C++ code used to compare c++ function speed with how they are implemented in Stan:
for the original functions :
#include <Rcpp.h>
using namespace Rcpp;
using namespace std;
// [[Rcpp::export]]
double inv_logit(double x){
return 1.0 / (1.0 + exp(-x));
}
// [[Rcpp::export]]
vector<double> fun1(vector<double> x_vals, double m, double u, double log_alpha) {
int N = x_vals.size();
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = log(exp(m) + (exp(u) - exp(m)) * inv_logit(exp(log_alpha) * x_vals[i]));
// log(exp(m) + (exp(u) - exp(m)) * inv_logit(exp(log_alpha) * x));
}
return out;
}
// [[Rcpp::export]]
vector<double> fun2(vector<double> x_vals, double m, double u, double log_alpha) {
int N = x_vals.size();
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = log(exp(m) + (exp(u) - exp(m)) / (1 + exp(-exp(log_alpha) * (x_vals[i]))));
// 2. log(exp(m) + (exp(u) - exp(m)) / (1 + exp(-exp(log_alpha) * (x_vals))));
}
return out;
}
// [[Rcpp::export]]
vector<double> fun3(vector<double> x_vals, double m, double u, double log_alpha) {
int N = x_vals.size();
double f = log((exp(u) - exp(m)) / exp(m));
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p(exp(f) * inv_logit(exp(log_alpha) * x_vals[i]));
// 3. m + log1p(exp(f) * inv_logit(exp(log_alpha) * x_vals));
}
return out;
}
// [[Rcpp::export]]
vector<double> fun4(vector<double> x_vals, double m, double u, double log_alpha) {
int N = x_vals.size();
double f = log(((exp(u) - exp(m)) / exp(m)));
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p(exp(f - log1p(exp(-exp(log_alpha) * x_vals[i]))));
// 4. m + log1p_exp(f - log1p_exp(-exp(log_alpha) * x_vals));
}
return out;
}
// [[Rcpp::export]]
vector<double> fun5(vector<double> x_vals, double m, double u, double log_alpha) {
int N = x_vals.size();
double f = log(((exp(u) - exp(m)) / exp(m)));
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p(exp(f + log(inv_logit(exp(log_alpha) * x_vals[i]))));
// 5. m + log1p_exp(f + log_inv_logit(exp(log_alpha)* x_vals));
}
return out;
}
for the new ones :
#include <Rcpp.h>
using namespace Rcpp;
using namespace std;
double inv_logit(double x){
return 1.0 / (1.0 + exp(-x));
}
// [[Rcpp::export]]
vector<double> f1 (vector<double> x, double m, double u, double log_alpha) {
int N = x.size();
double a = exp(log_alpha);
m = exp(m);
u = exp(u);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = log( m + ( u - m) * inv_logit( a * x[i]));
// log(exp(m) + (exp(u) - exp(m)) * inv_logit(exp(log_alpha) * x));
}
return out;
}
// [[Rcpp::export]]
vector<double> f2 (vector<double> x, double m, double u, double log_alpha) {
int N = x.size();
double a = exp(log_alpha);
m = exp(m);
u = exp(u);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = log( m + ( u - m) / (1 + exp(- a * x[i])));
// log(exp(m) + (exp(u) - exp(m)) ./ (1 + exp(-exp(log_alpha) * (x))));
}
return out;
}
// [[Rcpp::export]]
vector<double> f3 (vector<double> x, double m, double u, double log_alpha) {
int N = x.size();
double f = (exp(u) - exp(m)) / exp(m);
double a = exp(log_alpha);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p( f * inv_logit( a * x[i]));
// m + log1p(exp(u) * inv_logit(exp(log_alpha) * x));
// ??? u doesn't give right result
}
return out;
}
// [[Rcpp::export]]
vector<double> f4 (vector<double> x, double m, double u, double log_alpha) {
double f = log( (exp(u) - exp(m)) / exp(m) );
int N = x.size();
