I’m trying to refine a distributional model using a Student distribution for the outcome, but am seeing highly variable prior predictive checks. I have defined y from the data, but even the plot of y is moving all over the place.
Just wondering what I might be doing wrong with my specification.
fmla <- bf(y ~ 0 + Intercept +
Pred1.c +
Pred2.c +
Pred3.c +
Pred4.c +
Pred5.c +
(1|Grp1) +
(1|Grp2) +
(1|Grp3) +
(1|Grp4/Grp5),
center = TRUE,
sigma ~ 0 + (1|Grp2) + (1|Grp1),
nu ~ 0 + (1|Grp2) + (1|Grp1))
## Set priors
priors <- c(
set_prior("normal(10,5)",
class = "b",
coef = "Intercept" ),
set_prior("normal(0,1)",
class = "b"),
set_prior("normal(0,1)",
class = "sd",
coef = "Intercept",
group = "Grp3"),
set_prior("normal(1,1)",
class = "sd",
coef = "Intercept",
group = "Grp4"),
set_prior("normal(0,1)",
class = "sd",
coef = "Intercept",
group = "Grp5:Grp5"),
set_prior("normal(0,3)",
class = "sd",
coef = "Intercept",
group = Grp1"),
set_prior("normal(0,0.5)",
class = "sd",
coef = "Intercept",
group = "Grp1",
dpar = "sigma"),
set_prior("normal(0,0.5)",
class = "sd",
coef = "Intercept",
group = "Grp2",
dpar = "sigma"),
set_prior("normal(0,1/sqrt(4))",
class = "sd",
coef = "Intercept",
group = "Grp1",
dpar = "nu"),
set_prior("normal(0,1/sqrt(4))",
class = "sd",
coef = "Intercept",
group = "Grp2",
dpar = "nu")
)
Mod <- brm(
fmla,
Data,
family = student(link_nu = "logm1"),
prior = priors,
inits = 0,
iter = 5000,
warmup = 2500,
chains = 4,
cores = ncores,
sample_prior = "only",
save_pars = save_pars(all = TRUE),
control = list(max_treedepth = 14,
adapt_delta = 0.999)
)
With separate runs of yrep, the plot of y also changes a lot.
y <- Data$y
yrep <- posterior_predict(Mod ,nsamples = 100)
ppc_dens_overlay(y,
yrep) +
coord_cartesian(xlim = c(-50, 50))
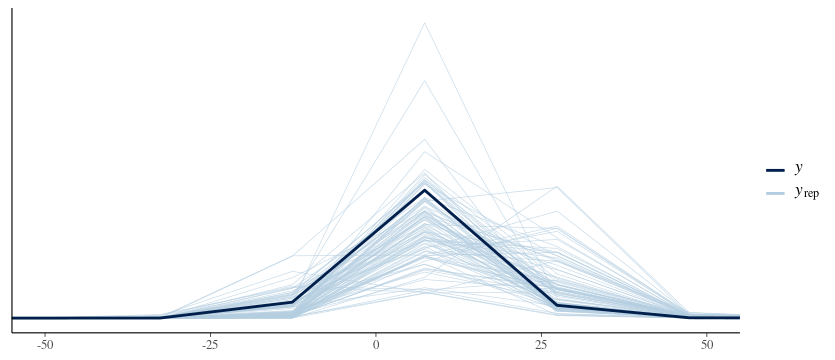


Am I calling something incorrectly?


