I ran the models from posteriordb again, here a summary of the results:
The code to run the benchmarks is here, the notebook that makes the plots is here.
I used all posteriors in posteriordb, except the following (either because something failed, or because they took too long to sample. I will probably rerun the slower ones soon as well):
too_slow = {
'ecdc0401-covid19imperial_v2',
'ecdc0401-covid19imperial_v3',
'ecdc0501-covid19imperial_v2',
'ecdc0501-covid19imperial_v3',
'election88-election88_full',
'hmm_gaussian_simulated-hmm_gaussian',
'iohmm_reg_simulated-iohmm_reg',
'mnist-nn_rbm1bJ100',
'mnist_100-nn_rbm1bJ10',
'prideprejudice_chapter-ldaK5',
'prideprejudice_paragraph-ldaK5',
'prostate-logistic_regression_rhs',
}
failed = {
'hudson_lynx_hare-lotka_volterra',
'science_irt-grsm_latent_reg_irt',
'sir-sir'
}
This leaves us 132 posteriors to sample.
All of them were run using stan and nutpie, each with 300, 400, 600 and 1000 warmup steps. All combinations with 10 chains and 1000 draws after warmup, on a Threadripper 1920X with 12 physical cores.
Comparing the final mass matrix
First, we can have a look at how well the final mass matrix is working, to mostly exclude changes to the adaptation schema of nutpie. So for the most part this should just show the difference between using diag(cov(draws)) and sqrt(diag(cov(draws)) / diag(cov(grads))) as adaptation target.
I’m using ecdf plots to visualize the distribution of different parameters for the sampler settings in the following.
The absolute effective sample size tends to be a bit smaller with nutpie:
So for 1000 samples we tend to get fewer effective samples from nutpie than we would get from stan.
Curiously this mostly happens for models with effective sample sizes a bit above 1000, below and above there doesn’t seem to be a big difference. No clue what that might be about…
However, stan tends to use more leapfrog steps for each draw, so each draw in stan tends to be more expensive to compute. If we correct for this by looking at the number of effective samples per gradient evaluation (or per time, this looks almost identical), we get an improvement:
If we normalize to stan with 1000 warmup steps by dividing by the effective sample size per gradient evaluation in stan, we get the following:
I think a clear and meaningful improvement, but certainly not a game-changer either.
Comparison including the warmup phase
Nutpie consistently needs fewer gradient evaluations during warmup:
We can again normalize using stan with 1000 warmup steps:
This is the effective sample size per total number of gradient evaluations (so the number of gradient evaluations during warmup plus the number of gradient evaluations during sampling):
If we normalize by stan again:
Nutpie with 400 warmup steps gives us a geometric mean speedup of about 2x compared to stan with 1000 warmup steps (and usually I think those 400 warmup steps are good enough).
The number of effective samples per total sampling time looks quite similar:
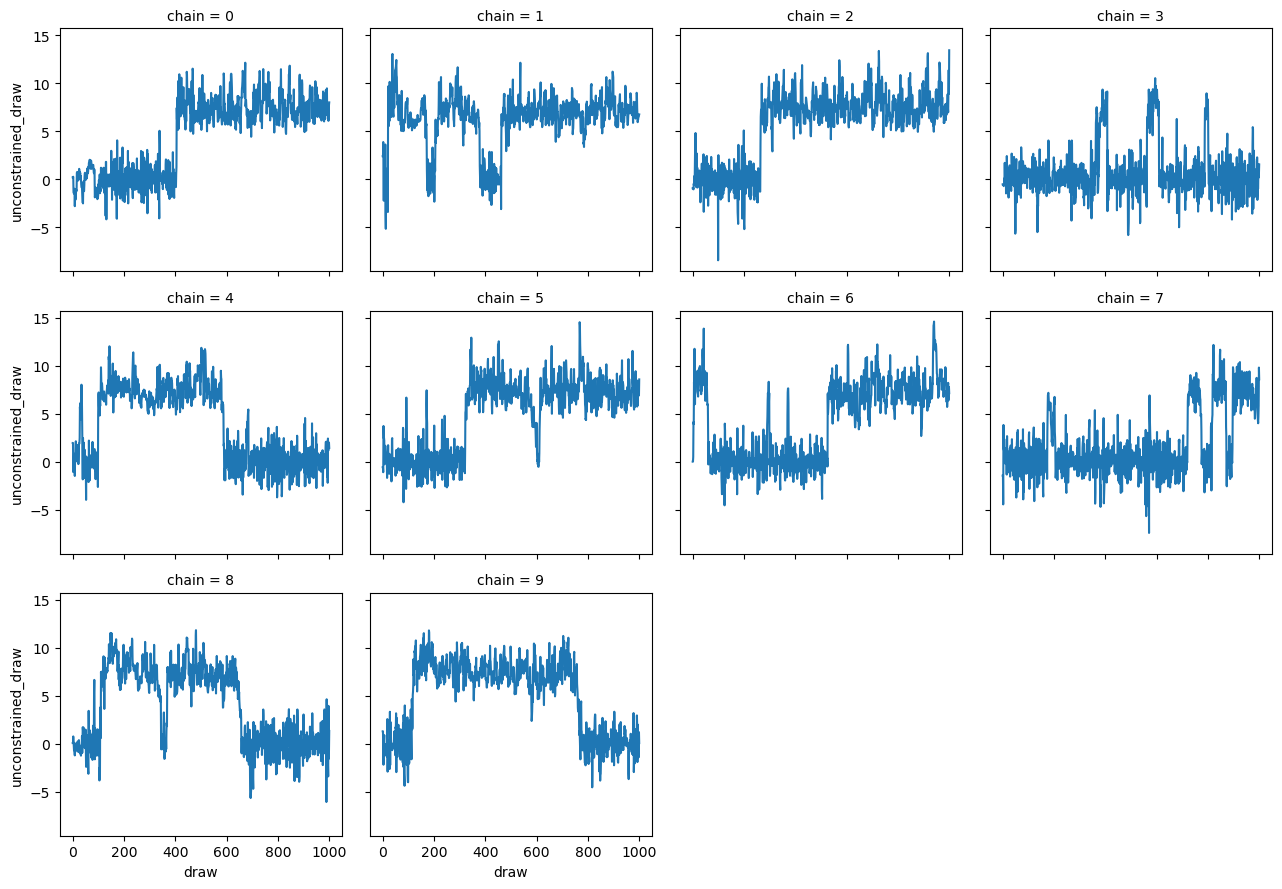
It might also be interesting to have a closer look at those models, where there were big differences between stan and nutpie:
# Stan with 1000 tuning steps was doing better
ovarian-logistic_regression_rhs -4.856620
seeds_data-seeds_stanified_model -4.138525
one_comp_mm_elim_abs-one_comp_mm_elim_abs -3.272695
# Nutpie with 1000 tuning steps was doing better
radon_all-radon_variable_intercept_noncentered 2.091125
loss_curves-losscurve_sislob 2.236644
wells_data-wells_dist 2.291067
radon_all-radon_variable_slope_noncentered 2.629578
radon_all-radon_variable_intercept_slope_noncentered 3.013278
sblri-blr 3.351181
GLMM_Poisson_data-GLMM_Poisson_model 3.662405
mcycle_gp-accel_gp 6.633426
From a quick glance it looks like those were cases where one chain in either sampler is doing something strange.
In general I’m getting the impression that the default of sampling 4 chains might be a bit low, and might hide sampling issues in quite a few models…