Haha who knew c++ could be so wholesome
2 Likes
Uhm… I was curious how well these ideas can work and started some work on this. So I took reduce_sum and added the idea to have thread local copies of all the input operands in a “fresh” instance of an AD tape. The benefit of this is that we don’t any more copy the shared input operands per work chunk, but per thread we use. Hence, the slowdown due to more chunks will get less.
I took the brms threading vignette and ran it with the new stuff and with the current implementation.
Current slowdown:

Improved version:

So you see that we have less overhead due to more chunks.
Looking at the speedups we get, this is noticeable - I think - but still a bit noisy here.
Current speedups:

New speedups:

I think this shows that this approach has merit. I mean, we do reduce the overhead due to finer chunking - and that’s good news, since users would not anymore need to worry so much about the grainsize since it’s not such a problem anymore.
The code changes are actually relatively smallish:
It’s the branch feature-fast-parallel-ad
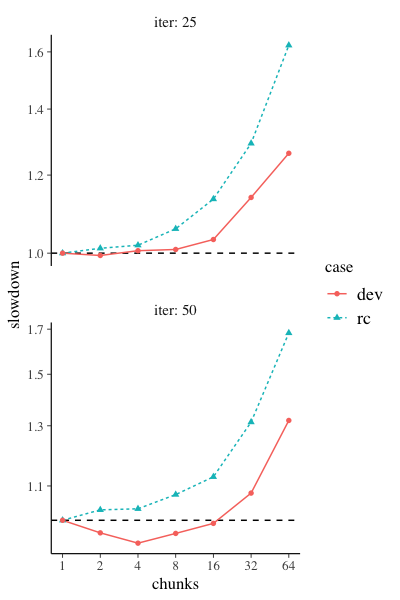
EDIT: the above speedup graphs used 25 iterations. This was seemingly too few. Here are the same results with 50 iterations.
Current version:

New version:

So it’s very clear the benefits we get from the new implementation… I want this… ;)
3 Likes
Plot the ratios of the time of the new code vs. the old code. This trying to figure out ratios between two plots is too hard lol. It does look like the new stuff is faster.
But yeah open a draft pull request so we can put comments on the code.
Are u not convinced? It’s so obvious to me. The 10% overhead mark is clearly crossed with 8 chunks for the old stuff. The new one does that between 16-32 chunks - so much later. The total runtime is also faster for the new code when you have up to 4 cores.
I will open a draft PR, sure.
I think I said my sentences in the wrong order or something and gave the wrong impression. I agree it looks faster in an important way, but I’m having trouble telling how much faster and I would like to know this (and how this changes with different grainsizes like you showed and also cores).
I read off the first one that the red line was like a little above 15 in the new code and a little above 19 in the old code, and I can kinda compute that ratio in my head (and it’s big), but then I have to do it everywhere else for all the other grainsizes yada yada and it’s hard. Anyway I wasn’t trying to be mean! My apologies
No worries. I did not perceive anything as mean. I was just surprised… and after all I am claiming something here to be better, but I was just lazy as I ran the report I already wrote. Though, I did make the scales the same, which it was not before.
Now, plotting ratios of old and new would result for the chunking slowdown in a ratio of a ratio… which is also odd, but maybe what we want.
1 Like
I personally like seeing the ratio. Though it’s less interpret-able relative to actual time I think it makes sense when we only care about comparing one thing vs another
Looks neat! Changes are tiny so I think this makes sense to add.
I’m still trying to think though how we would top this off by doing the reverse pass in parallel as well. It might be easier to talk about this in a draft PR.
@wds15 what I’m having trouble thinking about is how to take this piece from reduce_sum and do it in parallel
// initialize nested
const nested_rev_autodiff begin_nest;
// make local copies here...
// Perform calculation
var sub_sum_v = apply(
[&](auto&&... args) {
return ReduceFunction()(local_sub_slice, r.begin(), r.end() - 1,
msgs_, args...);
},
args_tuple_local);
// Accumulate value of reduce_sum
sum_ += sub_sum_v.val();
// This part needs to be in the reverse pass?
// Compute Jacobian
sub_sum_v.grad();
// Accumulate adjoints of sliced_arguments
accumulate_adjoints(sliced_partials_ +
r.begin() * num_vars_per_term_,
std::move(local_sub_slice));
// Accumulate adjoints of shared_arguments
apply(
[&](auto&&... args) {
accumulate_adjoints(args_adjoints_.data(),
std::forward<decltype(args)>(args)...);
},
args_tuple_local);
The first thing I’m thinking about is how do we call just the .chain() methods from sub_sum_v up to the first var allocated within this nested instance? Can we just keep track of the starting position of the nested autodiff in this instance of the chainable stack and then have a grad function for each chainable stack like
ChainableStack.instance_.grad(start_ptr, end_ptr);
The nested part of this makes my brain hurt haha
What I did so far is to only avoid the extra overhead we have for doing deep copies by work chunk. The recipe for that is doing deep copies of the shared stuff by thread only onto separate AD tapes. This lays the ground for doing the reverse sweep in parallel instead of doing many nested sweeps for each work item.
My suggestion is to include this stuff first and then extend it to handle full parallel forward & reverse sweeps.
Yes that totally makes sense to me
Great.
So… I still don’t like ratios of ratios as these are too misleading to me. Maybe that’s only me, but here is a way of plotting the info in overlaid form which makes it clear as well:
Runtimes of the chunking experiment:

