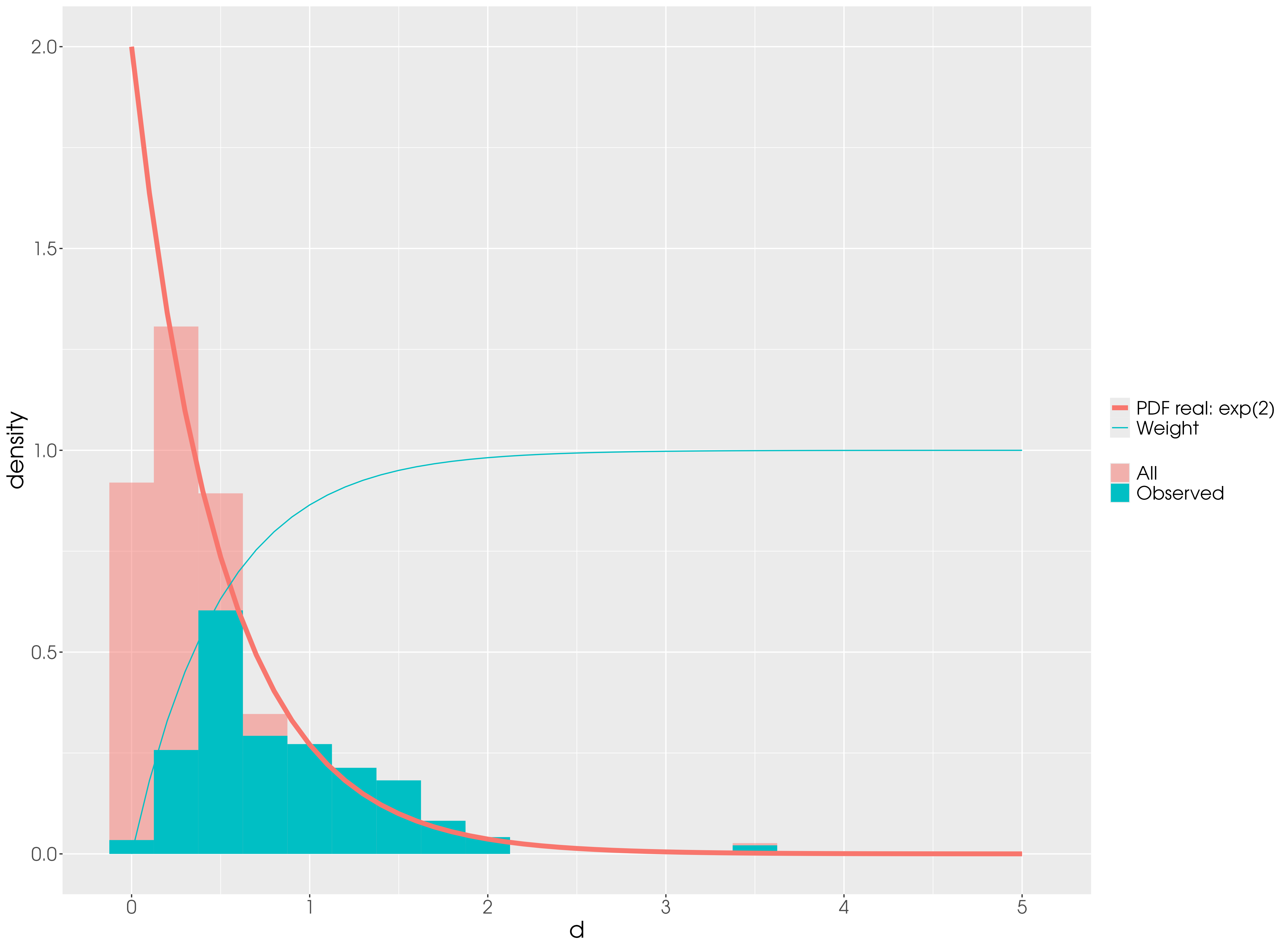
I would like to estimate the parameter of a distribution but there are some data missing (let’s say about 50%). The data are not missing at random, however, but they are dependent on a weighting function. Basically, we can trust the tail of the distribution, but not the bulk of it. In the figure below, the red distribution is the complete data but we observed only the blue one. Our hypothesis is that the observed data were sampled from the complete distribution according to a weighting function (in this specific case it is the cumulative distribution function of the exponential distribution)
My attempt was to attach a weight to each observed data point and run
m <- brm(d|weights(w) ~ 1,
family = exponential,
...
)
but this has not yielded a good fit. The real lambda is 2 but the estimate is about 0.84 as shown by the black lines in the figure below:

Do you have any suggestions on how I could incorporate a “weighting/missingness” function in the model? Ideally, I would also want to estimate the parameters of that function.
I attach a minimal working example that generates the data, fit, and figures:
library("tidyverse")
library("brms")
library("tidybayes")
SEED <- 20220510
set.seed(SEED)
RATE <- 2
N <- 300
X <- seq(0, 5, by=0.1)
P_BIAS <- 0.5
exp_pdf <- tibble(
x = X,
pdf = dexp(x, rate = RATE))
w_curve <- tibble(x = X, y = pexp(x, rate = RATE))
df <- tibble(d = rexp(N, rate = RATE), w = pexp(d, rate = RATE))
df_biased <- df %>% sample_frac(size = P_BIAS, replace = TRUE, weight = w) %>%
mutate(w_post = pexp(d, rate = RATE))
df %>%
ggplot() +
geom_histogram(aes(x = d, y=after_stat(density), fill = 'All'), alpha = 0.5, position = "identity",binwidth = 0.25) +
geom_histogram(aes(x = d, y=after_stat(density)*P_BIAS, weight=w, fill = 'Observed'), position = "identity",binwidth = 0.25, data = df_biased) +
geom_line(aes(x=x, y=pdf, color=sprintf('PDF real: exp(%d)', {{RATE}})), size=2, data=exp_pdf) +
geom_line(aes(x=x, y=y, color = 'Weight'), data=w_curve) +
labs(color = NULL, fill = NULL) +
theme(text = element_text(size=20))
ggsave('empirical.png')
m <- brm(d|weights(w) ~ 1,
data = df_biased,
family = exponential,
seed = SEED,
file = 'exponential-bias.rds'
)
fit <- tibble(remove =NA) %>%
tidybayes::add_epred_draws(m, transform = T, seed = SEED) %>%
ungroup() %>%
select(-c(.chain, .iteration, remove)) %>%
mutate(x = list(X)) %>%
rowwise() %>%
mutate(
lambda = 1/.epred,
pdf=list(dexp(x, rate=lambda))
) %>%
unnest(cols = c(x, pdf))
fit_sample <- fit %>%
sample_draws(25, seed = SEED)
df %>%
ggplot() +
geom_histogram(aes(x = d, y=after_stat(density), fill = 'All'), alpha = 0.5, position = "identity",binwidth = 0.25) +
geom_histogram(aes(x = d, y=after_stat(density)*P_BIAS, weight=w, fill = 'Observed'), position = "identity",binwidth = 0.25, data = df_biased) +
geom_line(aes(x=x, y=pdf, color=sprintf('PDF real: exp(%d)', {{RATE}})), size = 2, data=exp_pdf) +
geom_line(aes(x=x, y=y, color = 'Weight'), data=w_curve) +
geom_line(aes(x=x, y=pdf, group=.draw),alpha = 0.25, data=fit_sample) +
labs(color = NULL, fill = NULL) +
theme(text = element_text(size=20))
ggsave('fit.png')
