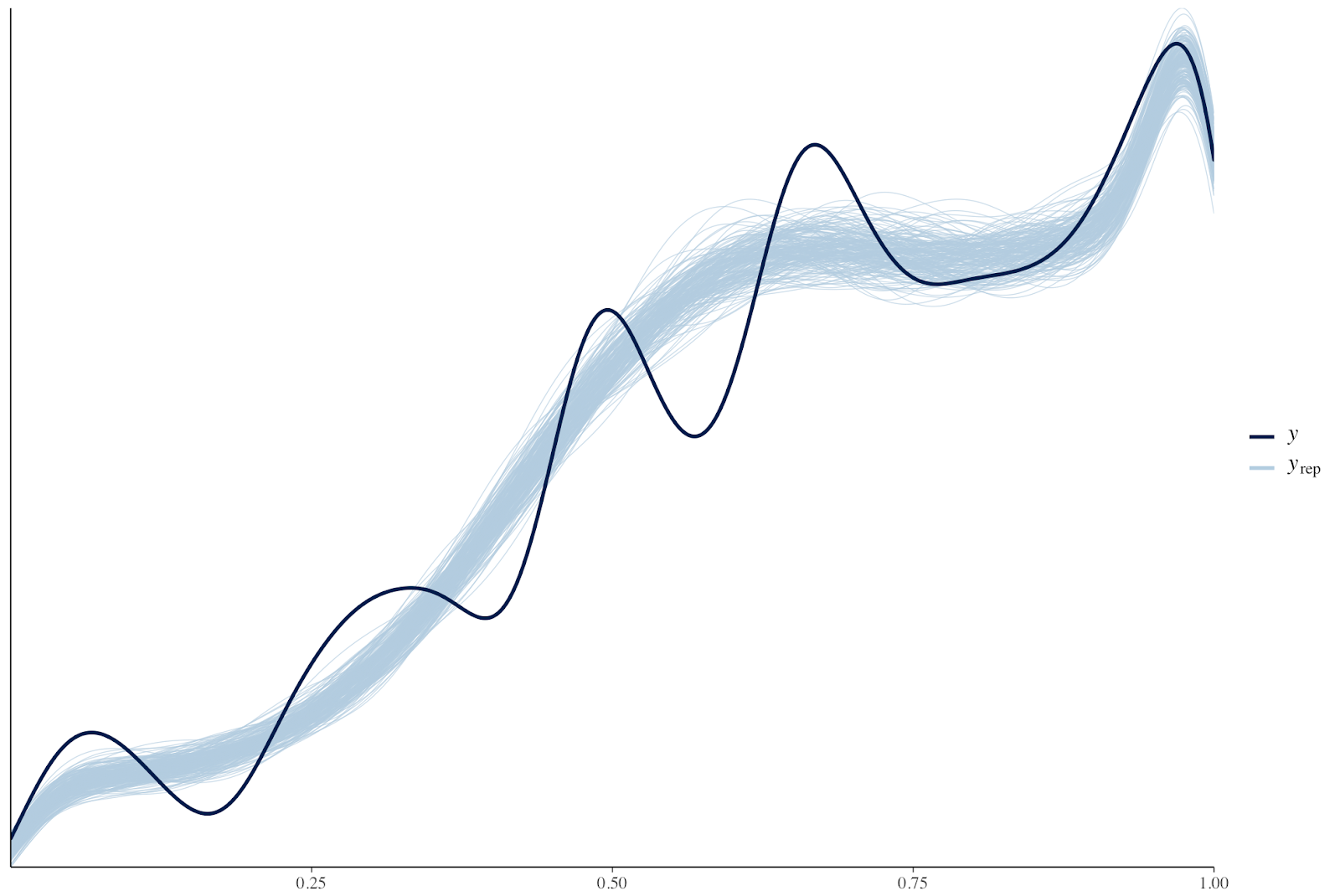
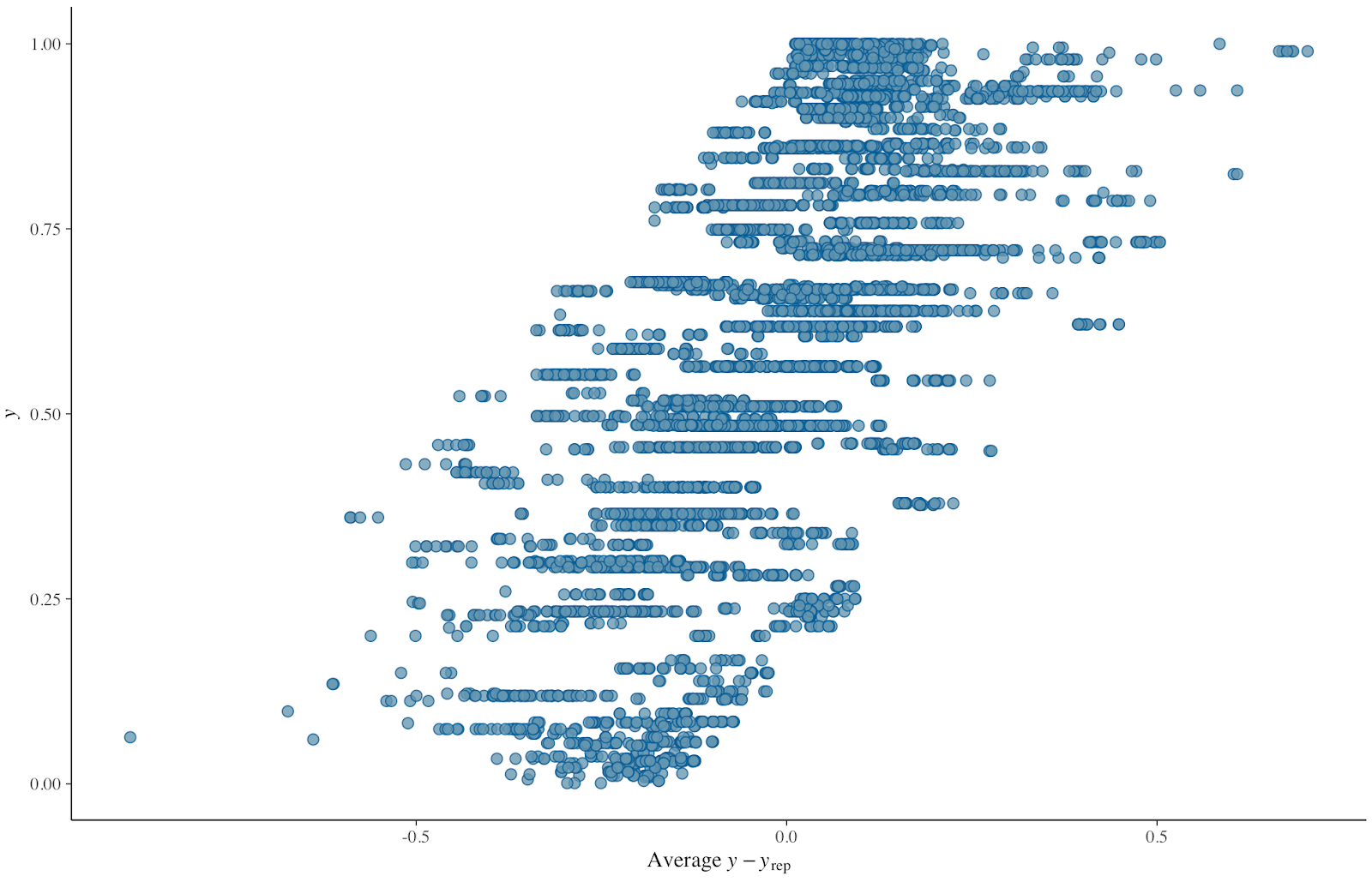
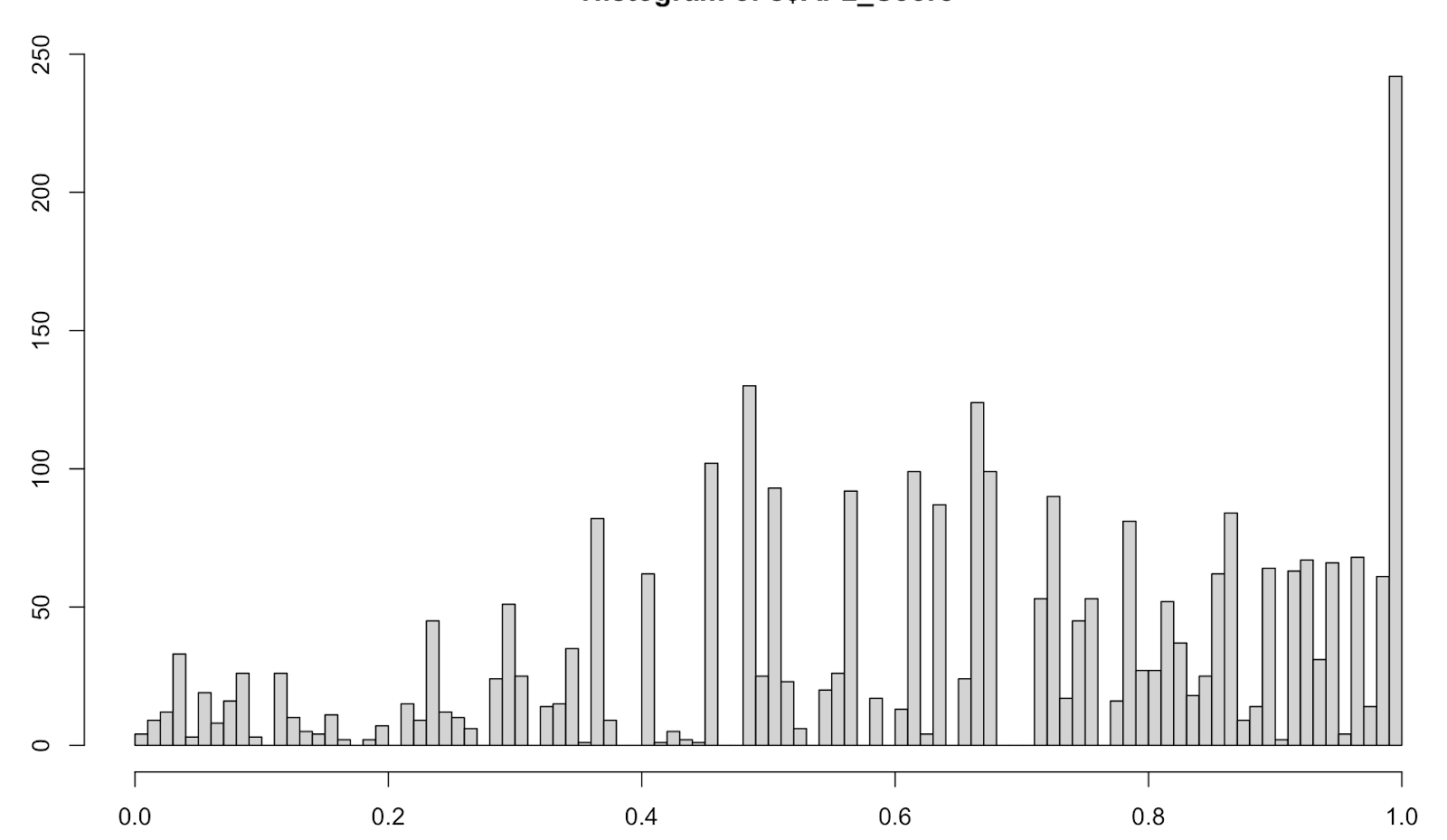
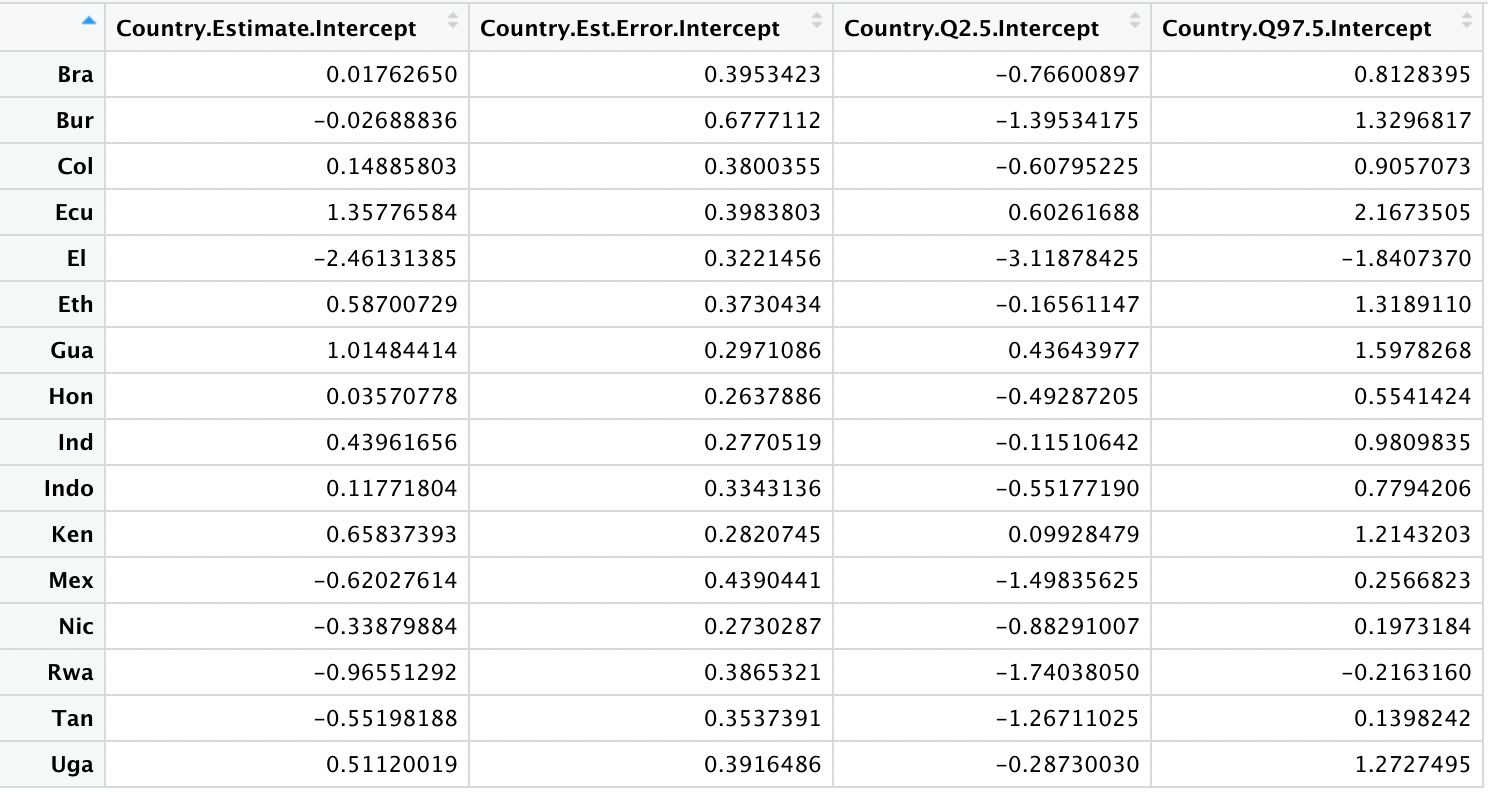
Hi, I have a question related to setting a brms hierarchical model. We had built a model in Stan, but we want to know if there is a way of implementing it in brms. In particular, we are not sure how to add group level predictors in brms… We want to do this, because we think it will be easier to maintain (not everyone knows Stan where we work!) and to use some of the nice built-in functions brms has (like pp_check, sampling from the priors, and automatically standardizing the data).
Data description:
I work for an NGO called Enveritas. We survey coffee farmers around the world and we have a set of survey questions that give us the probability of a farmer being under the poverty line. For operational reasons, we split each country in regions and randomize at that level.
