Hello!
I’m wondering if there is a faster / better way of accessing sampler diagnostics for CmdStanFit objects created by cmdstanr when there are many parameters and generated quantities. The fit$sampler_diagnostics() method seems to be very slow! It seems that I can perhaps generate quantities in a separate step - not sure if that will help with speedup of convergence checks? The context is that I’m trying to scale up a model to fit / predict many hundreds of times, and I would like to automate divergence and convergence checks so that I can make things break when they need to, triggering deeper triage and review, but pass otherwise to prediction. As I said I’ve tried with the methods described in the Getting Started, but extracting the fit diagnostics seems to take nearly as long as fitting the model! I’ve also tried converting to a stanfit object, but that also seems to take a long time. Perhaps there are arguments / methods / techniques that I’m missing, or maybe I’m stuck with a long wait.
Thanks!
Yes, do the generated quantities separately as I’m pretty sure they are otherwise included in the diagnostic computations.
Another idea is that you can monitor the csv files during sampling. See here for an example csv monitor (but please forgive the atrocious code; written a loooong time ago before I learned better dev practices).
If you work up your own code, be sure to share it as I aim to add diagnostics-during-sampling as an option after I’m done adding progress bars
Yeah, you probably have a huge CSV file that takes time to read in. We know there is a problem with very large files that should be fixed by https://github.com/stan-dev/cmdstanr/pull/318
If you want, you can try remotes::install_github("stan-dev/cmdstanr@fread") and see if that helps you. The feature is not quite polished yet, but should work.
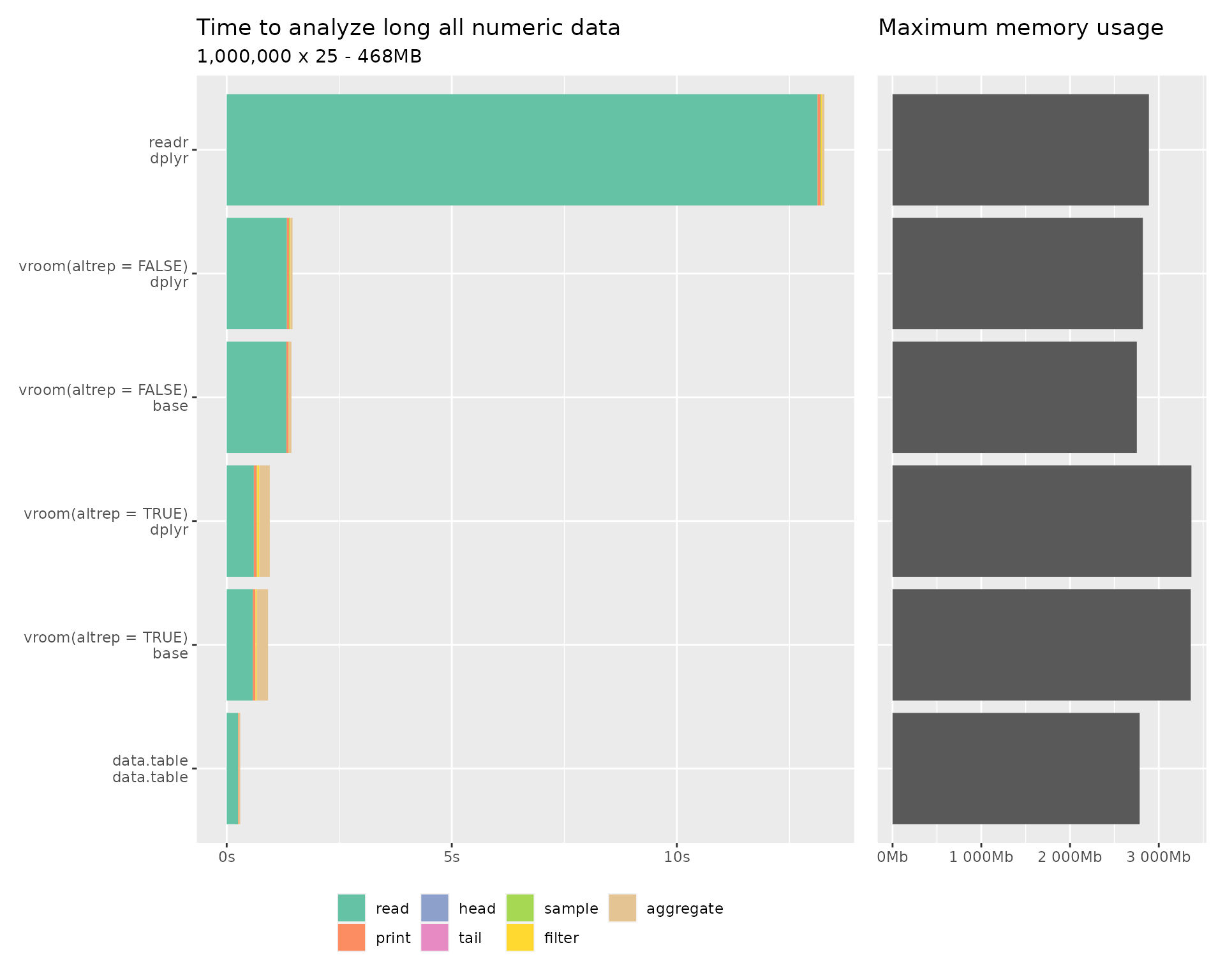
Thanks @rok_cesnovar - interesting that fread is faster than vroom given the benchmarks they published.
Our case is “all numeric data” (see below) and we also had to use the version altrep = FALSE because it otherwise caused problems with removing the temporary CSV files created with cmdstanr. This was related to https://github.com/r-lib/vroom/issues/177 that was closed but was not entirely fixed in my opinion.