I have a very simple hydrological model. The model can be simply conceptualised as below:

I am trying to learn the values of the parameters a, b and c.
Where:
P = Precipitation Inputs
L = Losses
S = Storage (groundwater / soil)
Qf = Fast Flow
Qs = Slow Flow
a = Proportion of P[t] passing into S[t]
b = Proportion of P[t] lost (e.g. to evaporation)
c = Proportion of S[t] passing into Qs[t] (slow flow)
The equations are:
Q[t] = Qf[t] +Qs[t]
Qs[t] = S[t] * c
Qf[t] = P[t] * (1 - a - b)
S[t] = S[t - 1] * (1 - c) + (P[t] * a)
L[t] = P[t] * b
In python this model looks like this:
def abcmodel(
P: float,
S: float,
a: float,
b: float,
c: float,
) -> Tuple[float, float]:
"""Modelling flow using ABC model
Args:
P (float): Precipitatio
S (float): Storage (groundwater / soil)
a (float): proportion of precipitation into storage bounds: 0-1
b (float): proportion of precipitation lost bounds: 0-1
c (float): proportion of storage becoming low flow bounds: 0-1
Returns:
Q (float): discharge
S (float): storage
"""
L = b * P
Qf = (1 - a - b) * P
Qs = c * S
dsdt = (a * P) - (c * S)
Q = Qf + Qs
return Q, dsdt
def run_abcmodel(
initial_state: float,
precip: np.ndarray,
a: float,
b: float,
c: float,
):
num_timesteps: int = len(precip)
# intialize arrays to store values
qsim = np.zeros(num_timesteps, np.float64)
storage = np.zeros(num_timesteps, np.float64)
# initialize inital state (storage)
storage[0] = initial_state
for t in range(1, num_timesteps):
# run the simulations
Q, dsdt = abcmodel(
P=precip[t],
S=storage[t - 1],
a=a,
b=b,
c=c
)
# Calculate the streamflow
qsim[t] = Q
# Update the storage
storage[t] = storage[t - 1] + dsdt
return qsim, storage
(see below for a working example of the python code).
I want to use Stan to optimise the parameters and get uncertainty estimates of their values.
Longer term I want to add complexity by including observation error (in Q) and process error (from the ABC model).
My stan code is looking something like this (with gaps - sorry!)
functions{
real[] abcmodel(
real a,
real b,
real c,
real[] precip,
real[] S,
){
# do i want to return dsdt
# dsdt[i] = (a * P[i]) - (c * S[i - 1])
# but S is unobserved?
# Q is observed so I want to return a simulated Q ?
}
}
data{
int<lower=0> T;
real Q[T];
real P[T];
}
parameters{
real<lower=0, upper=1> a;
real<lower=0, upper=1> b;
real<lower=0, upper=1> c;
}
model{
real qsim[T];
real S[T];
# do I want to use `integrate_ode_rk45` ?
}
Any help is very much appreciated!
Current code:
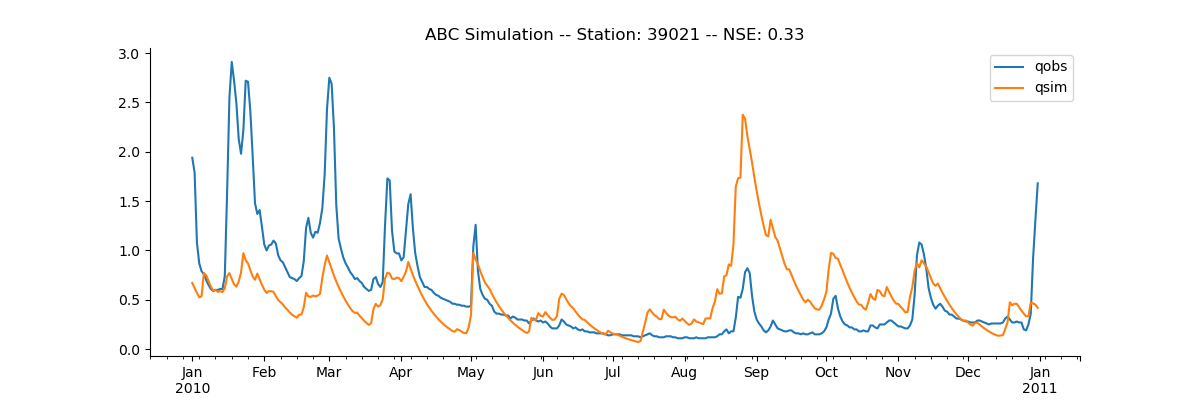
Here is a working python example of the model with a method for selecting the parameters (Using - scipy.optimize.differential_evolution)
abcmodel_example.py (4.0 KB)
Here’s the attempted cmdstanpy file
cmdstanpy_attempt1.py (837 Bytes)
And the stan attempt
abcmodel.stan (563 Bytes)