So our data frame would look like this:

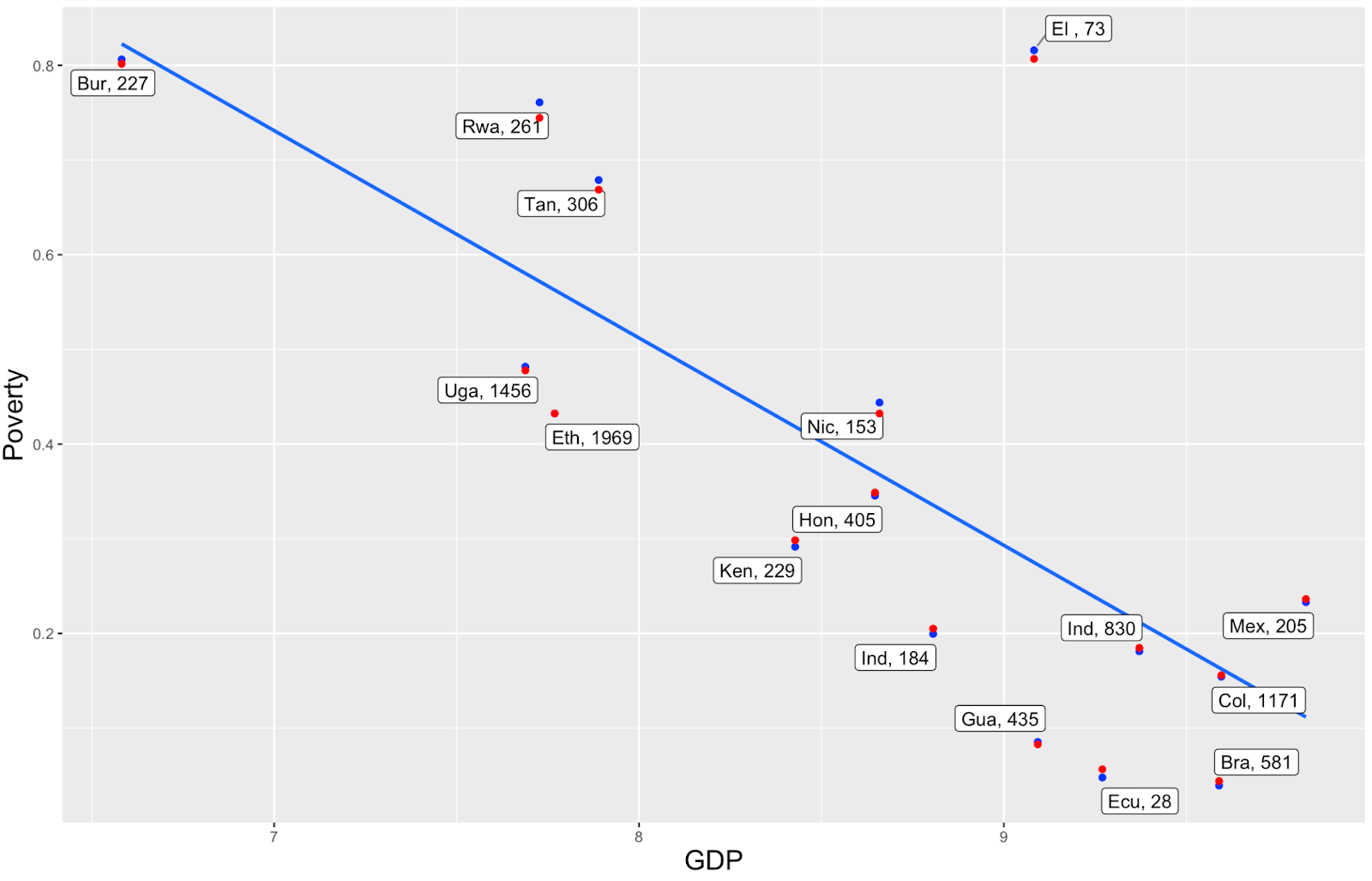
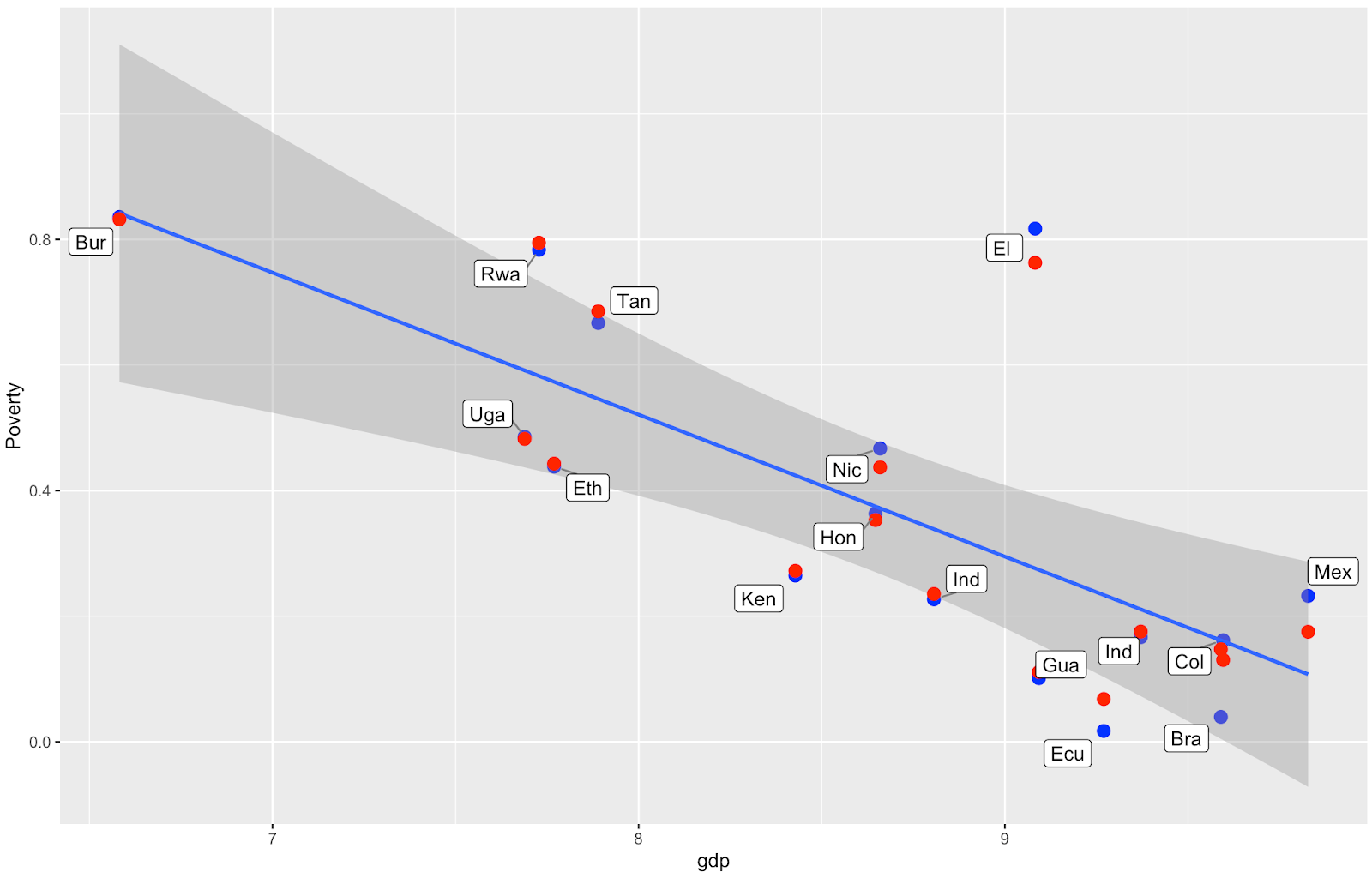
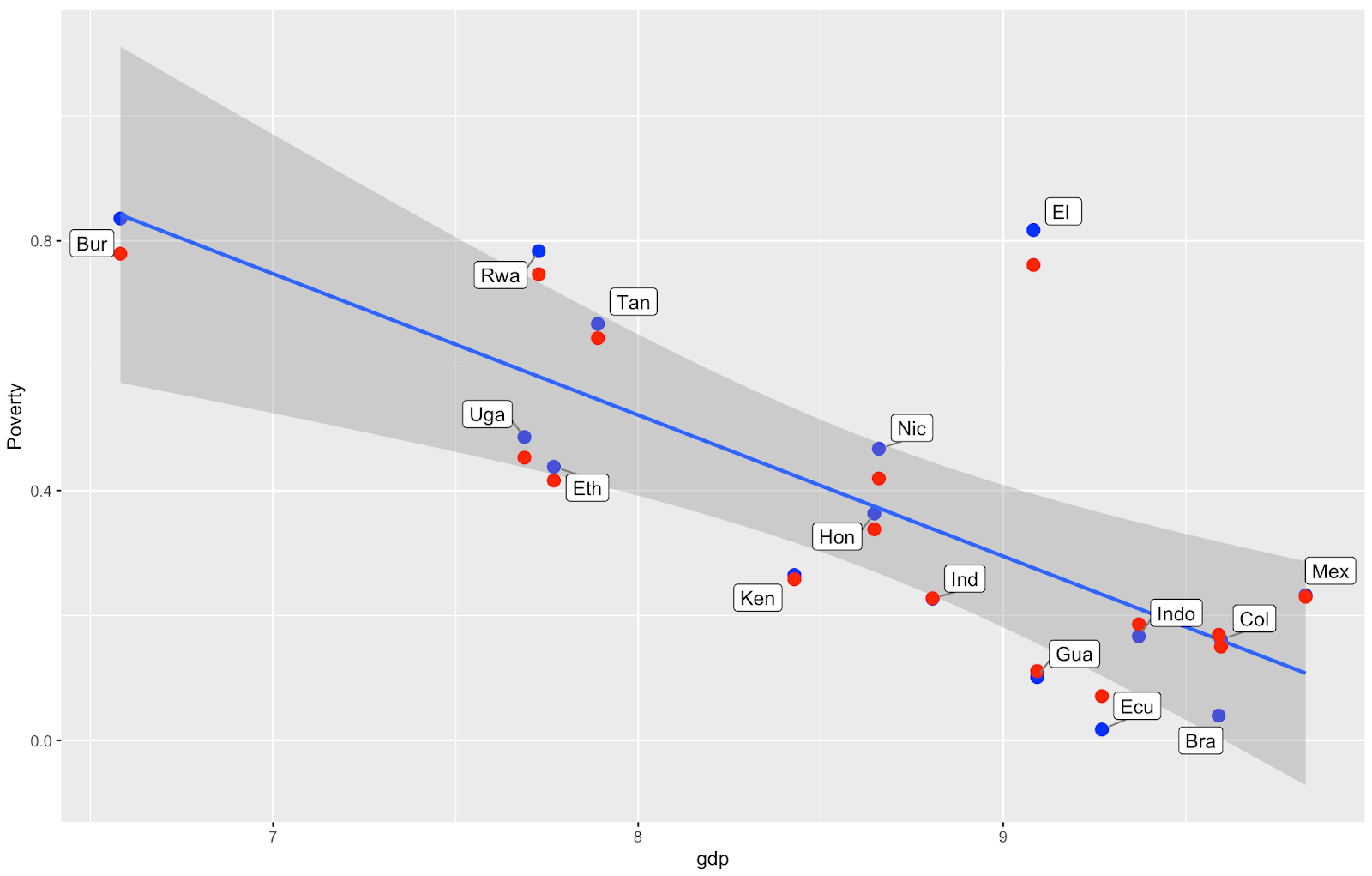
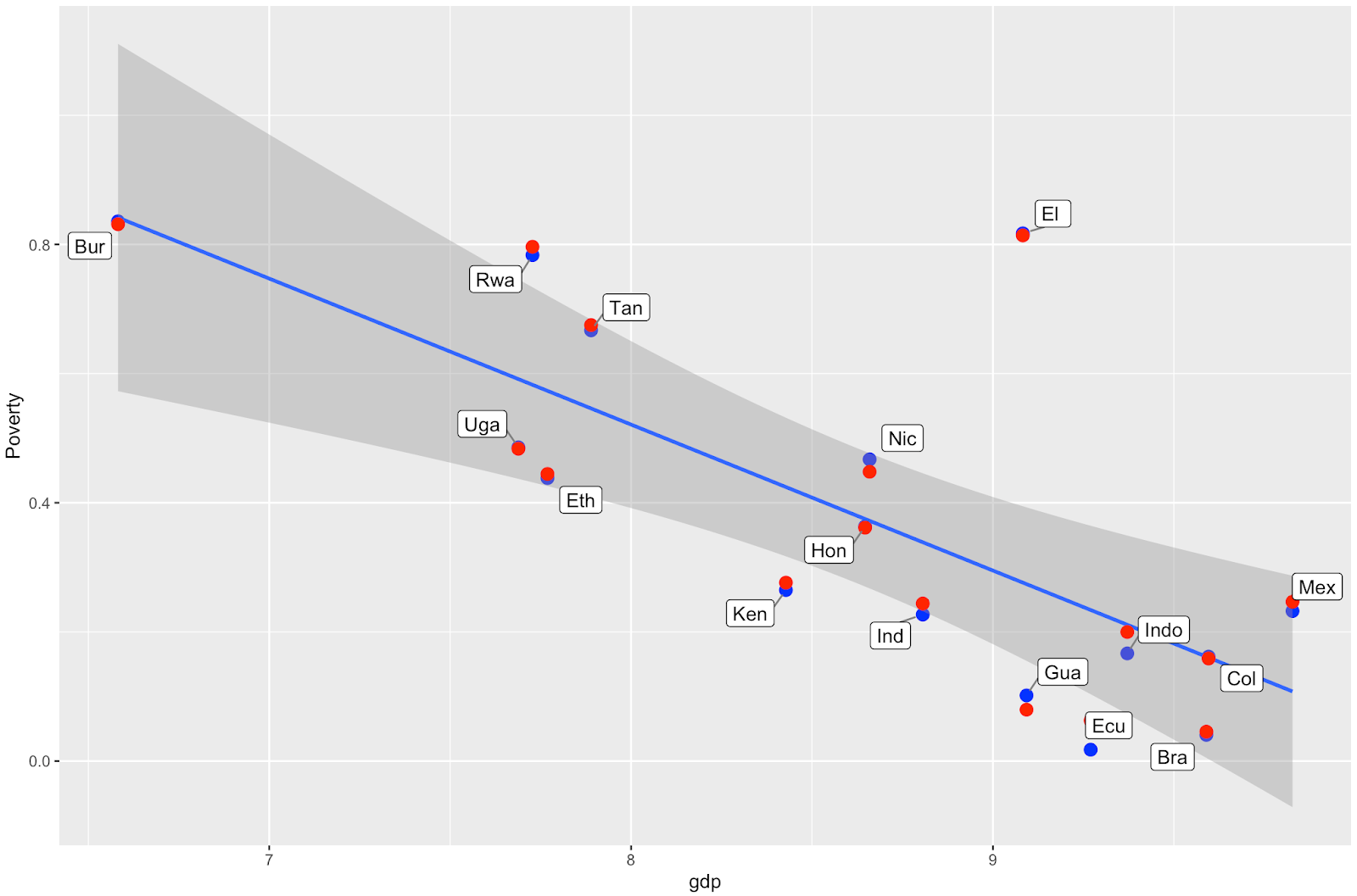
We know that Gross Domestic Product (GDP) of a country correlates closely with the country’s poverty (see graph) - so it would be great to add that information (and other country-level covariates) to the model. Also, our end goal is to estimate the world’s coffee farmer poverty rate, and for that we will need to predict the poverty of countries we haven’t visited yet.

So the data here would be like that:

We were using a stan model to model this relationship, where we say the probabilities of the farmers comen from a hierarchical model country-region-farmer. And the likelihood is a Beta(a[region], b[region]).
