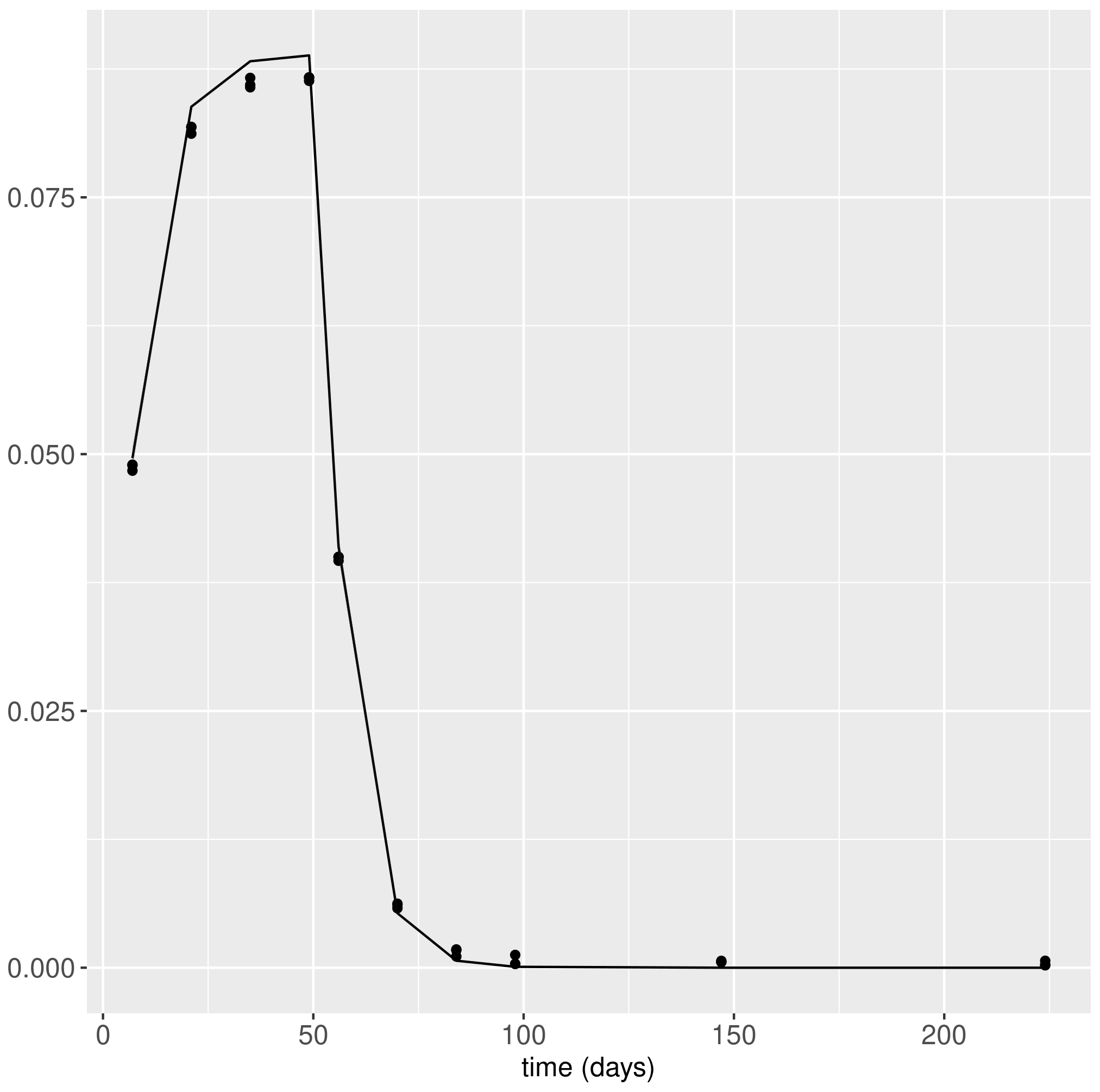
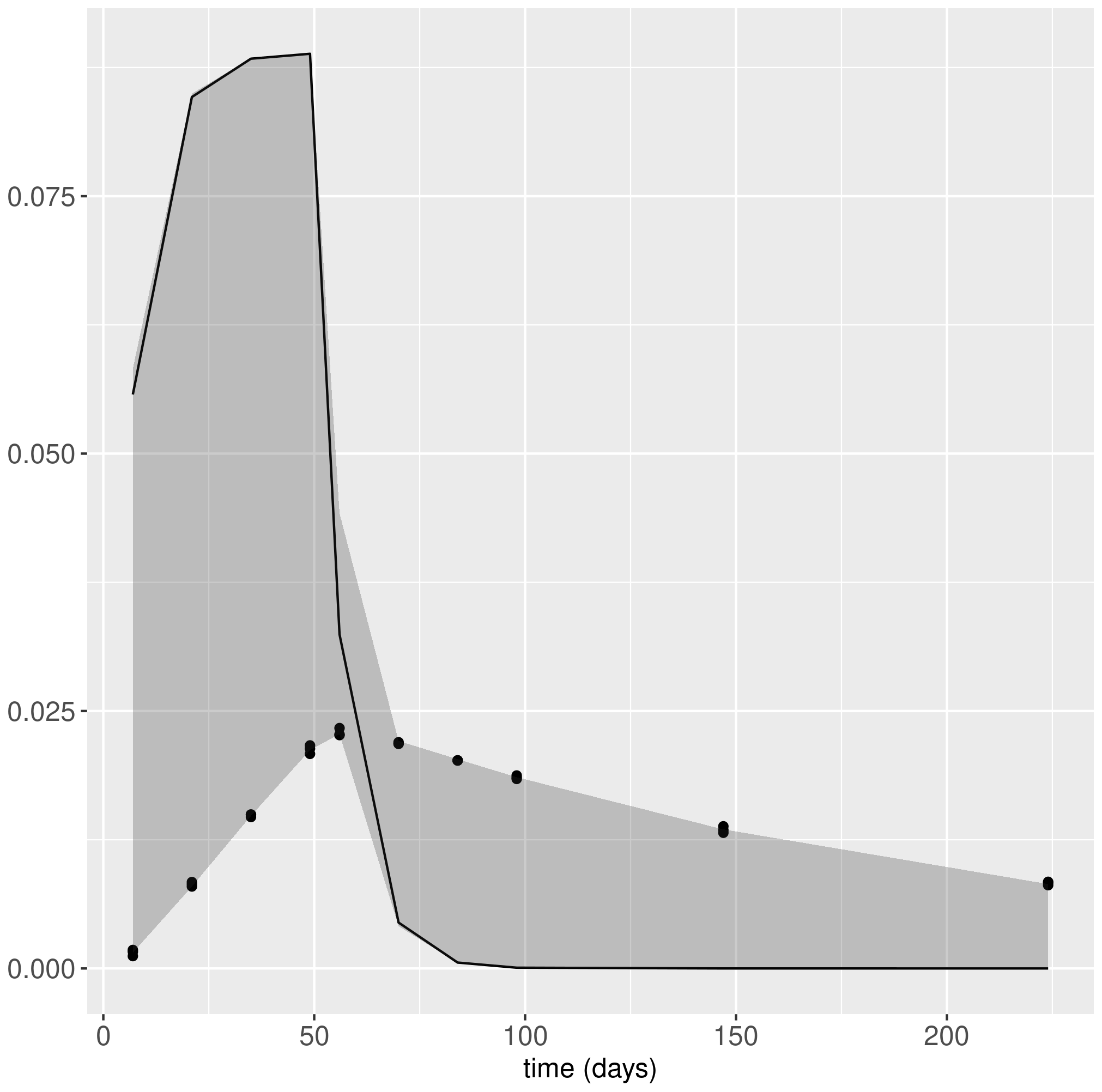
I am currently fitting a two species ODE model to simulated data. The data has been simulated assuming a unidirectional flow from one species to the other.
Fitting two competing models which only differ in terms of the transition between species and performing model comparison via loo, I want to test for which parameter combinations we can successfully identify the “true” model.
The “true” model fits well with the data and we obtain reasonable posteriors. However, fitting the competing model(which still should provide fit fairly well to the data as the model fairly symmetric and the flow between species is quite low) I get some chains which sample “reasonable” parameter values and some chains which explore a completely different part of the parameter space which do not the describe the data at all.
