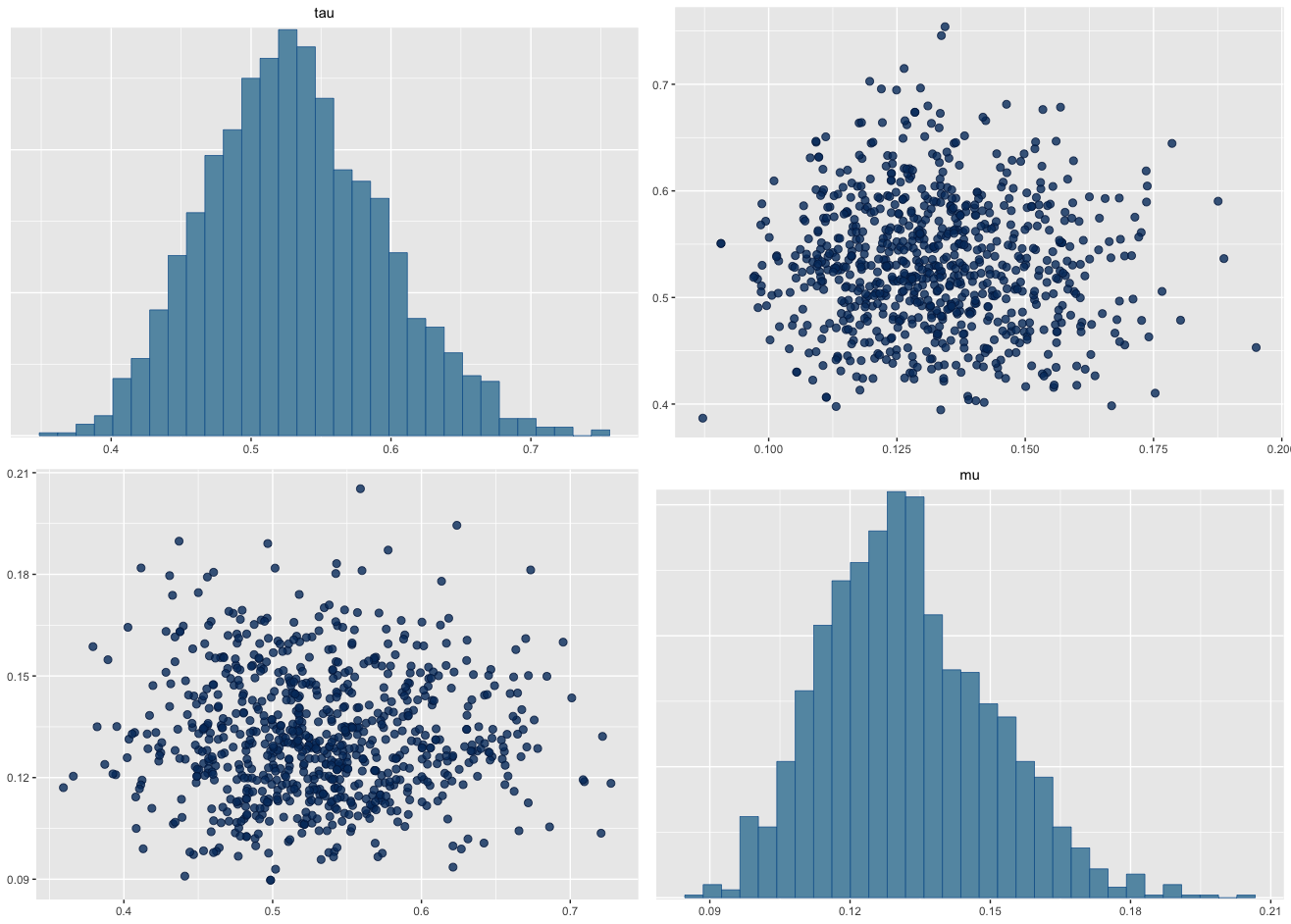
I have two concerns:
-
When reporting the estimates of rate and shape, both show similar pattern, which is not very informative. I would prefer some other parametrization which provides orthogonal estimates.
-
If I recall correctly, the stan prior recommendation list recommends independent priors. Sure, I can set up a gamma model with independent rate and shape priors, but the data then introduce the dependence pattern. Is that not an issue for the sampler? Or, does the sampler use some different implicit parametrization under the hood?
In any case, all of the popular parameter transformations (log rate/shape, scale, mean, mode, std) do not manage to remove the dependence.
What works rather well is parametrization in terms of log scale and log of the geometric mean, but it’s difficult to use this to construct priors because I need to compute inverse digamma function.
For reference here is the model code I am primarily using:
data {
int<lower=0> N;
vector<lower=0>[N] y;
}parameters {
real b;
real k;
}model {
y~gamma(exp(k),exp(b));
}
I’ve tried different priors and I’ve also run a fake data simulation with identical results.