I’m modeling some data thanks to a joint model between survival and longitudinal data. Those longitudinal data have a hierarchical structure, with two random effects levels : each patients have a least one metastasis that is at least observed once.
I have several model that I would like to compare.
I’ve used the loo package with a leave-one-patient-out or leave-one-measurement out, but it leads in both scenario to high pareto’s k.
Of my understanding, this doesn’t not necessarly means that the model is wrong, but that the importance sampling part can’t be trust.
The WAIC is also failing.
So I wanted to use the kfold function, but I feel like we can only use this fonction with rstanarm model and not with rstan model. Am I wrong ? Or could we use the kfold function with rstan (is there a work around) ?
Otherwise, is there another way to compare model, please ?
Based on this, it is likely that your model is flexible and the posterior is changing a lot when removing one observation or patient, which can explain high Pareto-k’s. If you tell more about your model and post the model code and the loo output, I may comment more.
I’ve seen in the paper: “Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC” s11222-016-9696-4.pdf (1.4 MB) that it’s recommended to performed cross-validation with 10 fold.
However, my model are quite computationnaly expansive on their own (up to 2 days using the within-chain parallelization), I was considering performing a 5 fold cross validation.
Do you think that it’s still good enough? Or you think that I should stick with 10 fold even if it’s a heavy methodology ?
5-fold is better than not doing it all. It depends on the data and model, how much difference there is between 5-fold and 10-fold. If there is a lot of data compared to the number of parameters, then the results are less sensitive to the number of folds. You can also get some speedup by initializing the cross-validation fits with the full data posterior draws and use shorter warmup. It is also possible that you don’t need as many iterations for getting a good estimate of cross-validation elpd as you need for posterior inference otherwise. In our paper Bayesian cross-validation by parallel Markov chain Monte Carlo | Statistics and Computing, we demonstrate the warmup and fewer iterations in case of GPU parallel computation, but the same idea can be used even without GPUs. This way you might be able to at least halve the computation time for each fold.
Hi
Thank you for the feedback!
For my richest dataset I have access to 608 survival data associated to 6919 observations that are nested in 1401 lesions that are nested in 1026 organs that are themselves nested in 608 patients.
And the model has 40 parameters if I’m only accounting for the population parameters. If I count each individual and lesion random effects, then I have 6065 parameters.
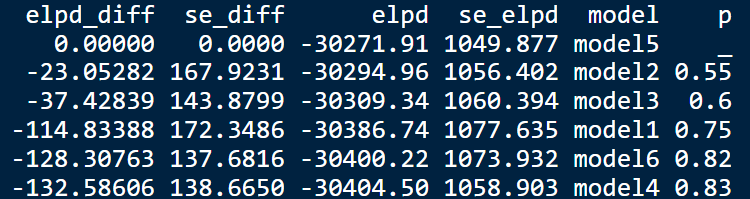
Am I right? Is there something else that I could tried to see which model I should choose? I feel like the se_elpd are quite high? But I’m not sure if I can do something about it?
(I’ve tried using PSIS-LOO as leave-one-patient out and leave-one-measurement out, but my pareto k are too high (about 40% and 20% respectively), and using matching did not resolve the issue)
Hi, I’ve been on vacation and now going through the messages
Your model is flexible, and it is likely you will get high Pareto-k’s even if the model would be good.
I agree. Sometimes the differencve in predictive performance can be small even if the data have enough information to inform the posterior. See, e.g., Section 13 and 15 in Nabiximols treatment efficiency case study.