Having read that the problem of divergent chains might be solved by a longer adaptation period, I have run 3 chains at 4000 warm-up/ 1000 sampling iteration, but I still observed above behaviour. Additionally, what I have noticed that when I changed adapt_delta(while keeping a constant seed) running single chains that same problem of ill-fitting chains arose and disappeared depending on the value for adapt-delta choosen
I have attached some posterior predictive checks and trace plots which hopefully illustrate the problem.
What could be the problem? Do I need to extend the warm-up phase even further?
Have you tried reducing the initial step size and increasing adapt_delta to something like 0.9 or even 0.99? If it’s just some steep curvature, this can help immensely. If you have something like the varying curvature of a funnel, this’ll help a bit, but you’ll still get divergences. Often you need to reparameterize.
It’s hard to say more in general without seeing your model. I will comment that it’s odd to see one chain get stuck on just a couple parameters. Usually when that happens, all the parameters get stuck. So maybe there’s just a little bit of variation and it’s not truly stuck in the sense of not updating.
I’m having a similar problem as jmac that at the very least matches the topic title. I’m very new to this forum, so if this would be better served as its own post then I’m happy to make one.
I also am working with simulated data so I know what the “right” parameter values are. In my case I’m running 4 chains, three of which fail to converge to a value and one that becomes sure of its estimate quickly. The three that fail to converge don’t really get particularly close to the true value, while the one that settles on a value quickly is pretty much dead on. I’ve included some plots below from shinystan for one of the hundreds of parameters, but all of the ones I’ve checked look similar.
I know enough to know that this is in no way a stable model. The correct value for alpha[1,1] is -0.56, which chain 1 is sure of by the time the 1000 warmup iterations are complete. What’s also odd is that chain 1 reaches max tree depth on every iteration, despite it getting the correct estimate. I’ve also noticed that chain 1 has significantly smaller stepsizes and larger log posteriors than the other chains, but I’m not sure the significance of that.
My question is whether this is likely a parameterization problem or if I should force stan to use smaller stepsizes to get the correct response. I’ve built the model to replicate as closely as possible the process I used to simulate the data, so I’m not sure how to reparameterize, but I also recognize that limiting the stepsize to very small values is probably not a good solution. I’m happy to share my stan code and how I generated the data, but I’m afraid it is too convoluted for me to expect someone to try and read through it all.
I think you are going to be better off if you add your stan model in separate post. Or even better you can try to break it down in a smaller model where you have the same problem. Ideally, with complicated model you want to build up from small to big model. Once you hit a stumbling block than you can tell which step is causing the problem.
As a guess now, I would look for two opposite things. Maybe the model is not identified. Different combinations of parameters give you almost identical posterior. This can be because the mathematical model is poorly identified, it could also stem from a coding error. For instance, a loop that is not correctly implemented.
The opposite problem is that the model is a deterministic representation of the simulated data. If the correct model can perfectly predict the outcomes in the simulated data, the posterior has probability 0 for any non correct model and 1 for the correct model. Stan doesn’t handle does types of discontinuities well. (The one chain that gets stuck at the correct value could be an indication of something like this).
Thanks for the quick reply! I’ve seen the simple-to-complex suggestion elsewhere before I started building the model so that’s very much what I did. Everything worked fine but the last wrinkle I added – incorporating censored data – seems to be the straw that broke the model’s back.
As for the model being deterministic, when I simulated the data I incorporated an (admittedly small) error term, so I’ll try increasing that to see if that mitigates any problems. I’ll also check to see how well the estimates from the “incorrect” chains actually predict the data to see if there is an identification problem. Failing those, I’ll make a new post that includes the model code. Thanks again for your help!
If there are two different regions of the parameter space that are local optima, then it’s not unusual to get different log densities in the modes. The only thing you can do is try to coax the sampler into starting near the region of the solution—it won’t be able to jump out of a bad mode.
Now if the bad mode has enough probability mass, just keeping to one mode won’t give you the right posterior expectations.
From the first graph, the “different regions”, or more accurately meta-stability, clearly comes from q2=0 and q3=0 I suppose both are sd parameters and it just a funnel-type. I would imagine the easiest solution is to try zap (Zaps to avoid the funnel).