Apologies in advance for the large model, I’ve tried to make it as reader-friendly as possible.
I’m attempting to estimate a mixture of latent factors using stan, and I wanted to make sure that my code was doing what I thought it was doing. The model has two parts: the measurement (factor) model, and the mixture model. The conceptual/statistical background is covered in this paper: http://www.statmodel.com/bmuthen/articles/Article_100.pdf
To make it more complicated, I’m also attempting to implement the BSEM approach of identification for cross-loadings and residual covariances (zero-mean, small variance priors), and relax the assumption of local independence (zero covariance within class) using the same approach. This is using ordinal data (33 items, 3 categories).
Here’s a diagram of what I’m aiming to estimate (circles represent latent variables and rectangles observed variables):
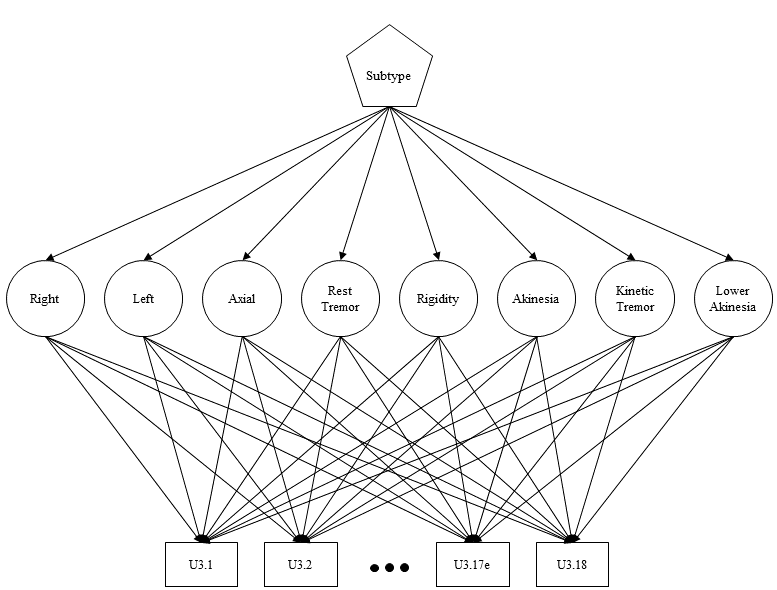
And here’s the model I’m using for it:
data{
int N; //Observations
int J; //Items
int E; //Latent factors
int K; //Clusters
int y[N,J]; //Responses
int right[11]; //List of loadings
int r_n[22]; //List of loadings
int left[11]; //list of loadings
int l_n[22]; //list of loadings
vector[J] sig; //sqrt((pi^2)/3) - SD of logistic residuals
real i_var; //sqrt(5) - SD of intended loadings/thresholds/cluster means
real u_var; //sqrt(0.01) - SD of cross-loadings
}
parameters{
matrix[J,E] lam; //Matrix of factor loadings
row_vector[E] eta[N]; //Vector of factor scores
vector[J] eps_raw[N]; //Vector of unobserved response variables: Non-centered parameterization
ordered[(K-1)] mu_raw[E]; //Vector of latent factor means within cluster
ordered[3] alpha[J]; //Item thresholds
simplex[K] theta; //Cluster proportions
cholesky_factor_corr[E] e_Lcorr1; //Latent factor correlations - Cluster 1
cholesky_factor_corr[E] e_Lcorr2; //Latent factor correlations - Cluster 2
cholesky_factor_corr[E] e_Lcorr3; //Latent factor correlations - Cluster 3
cholesky_factor_corr[J] u_Lcorr; //Residual covariances
}
transformed parameters{
vector[J] epsilon[N]; //Unobserved response underlying categorical response
vector[E] mu[K]; //Cluster means
for(e in 1:E){ //Latent means are identified by fixing the means of the first cluster to 0
mu[1,e] = 0; // and defining the means of the others by their difference from the first
mu[2,e] = mu[1,e] - mu_raw[e,1];
mu[3,e] = mu[1,e] - mu_raw[e,2];
}
//Response is sum of loadings on Latents
//Unobserved response response variable is MVN with mean equal to sum of loadings on
// each latent factor, i.e. (eta[n,1]*lam[j,1]) + ... + (eta[n,8]*lam[j,8]),
// SD of sqrt((pi^2)/3), and with correlations in u_Lcorr
for(n in 1:N){
epsilon[n] = (eta[n]*lam')' + (diag_pre_multiply(sig,u_Lcorr)*(eps_raw[n]));
}
}
model{
vector[K] contrib[N]; //Vector to hold log-probability contributions
//Factor Loadings
//Right
for(j in right[1]:right[11]){lam[j,1] ~ normal(0,i_var);}
for(j in r_n[1]:r_n[22]){lam[j,1] ~ normal(0,u_var);}
//Left