double a = exp(log_alpha);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p(exp(f - log1p_exp(- a * x[i])));
// m + log1p_exp(u - log1p_exp(-exp(log_alpha) * x));
// ??? u doesn't give right result
}
return out;
}
// [[Rcpp::export]]
vector<double> f5 (vector<double> x, double m, double u, double log_alpha) {
double f = log( (exp(u) - exp(m)) / exp(m) );
int N = x.size();
double a = exp(log_alpha);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = m + log1p(exp(f + log_inv_logit( a * x[i])));
// m + log1p_exp(u + log_inv_logit(exp(log_alpha) * x));
// ??? u doesn't give right result
}
return out;
}
// [[Rcpp::export]]
vector<double> f6 (vector<double> x, double m, double u, double log_alpha) {
int N = x.size();
double a = exp(log_alpha);
m = exp(m);
vector<double> out(N);
for(int i = 0; i < N; i++){
out[i] = log(exp(log(inv_logit( a * x[i])) + u) + m);
// log(exp(log_inv_logit(exp(log_alpha) * x ) + u) + exp(m));
}
return out;
}
Then the stan model (ammd_mod.stan):
functions {
vector f1 (real m, real u, real log_alpha, vector x) {
return log(exp(m) + (exp(u) - exp(m)) * inv_logit(exp(log_alpha) * x));
}
vector f2 (real m, real u, real log_alpha, vector x) {
return log(exp(m) + (exp(u) - exp(m)) ./ (1 + exp(-exp(log_alpha) * (x))));
}
vector f3 (real m, real u, real log_alpha, vector x) {
real f = (exp(u) - exp(m)) / exp(m); //no need to log it if you exp it next line
return m + log1p(f * inv_logit(exp(log_alpha) * x));
}
vector f4 (real m, real u, real log_alpha, vector x) {
real f = log( (exp(u) - exp(m)) / exp(m) );
return m + log1p_exp(f - log1p_exp(-exp(log_alpha) * x));
}
vector f5 (real m, real u, real log_alpha, vector x) {
real f = log( (exp(u) - exp(m)) / exp(m) );
return m + log1p_exp(f + log_inv_logit(exp(log_alpha) * x));
}
vector f6 (real m, real u, real log_alpha, vector x) {
// real a = log_diff_exp(u, m);
return log(exp(log_inv_logit(exp(log_alpha) * x) + u) + exp(m));
}
}
data {
int<lower=0> N;
vector[N] x_vals;
array[N] int y_count;
int test;
}
parameters {
real m;
real u;
real log_alpha;
}
model {
m ~ normal(.69, .1);
u ~ normal(2.3, .1);
log_alpha ~ normal(0, .1);
vector[N] log_mu;
profile("meanpart"){
if (test == 1) log_mu = f1(m, u, log_alpha, x_vals);
if (test == 2) log_mu = f2(m, u, log_alpha, x_vals);
if (test == 3) log_mu = f3(m, u, log_alpha, x_vals);
if (test == 4) log_mu = f4(m, u, log_alpha, x_vals);
if (test == 5) log_mu = f5(m, u, log_alpha, x_vals);
if (test == 6) log_mu = f6(m, u, log_alpha, x_vals);
}
y_count ~ poisson_log(log_mu);
}
The stan file to only profile the function with fix params (ammd_funOnly.stan):
functions {
vector f1 (real m, real u, real log_alpha, vector x) {
return log(exp(m) + (exp(u) - exp(m)) * inv_logit(exp(log_alpha) * x));
}
vector f2 (real m, real u, real log_alpha, vector x) {
return log(exp(m) + (exp(u) - exp(m)) ./ (1 + exp(-exp(log_alpha) * (x))));
}
vector f3 (real m, real u, real log_alpha, vector x) {
real f = (exp(u) - exp(m)) / exp(m); //no need to log it if you exp it next line
return m + log1p(f * inv_logit(exp(log_alpha) * x));
}
vector f4 (real m, real u, real log_alpha, vector x) {
real f = log( (exp(u) - exp(m)) / exp(m) );
return m + log1p_exp(f - log1p_exp(-exp(log_alpha) * x));
}
vector f5 (real m, real u, real log_alpha, vector x) {
real f = log( (exp(u) - exp(m)) / exp(m) );
return m + log1p_exp(f + log_inv_logit(exp(log_alpha) * x));