Current stan code:
data {
int<lower=0> C; // Number of countries
int<lower=0> R; // Number of regions
int<lower=0> N; // Number of observations (farmers)
int<lower=0> K; // Number of country predictors
matrix[C, K] X; // Country predictor matrix
vector<lower=0,upper=1>[N] pov_prob; // Observed probabilities
int<lower=1> region_n_obs[R]; // Number of observations in each region
int<lower=1, upper=C> region_country_id[R]; // region country indicators
}
parameters {
real alpha_a; // Country-level regression intercept
real alpha_b; // Country-level regression intercept
vector[K] beta_a; // Regression Coefficients
vector[K] beta_b; // Regression Coefficients
real<lower=0> sigma_a; // Error scale
real<lower=0> sigma_b; // Error scale
vector<lower=0>[R] a;
vector<lower=0>[R] b;
}
transformed parameters{
vector[C] mu_a;
vector[C] mu_b;
vector[C] country_pov;
// We need both mu_a and mu_b to estimate
// the parameters from a Beta distribution
// X are you country covariates.
mu_a = alpha_a + X*beta_a;
mu_b = alpha_b + X*beta_b;
// Country mean -- which is modeled as the mean of the region population
country_pov = mu_a ./ (mu_a+mu_b);
}
model {
int pos = 1;
// We use truncated normal as prior for our parameters
alpha_a ~ normal(0, 100);
alpha_b ~ normal(0, 100);
beta_a ~ normal(0, 100);
beta_b ~ normal(0, 100);
sigma_a ~ normal(0, 100);
sigma_b ~ normal(0, 100);
// Each region get a country-level prior
for(r in 1:R){
int country = region_country_id[r];
a[r] ~ normal(mu_a[country], sigma_a);
b[r] ~ normal(mu_b[country], sigma_b);
}
// We observed probabilities of being poor at the region-level
// We model it with a beta distribution. We use segment for vectorization due
// to the unequal size of observation in each region.
for(r in 1:R){
segment(pov_prob, pos, region_n_obs[r]) ~ beta(a[r], b[r]);
pos = pos + region_n_obs[r];
}
}
So there are three questions I have are:
- Is it possible to set a model like that using brms? I was looking at the bf() syntax, but wasn’t sure if it was appropriate to use in my case.
- If I am able to build the brms models, is there a way to predict the coffee poverty number from the countries we haven’t visited yet?
Thanks!