Hey there!
I’m trying to model preferred prices and have quickly set up a simple linear model. The Gaussian model makes worse predictions on a case-by-case basis, but the average predictions match the data pretty well. When a use a more appropriate GLM, that has better posterior predictive checks, the averaged predictions are way off.
Backstory: There are several features and users are able to select their preferred combination. Afterwards they enter a preferred price for the selected features. I have a dataset on those preferred prices. The problem is, that there is data missing for cases that have selected only one of the features. The datasets contains cases where the features has been included in a combination.
Furthermore, there is a preferred price for a similar service in the dataset, so I know each user’s general price preference (highly correlated with the preferred price for the selected features).
Using brms the simple Gaussian model looks like this:
df_train <- read_csv(...)
bm.gauss <- brm(PPrice_Combination <- Feature_1 + Feature_2 + Feature_3 + PPrice_Alternative, data = df_train, family = Gaussian())
Feature_1 through Feature_3 are 0/1-coded. PPrice_Combination and PPrice_Alternative are continuous, positive values.
Model converges and looks fine. Looking at the posterior predictive checks, the model obviously doesn’t fit very well:

Looking at the model’s posterior predictions, unsurprisingly, they don’t really make sense with a lot of negative values. When comparing the averaged predictions for each combination to the actual averages, the model performs pretty well, though:
| Feature Selection | Actual Mean | Predicted Mean |
|---|---|---|
| 1 | 144.06 | 144.06 |
| 1 + 2 | 309.62 | 309.62 |
| 1 + 2 + 3 | 362.18 | 362.18 |
| 1 + 3 | 589.25 | 589.25 |
| 2 + 3 | 516.41 | 516.41 |
Looks pretty overfit, but predictions for the missing features look very sensible:
| Feature Selection | Actual Mean | Predicted Mean |
|---|---|---|
| 2 | - | 37.77 |
| 3 | - | 216.72 |
Now, the model is obviously wrong, but useful. Since it would be interesting to have better predictions for individual users, I was looking for a better model. As all responses are positive, I was looking into a lognormal model:
bm.lognorm <- brm(PPrice_Combination <- Feature_1 + Feature_2 + Feature_3 + PPrice_Alternative, data = df_train, family = lognormal())
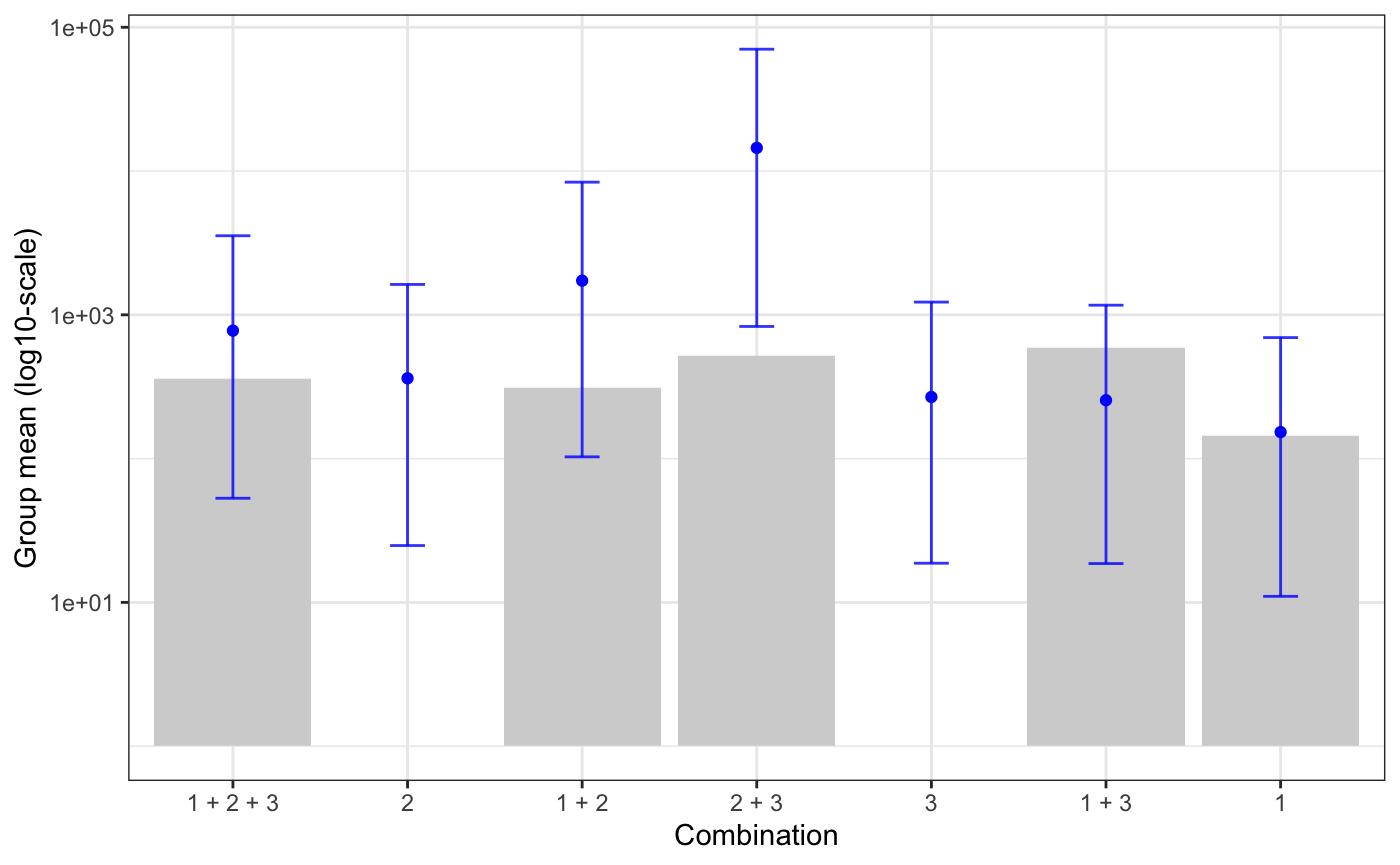
Comparing the model using WAIC favors the lognormal model and posterior predictive check looks better:

But predictions are pretty off:
| Feature Selection | Actual Mean | Predicted Mean |
|---|---|---|
| 1 | 144.06 | 94.81 |
| 1 + 2 | 309.62 | 1081.95 |
| 1 + 2 + 3 | 362.18 | 440.18 |
| 1 + 3 | 589.25 | 201.66 |
| 2 + 3 | 516.41 | 8680.69 |
So, despite being a better model, the predictions are not really as good so that I would put faith in them. It’s really interesting to see this go like this, but I was wondering what possible steps would be to improve the model and its predictions. I have tried using other models or transformations (such as log-transforming or standardising the responses), but model fit or prediction accuracy did not increase.
Any recommendations for a better approach?
Thanks!
Chris