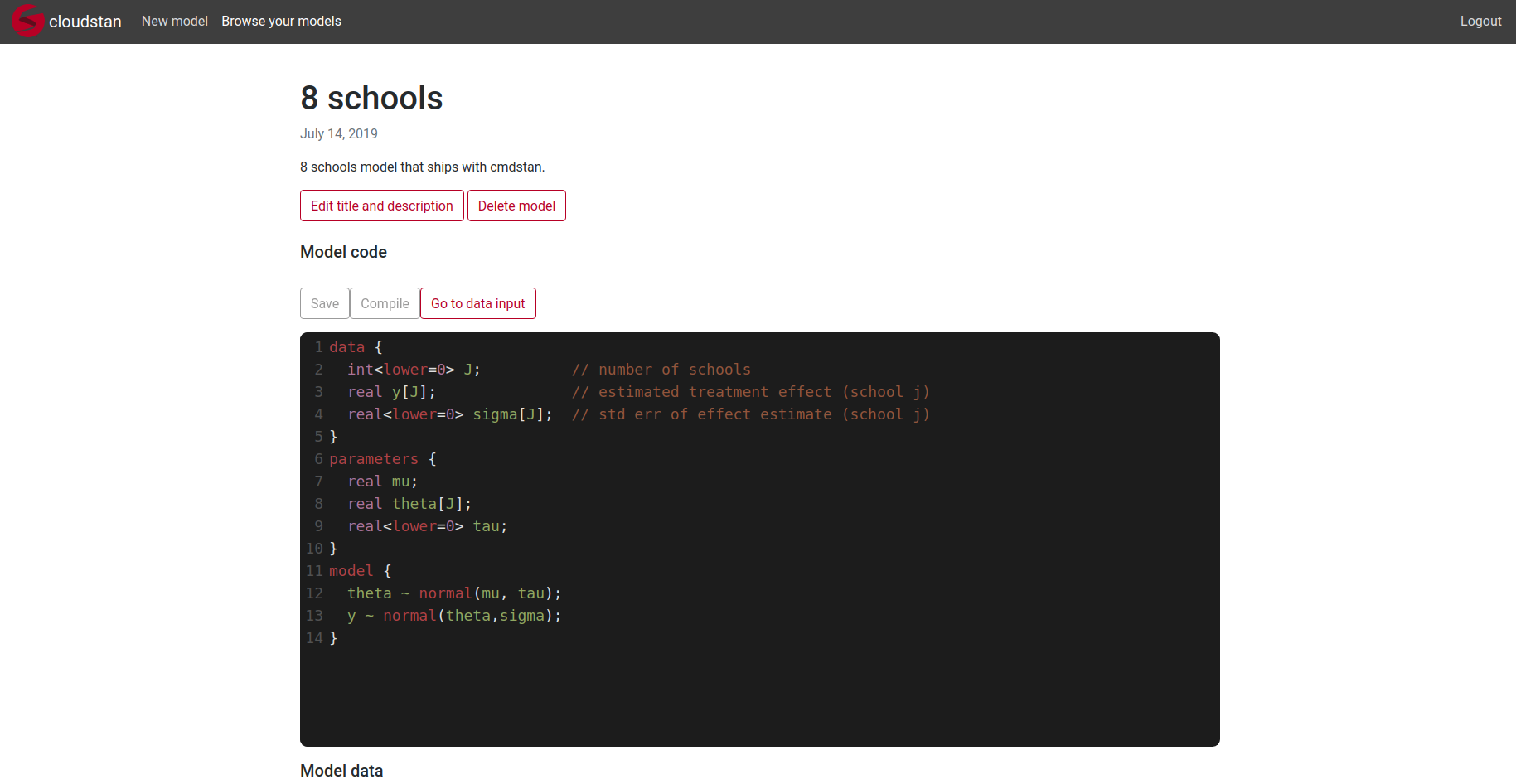
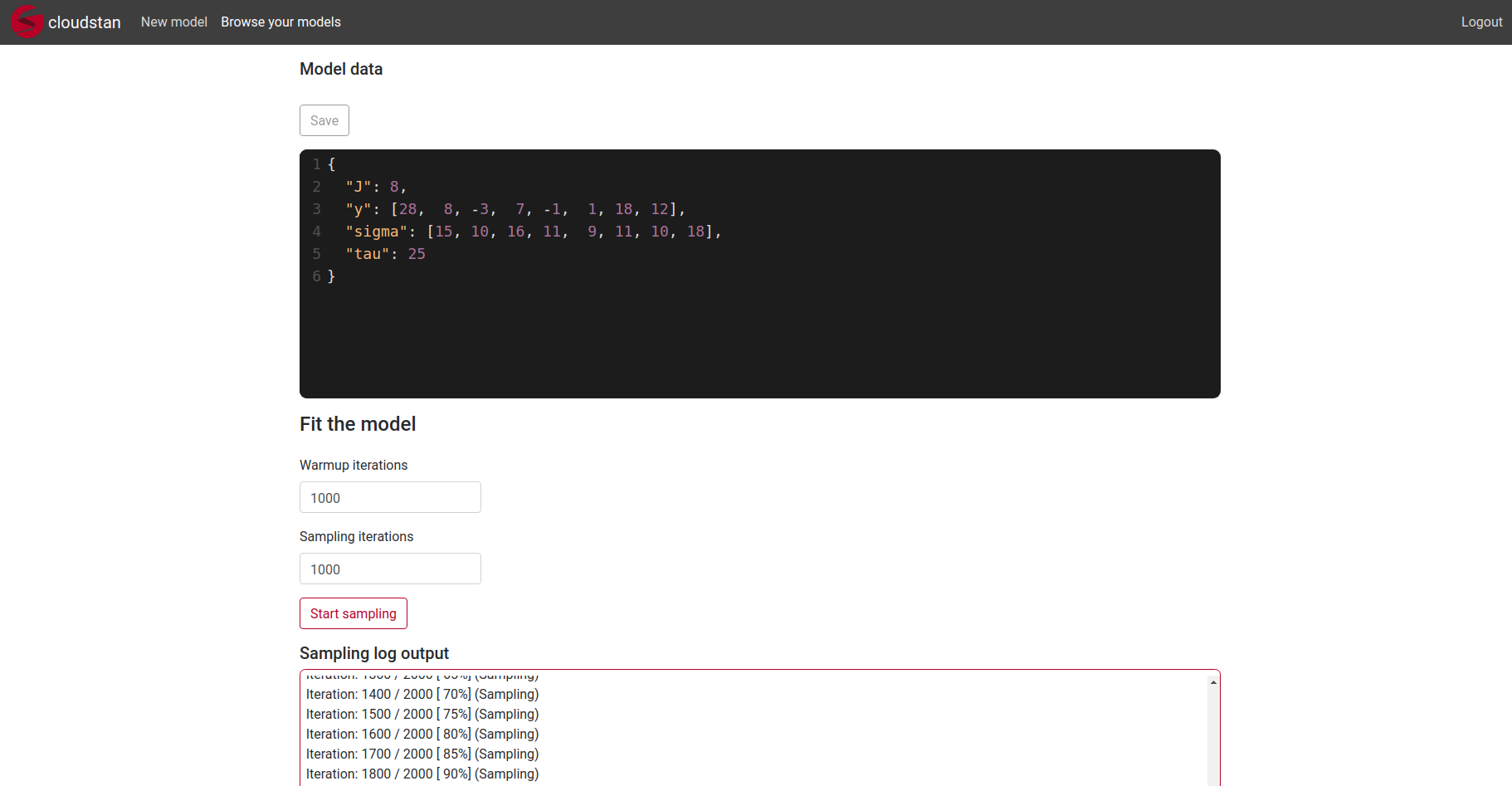
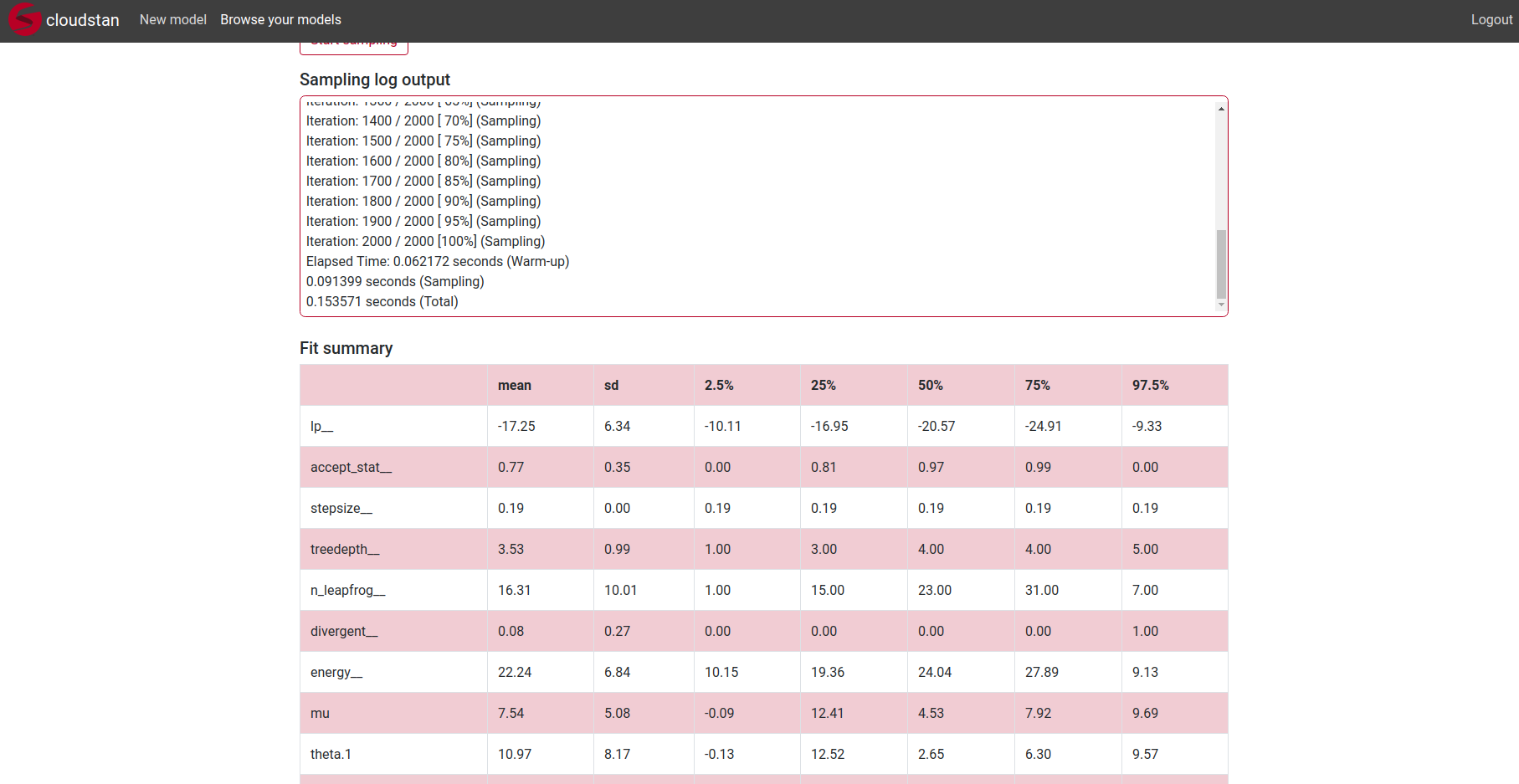
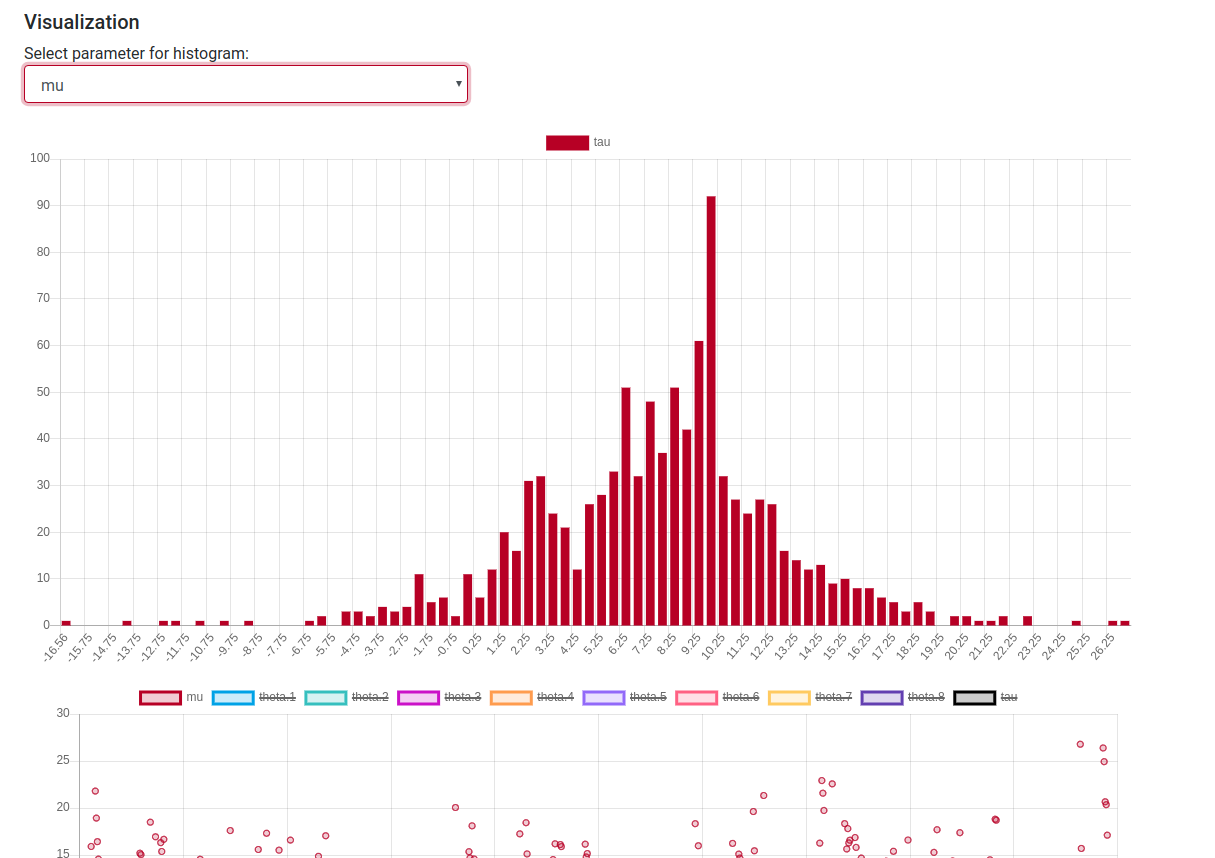
The charts display 1 parameter by default, other can be added by clicking their name in the charts. For the histogram you can select the parameter from the dropdown.
Would something like this be of any use to anyone? I imagine it could be useful for beginners. Any comments or discussion is welcome.
The main issue is of course the computing resources, as the free instance will probably be limiting.
EDIT: I havent tested it on mobile, not sure it works there.