I ran 100 histograms (not the KS test ones) here (re-running to get the KS test histograms). I didn’t see any n_effs below 26 with 2000 iterations (1000 warmup). Is that too low? I think @betanalpha mentioned 1 in 1000 as being a tipping point for usefulness but I’m not sure how that changes with the model.
When you get to around 1 effective sample per 1000 iterations the estimator for effective sample size starts to behave poorly. 26 out of 1000 should be okay, although 100 out of 1000 would be much better.
Here’s 100 tests with 1000 replications (1 replication = 1 prior draw -> 1000 posterior draws): https://www.dropbox.com/s/9cz0rps910fyjcy/100%20with%20ks%20test.zip?dl=0
Hmmm, those look pretty consistent with variations around a uniform.
-
What happens when you aggregate all of those histograms together? It should look pretty uniform even on the middle binning scale with 100,000 replications.
-
To calibrate our often poor expectations of statistical variation, can you complement those results with 100 replications of drawing 1000 random uniform variates? Bonus points if you call the CGR histograms and the exact uniform histograms A and B or B and A and don’t tell us which is which.
Okay, I don’t know what CGR stands for but one of these is the combined histograms for 100,000 replications with 1000 posterior draws per replication, and the other is data.frame(alpha=runif(1e5), beta=runif(1e5)).
lin_regr_cy100.pdf (20.1 KB)
lin_regr_cx100.pdf (18.6 KB)
CGR = Cook, Gelman, Rubin.
This was a little bit too easy to differentiate. :-) The problem is that we’re not generating 1000 posterior quantiles per replication but rather 1, so I think the appropriate comparison would be 1000 uniform draws. Sorry for the poor instructions!
It shouldn’t be compared against runif. It should be compared against something like
pnorm (rnorm( N_samp, sd= 1 + runif (N_samp,-1/sqrt(n_eff),1/sqrt(n_eff) )))
which better reflects the size of the monte carlo error you’d expect in the histogram.
But long story short, the spike doesn’t seem to be endemic.
There were 1e5 replications, each of which generated a number between 0 and 1 (though always some integer divided by 1000). I suspected that perhaps that discretization was preventing proper convergence to uniformity in the histograms, so I simulated the process more directly with round(runif(1e5) * 1000) / 1000, pdf here: discrete_rng.pdf (20.3 KB)
And here’s Dan’s suggested distribution, with N_samp = 1e5 and n_eff=100: dans_rng.pdf (20.2 KB)
And to be super fun, I discretized Dan’s: discrete.dan.pdf (20.3 KB)
And we see some spikes at 0 in the finer grained histograms! Pretty much every time I’ve run it, too. I’m probably doing something wrong, but this is fun detective work. Here’s my code:
pdfplots = function(name, paramNames, quants_lte, quants_gt) {
plots = function(quants_lte, quants_gt, breaks) {
if (length(paramNames) > 4)
paramNames <- paramNames[0:4]
par(mfrow=c(length(paramNames) + 1, 2))
par(mar=c(4,2,2,1)+0.1)
if (length(paramNames) > 1) {
for (pn in paramNames) {
hist(quants_lte[pn,], breaks = breaks, main=NULL, xlab=pn)
hist(quants_gt[pn,], breaks = breaks, main=NULL, xlab=pn)
}
}
hist(quants_lte, breaks = breaks, main=NULL)
hist(quants_gt, breaks = breaks, main=NULL)
}
pdf(paste(name, "pdf", sep="."))
widths <- c(0.05, 0.01, 0.005)
for (binwidth in widths) {
plots(quants_lte, quants_gt, seq(0, 1, binwidth))
}
dev.off()
}
make_fake_quant = function(gen_data) {
t(data.frame(alpha=gen_data(), beta=gen_data()))
}
dans.rng = function() {pnorm (rnorm( N_samp, sd= 1 + runif (N_samp,-1/sqrt(n_eff),1/sqrt(n_eff) )))}
discrete.rng = function() {round(runif(1e5) * 1000) / 1000}
pdfplots("dans_rng", c("alpha", "beta"), make_fake_quant(dans.rng), make_fake_quant(dans.rng))
pdfplots("discrete_rng", c("alpha", "beta"), make_fake_quant(discrete.rng), make_fake_quant(discrete.rng))
discrete.dan = function() {
round(dans.rng() * 1000) / 1000
}
pdfplots("discrete.dan", c("alpha", "beta"), make_fake_quant(discrete.dan), make_fake_quant(discrete.dan))
I thought you said the effective sample size was 26, not 100? Or did I misunderstand
The lowest one I saw in 1e5 replications was 26 or so. When I use 26, the code you wrote above (without my discretization add on) also produces spikes at 0 and 1 now. But with n_eff = 100, it doesn’t show as prominently until you also discretize it, at which point it shows and looks exactly like some of the Stan results above.
I talked to Michael on the phone and it sounds like maybe this is the core of the issue - basically the n_effs you have really dictates the number of histogram buckets you can have without seeing these weird effects (though unclear why spikes at 0 are very predominant when discretizing). I’m going to run some experiments and see if we can come up with some loose heuristics for how many buckets per n_eff or something similar.