for(j in left[1]:left[11]){lam[j,2] ~ normal(0,i_var);}
for(j in l_n[1]:l_n[22]){lam[j,2] ~ normal(0,u_var);}
//Axial
lam[1,3]~ normal(0,i_var);
lam[2,3]~ normal(0,i_var);
lam[18,3]~ normal(0,i_var);
lam[19,3]~ normal(0,i_var);
lam[20,3]~ normal(0,i_var);
lam[21,3]~ normal(0,i_var);
lam[22,3]~ normal(0,i_var);
lam[23,3]~ normal(0,i_var);
for(j in 3:17){lam[j,3]~ normal(0,u_var);}
for(j in 24:33){lam[j,3]~ normal(0,u_var);}
//Rest Tremor
for(j in 28:33){lam[j,4]~ normal(0,i_var);}
for(j in 1:27){lam[j,4]~ normal(0,u_var);}
//Rigidity
for(j in 3:7){lam[j,5]~ normal(0,i_var);}
for(j in 1:2){lam[j,5]~ normal(0,u_var);}
for(j in 8:33){lam[j,5]~ normal(0,u_var);}
//Akinesia
for(j in 8:13){lam[j,6]~ normal(0,i_var);}
for(j in 1:7){lam[j,6]~ normal(0,u_var);}
for(j in 14:33){lam[j,6]~ normal(0,u_var);}
//Kinetic Tremor
for(j in 24:27){lam[j,7]~ normal(0,i_var);}
for(j in 1:23){lam[j,7]~ normal(0,u_var);}
for(j in 28:33){lam[j,7]~ normal(0,u_var);}
//Lower Akinesia
for(j in 14:17){lam[j,8]~ normal(0,i_var);}
for(j in 1:13){lam[j,8]~ normal(0,u_var);}
for(j in 18:33){lam[j,8]~ normal(0,u_var);}
//Item Thresholds
for(j in 1:J)
for(r in 1:3)
alpha[j,r] ~ normal(0,i_var);
//Latent Factor Means
for(e in 1:E){
mu_raw[e] ~ normal(0,i_var);
}
//Within-cluster factor correlations
e_Lcorr1 ~ lkj_corr_cholesky(50);
e_Lcorr2 ~ lkj_corr_cholesky(50);
e_Lcorr3 ~ lkj_corr_cholesky(50);
//Residual covariances
u_Lcorr ~ lkj_corr_cholesky(50);
//Cluster proportions
theta ~ dirichlet(rep_vector(10,K));
for(n in 1:N){
//Clustering process
contrib[n,1] = log(theta[1]) + multi_normal_cholesky_lpdf(eta[n] | mu[1],e_Lcorr1);
contrib[n,2] = log(theta[2]) + multi_normal_cholesky_lpdf(eta[n] | mu[2],e_Lcorr2);
contrib[n,3] = log(theta[3]) + multi_normal_cholesky_lpdf(eta[n] | mu[3],e_Lcorr3);
target += log_sum_exp(contrib[n,]);
//'Raw' variable for non-centered unobserved response variable
eps_raw[n] ~ normal(0,1);
//Observed data
for(j in 1:J){y[n,j] ~ ordered_logistic(epsilon[n,j],alpha[j]);}
}
}// end of model
generated quantities{
matrix[N,J] log_lik; //log-likeliood for psis-loo/waic
vector[K] log_Pr[N]; //Individual log-probability of membership to each cluster
for(n in 1:N){
vector[K] prob;
for(j in 1:J){
log_lik[n,j] = ordered_logistic_lpmf(y[n,j] | epsilon[n,j],alpha[j]);
}
prob[1] = log(theta[1]) + multi_normal_cholesky_lpdf(eta[n] | mu[1],e_Lcorr1);
prob[2] = log(theta[2]) + multi_normal_cholesky_lpdf(eta[n] | mu[2],e_Lcorr2);
prob[3] = log(theta[3]) + multi_normal_cholesky_lpdf(eta[n] | mu[3],e_Lcorr3);
log_Pr[n,1] = prob[1] - log_sum_exp(prob);
log_Pr[n,2] = prob[2] - log_sum_exp(prob);
log_Pr[n,3] = prob[3] - log_sum_exp(prob);
}
}
First of all, is this estimating the model that I’m trying to estimate? And secondly, are there any ways of optimising this? I’ve tried to vectorise and use the non-centered parameterization where possible, but any suggestions would be greatly appreciated.
Let me know if I can provide any more info to help clarify, I’d be very grateful for any help.
Cheers,
Andrew