I did, but what I missed was how you revert just 584. How do you do that?
git revert -m1 6fc8e2a598ec1839f82deb0ba81853d0faad5df5. I pushed this revert up to a branch (I had to resolve some conflicts): https://github.com/stan-dev/math/tree/revert
I’m actually a little worried I might not have had proper hygiene so I’m running everything again. Feel free to double check me! I’m not sure when I realized that make clean-all wasn’t deleting the executables generated by cmdstan.
I’m looking at the recorded performance tests around that time… there’s definitely something going on.
@seantalts, I think that PR is the cause of some slowdown. I didn’t check your git invocation, but what I did was look at this:
http://d1m1s1b1.stat.columbia.edu:8080/job/Daily%20Stan%20Performance/
I downloaded this csv file:
http://d1m1s1b1.stat.columbia.edu:8080/job/Daily%20Stan%20Performance/lastSuccessfulBuild/artifact/test/performance/performance.csv
Row 270 is before (910756) and 271 is after (beeb68). They don’t exactly line up with merged PRs, but close enough. It jumps from 2.0 to 5.2. That’s not good.
Yep, that matches my own findings. But you were just a minute ago saying that these numbers weren’t valid because they needed to do 100 seeds and measure n_eff/s, right?
Also I didn’t know (or forgot) about that CSV, good find!
Okay, I deleted my previous graphing post because it turns out my hygiene was bad and I have new numbers (verified twice by myself, others helpful too).
My procedure:
git checkout v2.17.0
make stan-revert
pushd stan
make math-revert
popd
cp stan/src/test/test-models/performance/logistic.stan examples/
make clean-all && rm examples/logistic examples/logistic.hpp; make -j8 bin/stansummary examples/logistic && for i in `seq 1 1000`; do ./examples/logistic sample data file=../stan/src/test/test-models/performance/logistic.data.R > /dev/null && bin/stansummary output.csv | grep lp__ | awk '{print $(NF-1)}'; done > neffs-217-vanilla
and then
pushd stan/lib/stan_math
git fetch
git checkout origin/revert
popd
make clean-all && rm examples/logistic examples/logistic.hpp; make -j8 bin/stansummary examples/logistic && for i in `seq 1 1000`; do ./examples/logistic sample data file=../stan/src/test/test-models/performance/logistic.data.R > /dev/null && bin/stansummary output.csv | grep lp__ | awk '{print $(NF-1)}'; done > neffs-217-sans
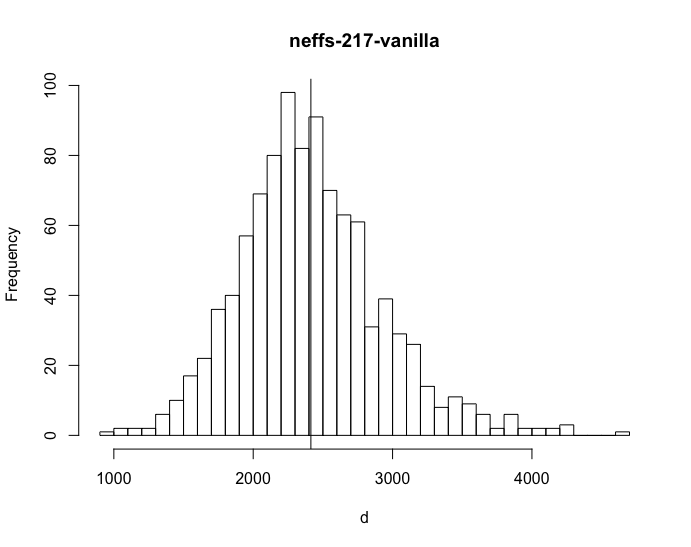
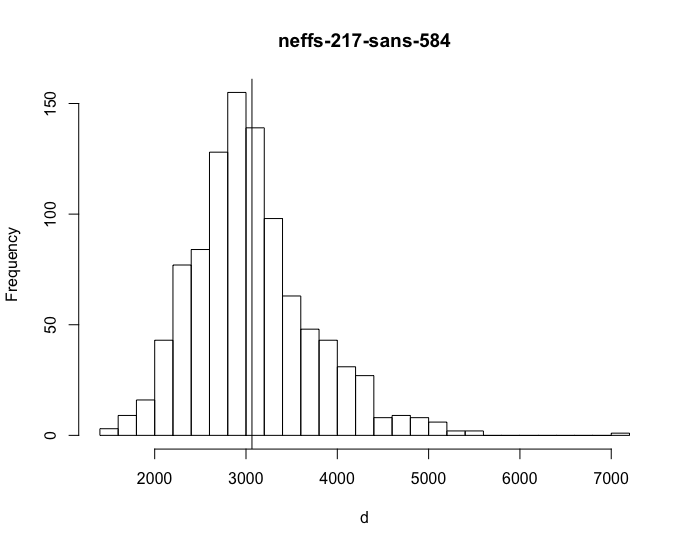
So this is way more clear - higher is better because these are numbers of effective samples per second.
Should I revert PR 584 now?
1 Like
I also verified that on my machine, @jjramsey’s model fit in ~1 minute on 2.17.0 and ~35 seconds with PR 584 reverted. Fake data here (rename to .Rdump): fakeData.Rdump.csv (6.6 KB)
2 Likes
Please revert! Sorry, that was my fault. I thought I tested and timed properly, but I must not have. If you want any help reverting, I can take care of it. I did it, so I am more than willing to put in the effort to back it out.
1 Like
At this point… a big thank you for reporting and coming back to this. Your repeated reporting triggered my and others attention; and it looks like this was for good reason.
Please just post the data on the forum next time as email archives tend to be black holes.
4 Likes
Hey, there are a lot of conflicts with develop so if you don’t mind dealing with those that’d be great - it might be easiest to modify whatever scripts you used to convert forward to go backwards vs. trying to deal with the merge conflicts.
1 Like
I’m on it, but it may take a little longer than today. It’s going to be a lot of manual work to get this teased apart.
I’ve created an issue for it: Math #667
I’ll post here when it’s been updated. Fortunately, this is a performance hit, but doesn’t affect validity of results. Unfortunately, this makes it slower than it needs to be.
FYI, I’ve just tried out a development version of CmdStan with the aforementioned fixes, and it has made a huge difference. Runtimes are reduced to about a quarter of what they were with the release version of Stan 2.17, and are on par with earlier Stan versions.
5 Likes
Thanks for getting involved and also for following up. This is really helpful. I thought I’d get to it and then dropped the ball and nobody else seems to have noticed the thread. We don’t have a good system of triage for things coming into the lists that need to be dealt with.
What I should’ve done is immediately registered this as an issue in the math library (although I didn’t know that was the cause of the problem it’s the most likely suspect).