My guess would be that you can have O(n_eff^{1/2}) bins. In this case, most quantiles would be in the correct bin and, in the worst case it will be one on either side. Does 3xn_eff^{1/2} work. That would give the standard 30 bins when n_eff=100
You will always see more extreme behaviour at the boundaries because instead of having 2 directions to be wrong in, there’s only one.
1 Like
I think that scaling is correct but here the coefficient will be really important. I was thinking 1000 effective samples and 50 bins which seems to be consistent with what we’ve seen and should give enough resolution in the bins to see structure visually. But let’s see what comes out of Sean’s analysis – if the early results are confirmed then we really do understand what’s going on and we can move forward with robust practical recommendations.
The other question is how many reps is the right number for using the KS test.
In terms of visualising this, does anyone have any feelings on whether “this histogram should be uniform” or “this line should be mostly in the circle” is better? (I prefer the latter, but I think in stochastic processes, so I’m probably not the right one to make that sort of call)
This is fantastic. At the risk of sounding like Andrew, this needs to be written up into a paper (or a case study). I want to know what to do to apply CGR going forward (someone please come up with a better name).
I don’t want to take credit away from Cook, but I’ve been using “Cocktail” and “Cockatoo” colloquially.
I’ve got many thoughts on this.
But broadly, after a decade, there’s probably a lot of new stuff we can say about CGR.
Hey all,
I wrote some code to generate some PDFs that are nice for visually comparing things; first scaling the number of bins linearly with n_eff and then with the square root of n_eff. All graphs are with 1e5 N_samp, but on each page I vary another parameter; first I show Dan’s RNG from above:
pnorm(rnorm(N_samp, sd=1 + runif(N_samp, -1/sqrt(n_eff), 1/sqrt(n_eff))))
Then on the next page with the same parameters and a discretized version:
round(dans.rng() * planck_length) / planck_length
Both of those with 26 n_eff and then the latter with planck_length of 1000. You can see the spike at 1 disappear with this discretization. The next 3 pages are with fixed n_eff and increasing planck_length; here I mostly noticed that increasing the planck_length gradually brought back the spike at 1 (and shortened the spike at 0) and that the histogram bin sizes vary with n_eff in the same way that they do in the other charts.
The next 3 pages vary n_eff; my synthesis here would be that sqrt(n_eff)*2 seems pretty much always safe (even if with some n_effs we could go higher).
w.r.t. squiggle + circle (KS test visualization) vs. plateau (uniform histogram) - As a novice I find the latter much easier to look for; I still don’t really have a good idea from the previous pages of tests how much of the line is fine to have outside the circle. On the other hand, the KS test number does seem pretty useful, especially for moving towards a more automated quantitative statistic. And I do think with all of my examples, the KS test had pretty low p-values for pretty off models (though maybe that deserves further study).
Excited to hear what you all think! Being able to reproduce this without using Stan at all has been immensely satisfying, even if I still haven’t figured out why the spike at 1 disappears and the spike at 0 gets larger with discretization.
code: https://gist.github.com/seantalts/c4a1de131f5dfc8f5b71c5c54b272617
<edit: Forgot the PDFs!>
linear_n_eff.pdf (501.2 KB)
sqrt_n_eff.pdf (50.5 KB)
2 Likes
When neff is small, it’s likely that the Monte Carlo draws underpresent tails. To see more details near 0 and 1, I propose to transform the non-binned values to z-scores and make a qq-plot. Here’s an example which if it would be plotted as a histogram of tail probabilities would not clearly show what happens in the tails. You could then also look what happens with binning.
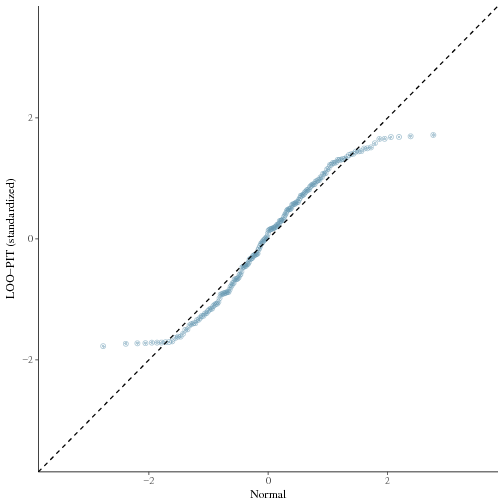
Aki
1 Like
A bit off topic, but I’ve always wondered why qqplots were drawn this way. Wouldn’t
it be beter to just plot (y - x) vs. x here? We’d get a lot more resolution.
Building off what Aki was saying, another option for a statistic would be the look at how far the empirical quantiles are from the some “target” distribution similar to a q-q plot. We could then use the maximum value of the vertical distance or some integrated value looking at the area (Probably with absolute value somewhere in there).
This would give a pretty interpretable statistic that is directly related to what we are trying to measure.
The most obvious choice for the target is a straight line.
Alternatively there is a kind of out there option of having the target being the best fit sigmoidish shape that correlated estimates outputs. This could allow us to control for a certain amount of autocorrelation upon the assumption that most of the errors we are trying to detect do not push the distribution to a more sigmoid shape.