}
vector f6 (real m, real u, real log_alpha, vector x) {
// real a = log_diff_exp(u, m);
return log(exp(log_inv_logit(exp(log_alpha) * x) + u) + exp(m));
}
}
data {
int<lower=0> N;
vector[N] x_vals;
array[N] int y_count;
}
parameters {
real m;
real u;
real log_alpha;
}
model {
profile("priors"){
target += normal_lpdf(m | .69, .1);
target += normal_lpdf(u | 2.3, .1);
target += normal_lpdf(log_alpha | 0, .1);
}
profile("f1"){
target += f1(m, u, log_alpha, x_vals);
}
profile("f2"){
target += f2(m, u, log_alpha, x_vals);
}
profile("f3"){
target += f3(m, u, log_alpha, x_vals);
}
profile("f4"){
target += f4(m, u, log_alpha, x_vals);
}
profile("f5"){
target += f5(m, u, log_alpha, x_vals);
}
profile("f6"){
target += f6(m, u, log_alpha, x_vals);
}
}
Finaly the R code used to simulate and compare all that :
# setting up vars
set.seed(1123234)
N <- 100
x_vals <- rnorm(N)
m <- rnorm(1, log(2), .1)
u <- rnorm(1, log(10), .1)
log_alpha <- rnorm(1, 0, .1);
mu <- log((exp(u) - exp(m)) / exp(m))
y_count <- rpois(N, mu)
#-------
# making sure all cpp fun give the same results
data.frame(
fun1 = fun1(x = x_vals, m, u, log_alpha),
fun2 = fun2(x = x_vals, m, u, log_alpha),
fun3 = fun3(x = x_vals, m, u, log_alpha),
fun4 = fun4(x = x_vals, m, u, log_alpha),
fun5 = fun5(x = x_vals, m, u, log_alpha)
)
bmfun.res <- microbenchmark::microbenchmark(
f1 = fun1(x = x_vals, m, u, log_alpha),
f2 = fun2(x = x_vals, m, u, log_alpha),
f3 = fun3(x = x_vals, m, u, log_alpha),
f4 = fun4(x = x_vals, m, u, log_alpha),
f5 = fun5(x = x_vals, m, u, log_alpha),
times = 50
)
bmfun.res <- data.frame(fun = bmfun.res$expr, time = bmfun.res$time/1000) #print in µs but stored in ms Oo
#-------
# making sure all cpp f give the same results
# f6 doesn't
data.frame(
f1 = f1(x = x_vals, m, u, log_alpha),
f2 = f2(x = x_vals, m, u, log_alpha),
f3 = f3(x = x_vals, m, u, log_alpha),
f4 = f4(x = x_vals, m, u, log_alpha),
f5 = f5(x = x_vals, m, u, log_alpha),
f6 = f6(x = x_vals, m, u, log_alpha)
)
bmf.res <- microbenchmark::microbenchmark(
f1 = f1(x = x_vals, m, u, log_alpha),
f2 = f2(x = x_vals, m, u, log_alpha),
f3 = f3(x = x_vals, m, u, log_alpha),
f4 = f4(x = x_vals, m, u, log_alpha),
f5 = f5(x = x_vals, m, u, log_alpha),
f6 = f6(x = x_vals, m, u, log_alpha),
times = 50
)
bmf.res <- data.frame(fun = bmf.res$expr, time = bmf.res$time/1000)
#-------
stan_mod <- cmdstanr::cmdstan_model(stan_file = "./ammd_mod.stan")
stan_mod_sample <- lapply(
`names<-`(1:6, paste0("f", 1:6)),
\(i){
stan_mod$sample(
data = list(N = N,
x_vals = x_vals,
y_count = y_count,
test = i),
parallel_chains = 50,
chains = 50,
refresh = 0
)
}
)
stan_mod_res <- lapply(stan_mod_sample, \(x) do.call(rbind, x$profiles())) |>
data.table::rbindlist(idcol = "fun")
# s to µs to match microbenchmark times
stan_mod_res$time <- stan_mod_res$total_time * 1e+6
#-------
stan_funs <- cmdstanr::cmdstan_model(stan_file = "./ammd_funOnly.stan")
stan_funs_sample <- stan_funs$sample(
data = list(N = N,
x_vals = x_vals,
y_count = y_count
),
parallel_chains = 50,
chains = 50,
fixed_param = TRUE,
refresh = 0
)
stan_funs_res <- stan_funs_sample$profiles() |> lapply(`[`,1:6,) |> data.table::rbindlist()
stan_funs_res$time <- stan_funs_res$total_time * 1e+6
# next line is done just so the graph is more easily readable
stan_funs_res$time[stan_funs_res$time > 200] <- 200
names(stan_funs_res)[1] <- "fun"
