Hi, relatively new to stan and rstanarm so not always sure what I’m doing, and have run across a problem now I don’t understand at all.
Basically I have a dataset of proportions (hours/maximum hours) measured weekly over a 23 week period. After finding out about beta regression I figured that would be a proper way to model it. I roughly know what the progression of my response variable would be under normal conditions, and have made an ‘example data set’ based on this. I want to set the priors in such a way that that shape is assumed.
I tried to do this by modelling the ideal model using stan_betareg with weekly informative priors and then using the parameters from this model as priors (the model was a good fit to the data).
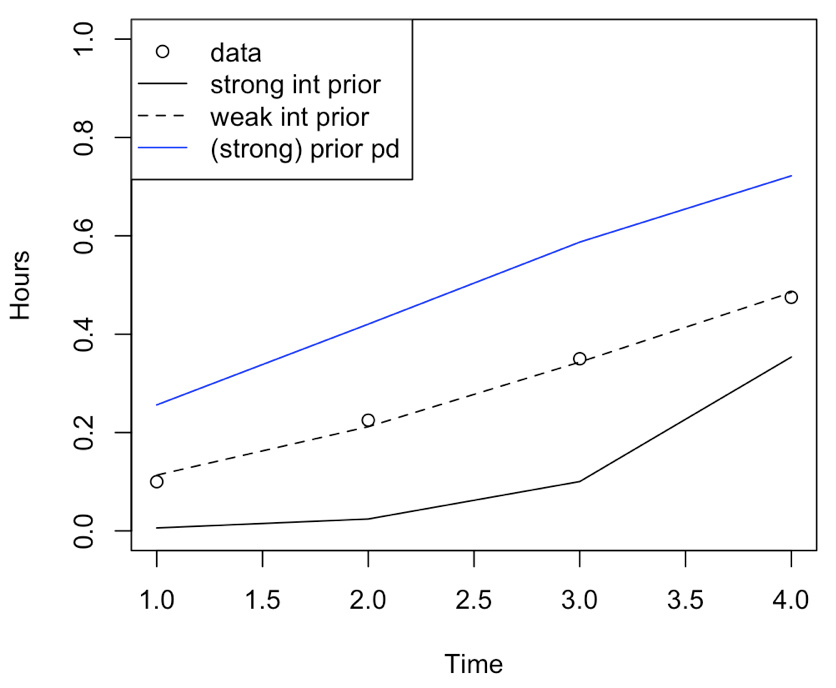
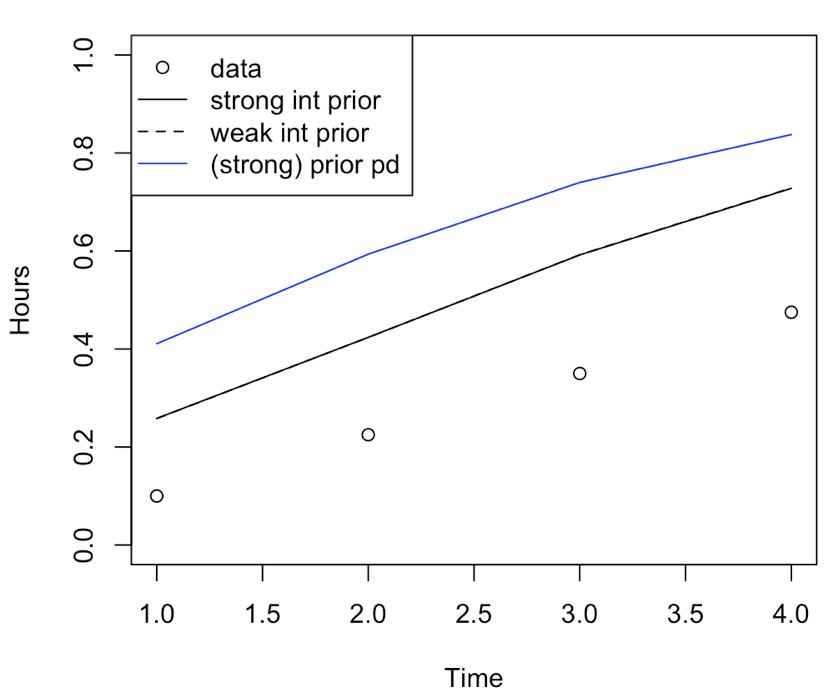
The idea is to run a weekly model and predict what the values will be for the rest of the 23 week period, initially assuming it will be similar to the ideal set. However, when modelling e.g. over just the first 4 weeks of the example data set itself with the priors, it seems that the intercept estimate is not affected by the intercept prior at all, and the estimates are way off.
I feel like I must be doing something fundamentally wrong here, but I’m not sure what. Any help would be greatly appreciated.
dat <- as.data.frame(cbind(c(1:23),c((1:23)^2),
c(0.1,0.225,0.35,0.475,0.6,0.7,0.8,0.85,0.9,0.9,0.9,0.9,0.9,0.885,0.87,0.825,0.78,0.66,0.54,0.43,0.32,0.21,0.1))
)
colnames(dat)<-c(“Week”,“Week2”,“Hours”)
m0 <- stan_betareg(Hours ~ Week+Week2,
prior=normal(),
prior_intercept=normal(),
QR=T, data=dat
)
summary(m0,digits=3)
m1 <- stan_betareg(Hours ~ Week+Week2,
prior=normal(location=c(0.85,-0.036),scale=c(0.1,0.05)),
prior_intercept=normal(-2.9,0.001),
prior_phi=normal(400,10), data=dat[1:4,]
)
m2 <- stan_betareg(Hours ~ Week+Week2,
prior=normal(location=c(0.85,-0.036),scale=c(0.1,0.1)),
prior_intercept=normal(),
prior_phi=normal(400,10), data=dat[1:4,]
)
coef(m1) #intercept 1.87
coef(m2) #intercept 1.87