Slowdown of chunking experiment (relative to 1 core within each curve):
Speedup comparison:

“dev” is the new stuff and “rc” the current 2.25.0 rc.
3 Likes
Looks good!
The ratios plotted here are runtime_parallel_code_A / runtime_serial vs runtime_parallel_code_B / runtime_serial. Those are good for understanding what our parallel efficiency is (and were good when we had no other parallel code to compare to).
Separately we could look at runtime_parallel_code_A / runtime_parallel_code_B to know exactly how much faster new parallel is vs. old parallel (which is relevant now since we’re replacing one parallel code with another).
Sure. I did plot the runtime for version A & B on top of each other in the last “speedup comparison” (using different colours). You see that the new code is quite a bit better for the smaller grain sizes while the old code is seemingly a bit faster for a large grainsize, but not much. A ratio should tell the same story.
I’m cool with the graphs you made. The original ones were a bit hard to compare but having stuff side by side makes sense.
What are iterations in the graph though? Like literally running 25 iterations of a model?
It’s 50 iterations of the mixed poisson model used in the brms threading vignette.
How should we proceed with the draft pr? Do we need a design doc here or is the change modest in your view?
I’m fine with the heuristic of iters here though I worry that speed will change a lot through warmup. In the future it may be better to just make its own perf test with gtest
I think it’s a modest change and doesn’t need a design doc itself. Though personally I’d appreciate a rough sketch of how you want to use this to move to parallel in reverse. Nothing too technical needed just a layout. Looking it over it wasn’t clear to me how this would help with that (and so “reverse is a whole separate thing” is also a fine answer)
How come? This is all about how many leapfrog steps are done.
Great. I will add some tests then and let’s wait for @bbbales2 to have a look.
The plan is as follows: Right now we do nested AD for every work chunk and return things as precomputed_gradient. When doing the reverse sweep in parallel as well things will run as
- Run the parallel forward sweep where we merely record onto the scoped chainable stacks the AD tape, but do not run the nested stuff. Thus, we endup with one scoped chainable stack per thread once the forward pass exits reduce_sum.
- reduce_sum returns a “super” vari which stores internally the different scoped chainable stacks.
- On the reverse pass this “super” vari will run grad in parallel on the different scoped chainable stacks.
Right now I don’t think this will be hard to do… until I hit some roadblock…
Per-gradient timings
Argh. My git fu is bad… I messed up the branches a bit… ok… so we have now two branches:
-
feature-fast-parallel-ad-2contains the step 1 changes with the scoped chainable stack which does speedup a lot alreadyreduce_sumand we should review and merge this first. Draft PR. -
feature-fast-parallel-adnow contains an already further developed version of the above which runs the reverse sweep over the parallel region. So this version avoids the used of nested AD and instead leaves the child scopes intact. The reverse sweep is not run in parallel yet, but that’s not hard to add. However, I am not yet entirely happy with the structure of it, but the idea is there. Draft PR is here.
So sorry for the mess with the git history. I still think we should merge feature-fast-parallel-ad-2 first and then work on the more complicated thing.
1 Like
You’ve made a lot of progress while I was away, I should take breaks more often! This is great, I’ll catch up on the code/PRs this week and will have c++ time next week to contribute.
Really looking forward to this!
1 Like