#-------
# plotting!
library(ggplot2)
comp_data <- list(stan_mod = stan_mod_res[,c("fun","time")],
cpp_fun = bmfun.res[,c("fun","time")],
cpp_f = bmf.res[,c("fun","time")],
stan_fun = stan_funs_res[,c("fun","time")]) |>
data.table::rbindlist(idcol = "code") |>
(\(x){x$fun = factor(x$fun, sort(unique(x$fun), decreasing = TRUE)); x})()
comp_data$facet <- comp_data$code
comp_data$facet[grep("cpp", comp_data$facet)] <- "cpp"
ggplot(comp_data, aes(y = fun, x = time, color = code)) +
geom_point(alpha = 0.5, size = 2, position = position_jitter(height = 0.25)) +
scale_color_viridis_d(end = 0.8) +
facet_grid(~ facet, scales = "free") +
xlab("time (µs)") +
theme(legend.position = "bottom")
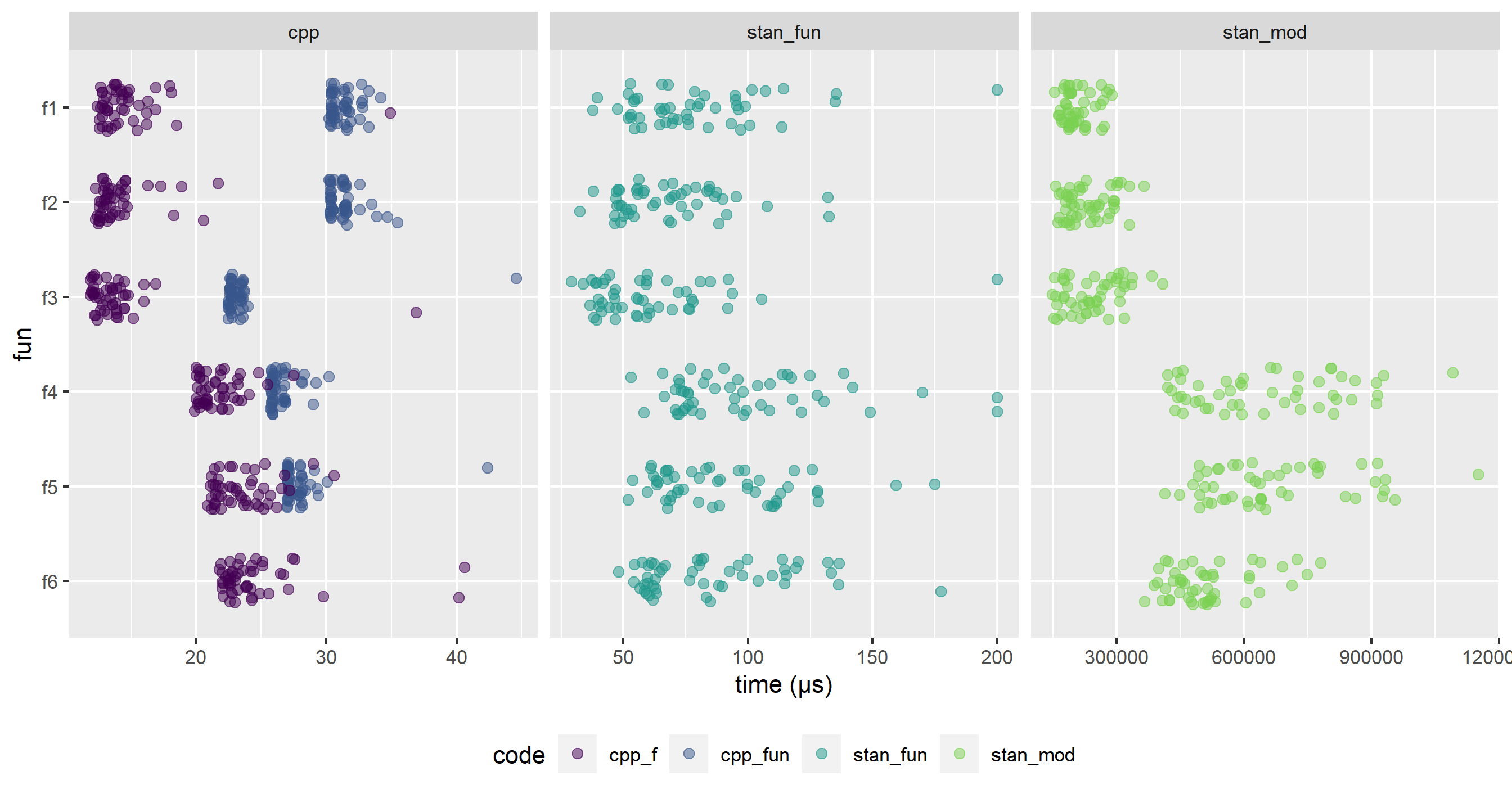
Resulting plot :
So with the original functions (cpp_fun), I thought the diminution in speed for fun[3:5] in Stan(stan_mod) as opposed to cpp was due to the way the functions log, exp and log1p were written. Instead of using directly std::log, std::exp and std::log1p, they add if…else & calls checks and on a loop that can add some time.
However, with the new function, even in cpp the f[4:6] do take longer both in cpp and stan.
I think the faster time for f[1:3] comes from defining double a = exp(log_alpha); m = exp(m); u = exp(u); so they don’t have to be recomputed every iteration.
Note : Another reason f3 is faster than fun3 in cpp and my f3 is faster in stan than ammd’s is because I removed 2 calls : f was log then exp when it could just be left as (exp(u) - exp(m)) / exp(m). (instead of log((exp(u) - exp(m)) / exp(m)) and then exp(f) on the next line.)
Related, re the last part of the last ammd reply :
f5 gets translated to m + log1p(exp(u + log(inv_logit(exp(log_alpha) x)))), so it has one more call than f3 and you log inv_logit(exp(log_alpha) * x) to then exp() it and then log() it again.
In cpp f5 is also half as slow than f3.
The cpp codes do run much faster. I know there are steps that aren’t done relating parameters, but I think part of this could be because of the vectorisation of functions. If I translate the cpp code to Rcpp which allows vectorisation instead of for loops, I do get much lower speed :/